(1) 稀疏的MoE结构
先前的主流做法[60]是用稀疏门控的
专家混合块替换密集的MLP块。给定输入X∈RN×Cin
和一个MLP块,
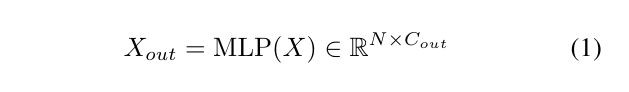
为了扩展具有多个MLP块的模型,稀疏的MoE块包括
一个路由网络,以从总共S个专家中选择前K个专家。
该路由网络具有一个线性层,根据输入X计算归一化
权重矩阵以进行投票,结果为
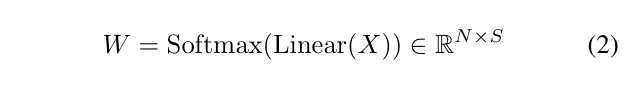
对于每个标记,基于W选择前K个专家,并使用重
新归一化的权重WK∈RN× K进行计算
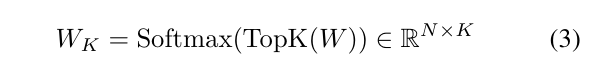
每个选定的专家由一个MLP块表示,并通过重新加权
求和获得最终输出。
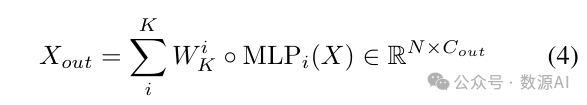
输出Xout 保持与单个密集MLP块输出相同的维度。
(2) 稀疏升级
从头开始训练基于MoE的设计可能不稳定且
成本高昂。稀疏升级[33]通过从预训练的密集检查点
中的相应MLP块初始化每个MoE块中的专家来解决
这一挑战。这种初始化方法为训练基于MoE的模型提
供了更好的起点,并降低了与从头开始训练相比的训
练成本。
(1) MLP连接器中的稀疏MoE
MLP连接器将视觉标记转
换为词嵌入空间,对齐视觉和文本标记之间的维度。
用于视觉-语言连接器的有效架构是一个包含两个线性
层的MLP块[46]。我们从单个MLP块开始,并将其
替换为一个Top-K稀疏MoE块,其中包括一个Top-K
路由器和一组专家,用于将视觉标记投影到词嵌入空
间中。
(2)视觉编码器中的稀疏MoE
视觉编码器将图像特征提
取为视觉标记序列,用于在LLM中进行推理。CLIP
[57] 是最受欢迎的预训练视觉编码器之一,用于多模
态LLM,因为它在大规模图像-文本对上进行了预训
练,适用于处理图像以供多模态使用。CLIP的视觉编
码部分是一个ViT[15]模型,其中在transformer 编码
器中有连续的MLP块。我们用一个Top-K稀疏MoE
块替换每个MLP块,保留MoE块输出旁边的跳跃连接。
(3)LLM中的稀疏MoE
在使用MoE进行LLM时,我们
将协同升级的LLM与基于预训练MoE的LLM进行比
较。我们从Mistral-7B开始,升级后的Mistral-7B-MoE
在某些基准测试中略优于Mistral-7B。然而,考虑到来
自Mistral-7B 的升级专家的受限知识库,我们将其与
具有多样化知识库的预训练专家的预训练Mixtral8x7B
进行比较。实验结果表明,预训练Mixtral8x7B明显优
于Mistral-7B-MoE。因此,LLM 未与CLIP和MLP连
接器协同升级,因为它带来了微小的改进,但增加了
大量的额外参数。
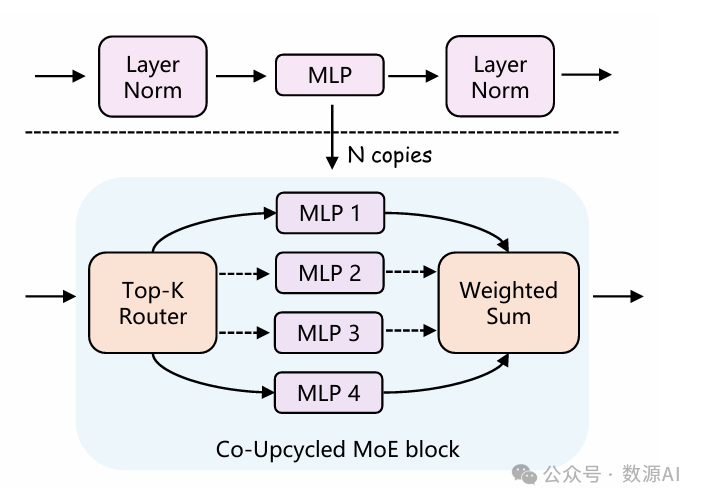
(1)共同升级再利用MoE模块
我们从头开始训练添加的
MoE模块,同时模型正在努力收敛。尝试通过降低学
习率来解决这个问题的做法与基准相比效果更差。因
此,我们采用了一种共同升级再利用的方法,将每个
集成稀疏门MoE模块的模块与预训练的MLP替换相
应的MLP模块,如图3所示。这种策略始终提高了训
练稳定性和模型性能。
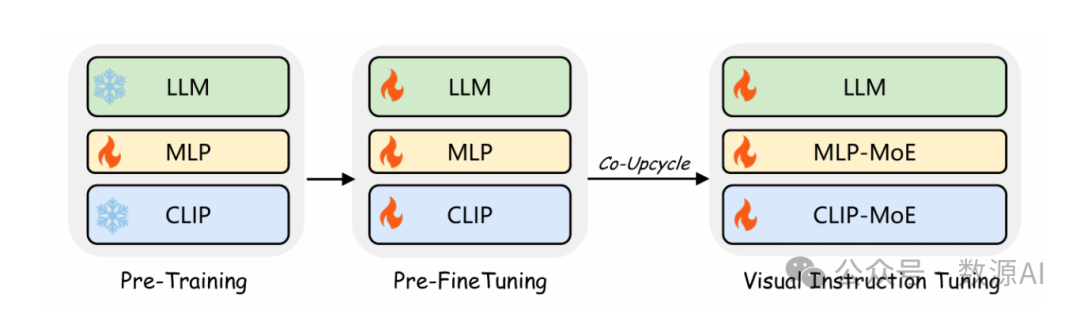
(2)三阶段训练
为了进一步增强训练稳定性,我们为
CuMo模型采用了三阶段训练策略,如图4所示。在
第一阶段,我们仅对MLP连接器进行预训练,考虑到
视觉编码器和LLM已经在大规模数据上进行了预训
练。在第二个预微调阶段,我们使用高质量的字幕数
据训练所有参数,以在引入MoE模块的后续阶段之前
预热整个模型。第三阶段涉及视觉指导微调,其中多
模态LLM通过再利用的MoE模块进行扩展,并在视
觉指导微调数据上进行训练。
(3)损失函数
为了在每个MoE模块中维持专家之间的负载
平衡,我们采用基于语言建模交叉熵损失的辅助损失。
辅助损失包括负载平衡损失和路由器z-损失[77]。因
此,总损失为
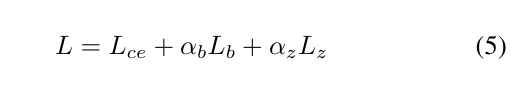
在这里,Lce代表语言建模损失,计算下一个标记预
测的交叉熵。αb和αz分别表示加载平衡损失Lb和路由
器z损失Lz的系数,设置为0.1和0.01,在所有实验中保
持不变。这些辅助损失,在第4节中简称为bzloss,分
别应用于MLP连接器、视觉编码器和LLM,以简化处
理。










