|
基本信息
本文参考 LangChain 的 LanceMartine和 b 站 upNong_BIN 的RAG 总结和分析
slide: LangChain LanceMartin slide: https://docs.google.com/presentation/d/1mJUiPBdtf58NfuSEQ7pVSEQ2Oqmek7F1i4gBwR6JDss/edit?pli=1#slide=id.g26c0cb8dc66_0_57 up: Nong_BIN 视频链接:https://www.bilibili.com/video/BV1vD421T7aR/?spm_id_from=333.788&vd_source=e333e1088bd7a8147eefd76068b10bc3
Context windows are getting larger

Do we need RAG anymore?
观点提炼:

RAG: reasoning & retrieval on multiple chunks of information
RAG 的基础流程:

Reference:
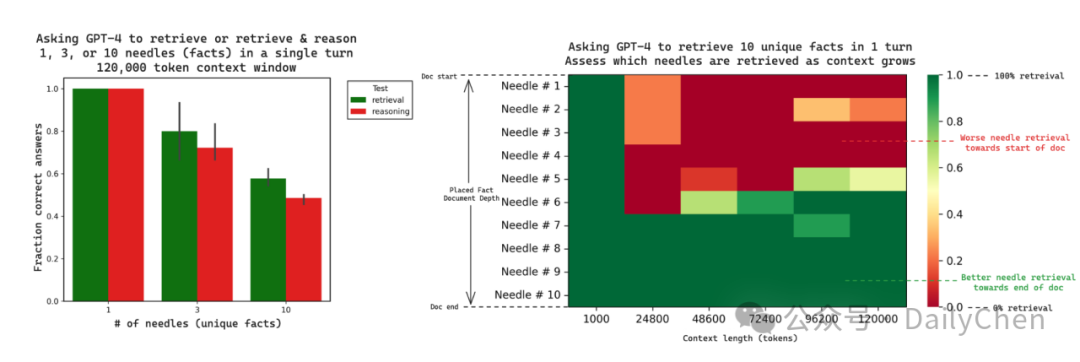
Needle In A Haystack: test reasoning & retrieval in long context LLMs
检测 LLM 对长文本中的事实检索能力
提问:制作一个完美的披萨的秘密成分是什么 提问+修改后的 essays 组成 Prompt LLM 生成 Answer 与答案对比评估 找到几个秘密成分就得几分

实验结果:
不管是 retrieve还是 reason 任务,随着隐含事实(needles)数量增多,GPT4 找到的数量越少 随着 Context 越长,检索成功的 needle 数量越少 在上下文长度固定的情况下,越接近 Prompt (or Document)末尾的 needle 越容易被检索到,越接近 Prompt开头的Needle 越难找到
Reference:
https://github.com/gkamradt/LLMTest_NeedleInAHaystack https://youtu.be/UlmyyYQGhzc https://blog.langchain.dev/multi-needle-in-a-haystack/
Challenge may be recency bias in LLMs
LLM 会对recent token 记忆更加牢固,但也许相关度更高的信息,或者更重要的信息,会出现在较前面的位置。
启发:RAG 检索结果在并入 LLM 的时候,可以按照倒序排列,相似度最高的放最后,最低的放第一个。

Reference:
RAG will change
RAG today focused on precise retrieval of relevant doc chunks
精确检索:针对long context LLM 对远端 token 记忆问题
chunks 形式:针对 Context 越长,检索成功的 needle 数量越少的问题

Reference:
Need to balance system complexity vs latency & token usage
检索过于精确可能导致:
过多的工程设计 高复杂度 低召回率(精确度可能很高,召回率低) 召回chunk 的个数需要小心确定
另一个极端,所有 doc 都丢给 LLM可能导致:
高 token 消耗 高延迟 无法监控检索过程 安全隐患
所以我们需要折中选择

Some idea..
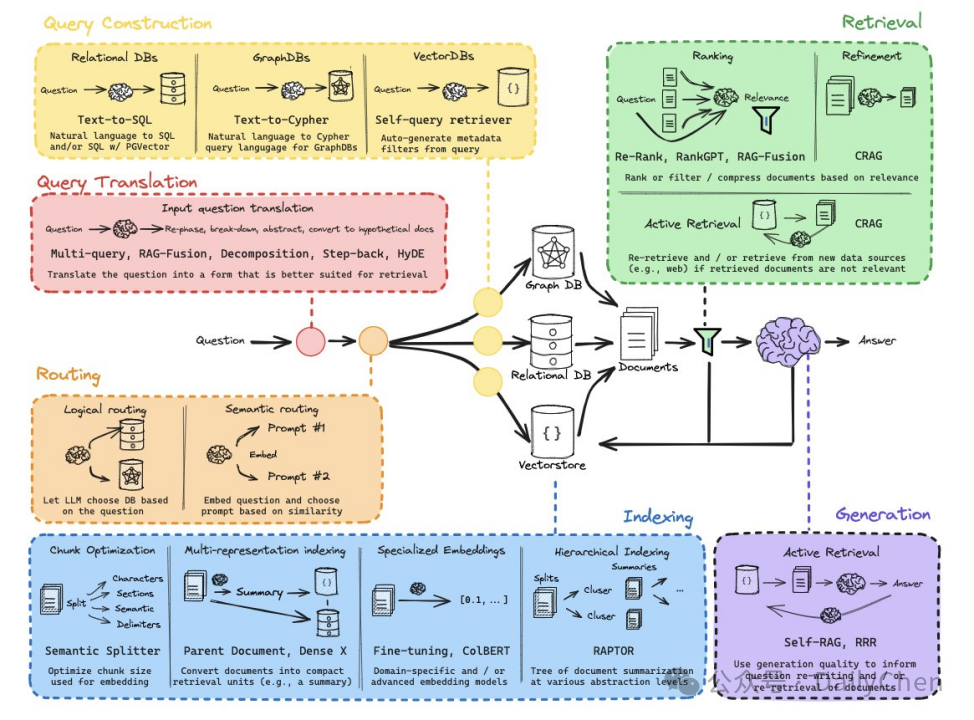
Query analysis: Connect questions to the right document
Query Analysis:可以把问题,重写、拆分、提取摘要 Routing:导向正确的 DB Query Construction: 构成 SQL,Cypher、VectorDBs

Reference:
Indexing:
如何保证检索到的 chunk 是足够有质量的?
如果直接把 full doc全部向量化,然后和 question 的 vector 去做相似度匹配,这样会出现两个问题:
如何保证你的 chunk 是完整语义文本段落? 有些 doc 内容并不精炼,一个 chunk 可能与 question 相似度很高,但并没有降到回答问题的关键所在,回答该问题的答案有可能在在一个 chunk,如何保证能够获取到能够回答问题的关键信息?
Use representations to simplify document retrieval
利用 LLM对 full doc 进行总结,获取 Summary,讲 Summary 进行 Embedding 得到向量库(这里的 Summary 和部分文章(也许是一个章节)是一一对应关系) 向量库相似度检索,检索到高相似度的 Summary,去找到原本的原文部分,提取出来 最后就会得到相关的 Full doc

Reference:
https://arxiv.org/pdf/2312.06648.pdf https://blog.langchain.dev/semi-structured-multi-modal-rag/ https://python.langchain.com/docs/modules/data_connection/retrievers/parent_document_retriever
Use trees to consolidate info across many documents
将每个文档视为叶子节点,对这些节点进行 Embedding 和聚类
每一簇写一个 Summary,形成新一层的节点,父节点
对这一层的节点继续聚类,知道最后只剩一个节点为止
检索时候,对所有节点都做相似度检索
所以检索出来的可能会有 Summary 的文章,也可能就是原文,这样做的好处是对具体的问题或者宏观的问题都有所帮助

Reference:
Reasoning
Use reasoning / self-reflection around RAG
检索相关的文章,让LLM 自行打分
选择相关性高的生成结果
对结果进行判断:是否产生幻觉、是否回答了问题

类似的还有:
LLM 自己对于检索结果相关性进行打分,只保留打分高的文章,反复重复
最后只把问题和保留下的高分文章结合成 Prompt

还有:
这个 workflow 就比较简单,就是找到的内容如果不是很相关,那就重写 query 然后去 web 搜索

Reference:
https://arxiv.org/abs/2310.11511 https://www.youtube.com/watch?v=E2shqsYwxck https://github.com/langchain-ai/langgraph/blob/main/examples/rag/langgraph_self_rag.ipynb https://arxiv.org/abs/2401.15884 https://github.com/langchain-ai/langgraph/blob/main/examples/rag/langgraph_crag.ipynb
Overall picture: Doc-centric, no splits or compression, reason pre/post retrieval
主要观点:
以文本为中心,不去分割、压缩内容
可以在检索前推理,也可以在检索后推理(自我矫正部分)
Reference:
| 









