作者将该大语言模型系列命名为 Neo 和 Matrix,以向电影《黑客帝国》致敬!
亮点:
4.7T tokens 的中文+英文清洗后语料 扫描PDF 转 Markdown 的工作流,可以识别图片、表格和公式!!! 中英文的预训练数据处理 Pipeline,拿来即用~ 最终的 7B 预训练模型以及预训练阶段、Decay阶段、scalinglaw测试中全部的 ckpt 方便进行研究。
开源链接:
模型地址:https://huggingface.co/collections/m-a-p/neo-models-66395a5c9662bb58d5d70f04 Github:https://github.com/multimodal-art-projection/MAP-NEO 数据集:https://huggingface.co/datasets/m-a-p/Matrix
一、简要
Neo 是第一个完全透明的双语大型语言模型,具有完全开源的预训练语料库、数据处理管道、由 Megatron-LM 修改的训练框架、中间 ckpt 和用于研究缩放规律的相对较小的 ckpt。Matrix 是一个 4.7 万亿个 token 的直接可采用预训练语料库,它经过了严格的启发式规则过滤和重复数据删除。
二、Neo的指标表现
Neo 在推理、数学、代码和中文指标上的表现明显更好,如下所示:
 Neo的主要指标表现: Neo的主要指标表现: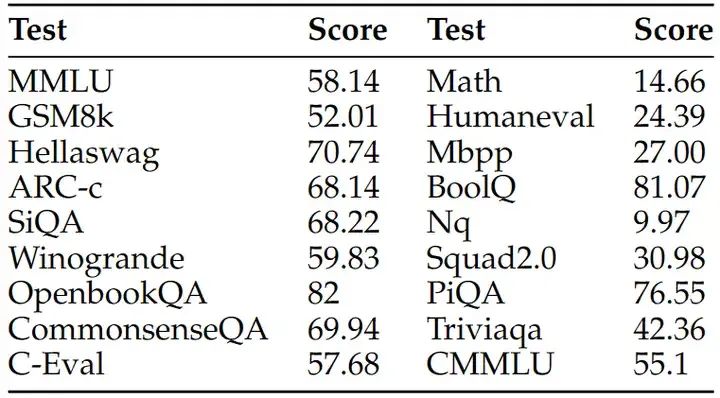 三、数据处理pipeline
1.英文过滤管道

2. 中文过滤管道
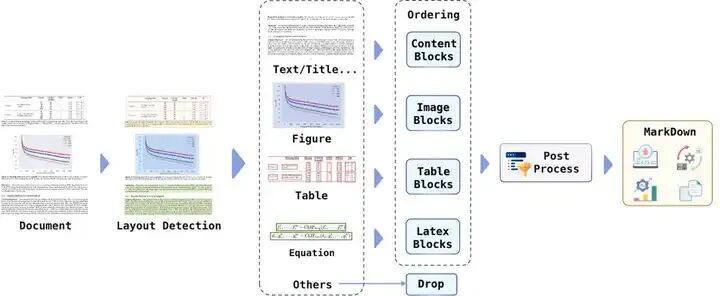
 3. 文档转换管道
4. 复现 deepseek-math 管道
受到从 DeepSeekMath 收集数学数据的过程的启发,我们设计了一个迭代管道,使用 Common Crawl 从特定领域获取大规模、高质量的数据。这些字段包括 math、K12 和 wiki。
DeepSeekMath:https://arxiv.org/abs/2402.03300
| 









