|
ingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;font-size: 1.2em;display: table;border-bottom: 1px solid rgb(248, 57, 41);">背景ingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;font-size: 15px;letter-spacing: 0.1em;">对业务数据库中的表实现问答。输入是用户的问题,输出是该问题的答案。ingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;font-size: 15px;letter-spacing: 0.1em;">这是很典型的Text2SQL的应用场景了,为了实现这一需求,很容想到的是把创建的表和表的描述都放进prompt里,让LLM去根据表的结构生成SQL语句,再利用工具去执行SQL语句,拿到查询结果后,再丢给LLM,让LLM根据给定的内容回答问题。我一开始也是这么想的,但是,当你的业务表非常多的时候,比如有上千个,你应该选择哪个表或者哪些表去给到LLM呢?根据问题去检索可能会用到的表是比较容易想到的一种方式。ingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;font-size: 15px;letter-spacing: 0.1em;">于是,我带着我的疑惑,去调研了目前一些比较火的text2sql的框架。惊奇地发现,他们确实也是这样做的。比较典型的就是vanna[1]了ingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;font-size: 15px;letter-spacing: 0.1em;">
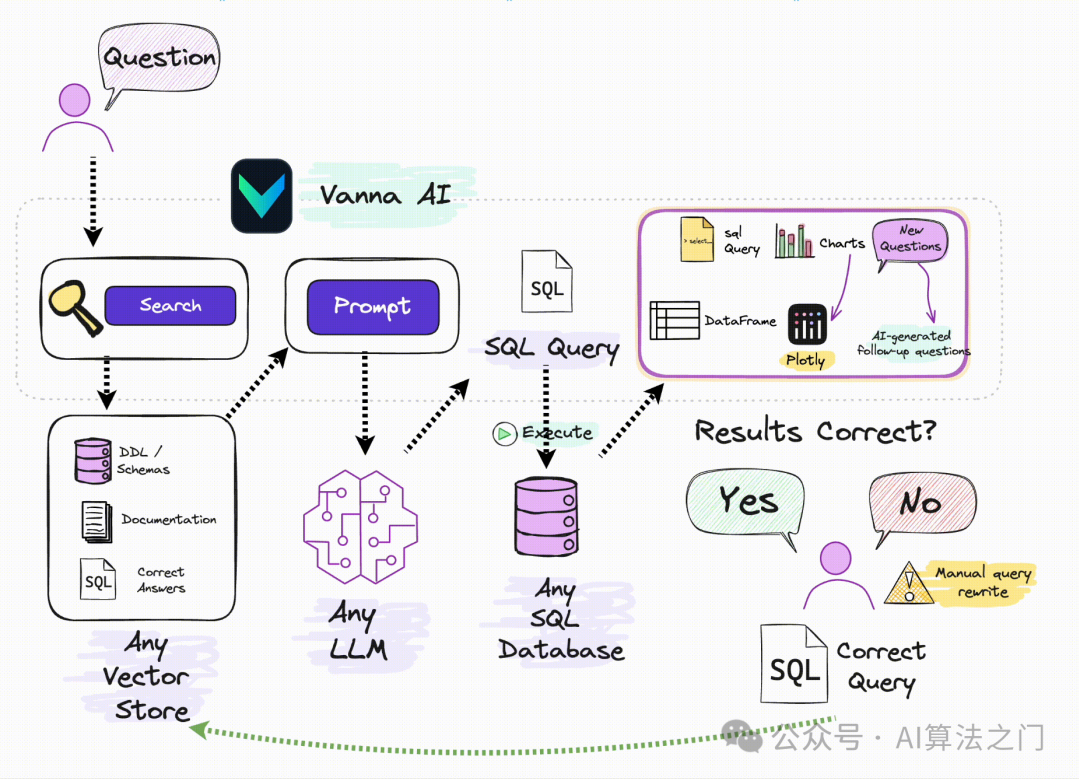
ingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;font-size: 1.2em;display: table;border-bottom: 1px solid rgb(248, 57, 41);">核心策略ingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;font-size: 15px;letter-spacing: 0.1em;">从上图可以看出,Vanna实际上分了三个部分做RAG:ingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;font-size: 15px;list-style: circle;">•DDL 语句检索:对建表的语句做语义检索,建表时的表描述和字段注释•文档检索:包括对一些专有名字的解释,以及拼接表的每个字段组成的字符串等一些其他相关文档•Query 与 对应的SQL检索:用户的问题与对应的SQL语句ingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;font-size: 1.2em;display: table;border-bottom: 1px solid rgb(248, 57, 41);">关键步骤ingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;font-size: 15px;letter-spacing: 0.1em;">DDL语句向量化:对于每一个建表语句,进行embedding,表和字段的描述,对结果的影响非常大,如果只有简单的建表语句,效果如何完全取决于大模型能不能猜对你这个表是干嘛的。文档向量化:这里可以将数据库中的所有数据,按一定的规则拼接成自然语言,然后向量化。还可以将一些LLM比较难理解的专有名词的解释向量化,在有相关的Query进来时,专有名词的解释也会被召回,一起放进Prompt中,帮助LLM理解Query Query与SQL语句向量化:在Vanna中,这一步的做法是将Query与SQL dumps成一个字符串,一起向量化。 效果Vanna对比过不同策略加入后对最终效果的影响: 使用SQL fewshot从下表可以看出,仅仅给出表的结构,LLM生成正确的SQL还是比较困难的,但是给了few shot后,效果立马飙升。 
使用上下文相关fewshot
 可以看到,使用上下文相关的fewshot,效果又提升了一小截。上下文相关的fewshot就是那些检索出来的相关的DDL、文档、以及Query-SQL对。
一些优化既然Vanna也是RAG,那么RAG的那些奇技淫巧,便可以在Text2SQL也派上用场了。咱们可以看看Vanna相比那些奇技淫巧少了哪些部分,给它安排上就完事了,核心目标就是为了提升检索相关度。 通过阅读Vanna的源码,发现Vanna只做了粗排,那么咱们就给它安排上重排,这不就好起来了么,简单粗暴。 class MyChromaDB(ChromaDB_VectorStore):def __init__(self, config=None):super().__init__(config)
self.rerank_model = CrossEncoder('bge-reranker-large',max_length=512)
def get_similar_question_sql(self, question: str, **kwargs) -> list:documents = ChromaDB_VectorStore._extract_documents(self.sql_collection.query(query_texts=[question],n_results=self.n_results_sql,))if documents != []:scores = self.rerank_model.predict([(question, doc["question"]) for doc in documents])combined = list(zip(documents, scores))sorted_combined = sorted(combined, key=lambda x: x[1], reverse=True)documents = [item[0] for item in sorted_combined]return documents
def get_related_ddl(self, question: str, **kwargs) -> list:documents = ChromaDB_VectorStore._extract_documents(self.ddl_collection.query(query_texts=[question],n_results=self.n_results_ddl,))if documents != []:scores = self.rerank_model.predict([(question, doc) for doc in documents])combined = list(zip(documents, scores))sorted_combined = sorted(combined, key=lambda x: x[1], reverse=True)documents = [item[0] for item in sorted_combined]return documents
def get_related_documentation(self, question: str, **kwargs) -> list:documents = ChromaDB_VectorStore._extract_documents(self.documentation_collection.query(query_texts=[question],n_results=self.n_results_documentation,))if documents != []:scores = self.rerank_model.predict([(question, doc) for doc in documents])combined = list(zip(documents, scores))sorted_combined = sorted(combined, key=lambda x: x[1], reverse=True)documents = [item[0] for item in sorted_combined]return documents
对了,BCE的模型在Text2SQL场景的效果不咋地,不建议使用。我这里使用的是BGE,有条件的同学甚至可以微调一下。 我这里没有对Query-SQL对中的SQL做检索,主要是考虑到用户的Query与SQL语句的相关性并不大,当然,获取数据这里修改成只计算Query的相关性时,你还需要对Query-SQL的向量化部分进行相应修改,应改成只对Query embedding。
|










