论文题目:LongRoPE:ExtendingLLMContextWindowBeyond2MillionTokens论文链接:https://arxiv.org/pdf/2402.13753.pdfGithub:https://github.com/microsoft/LongRoPE 论文介绍了一种名为LongRoPE的方法,它首次将预训练的大型语言模型(LLMs)的上下文窗口扩展到2048k个标记,同时在保持原始短上下文窗口性能的同时,仅需要1k步的微调。这一成就是通过三个关键创新实现的: - 通过有效搜索识别和利用位置插值中的两种非均匀性,包括RoPE维度和标记位置的变化,为微调提供了更好的初始化,并在非微调情况下实现了8倍的扩展。
- 引入了一种渐进式扩展策略,首先对长度为256k的LLM进行微调,然后在微调后的扩展LLM上进行第二次位置插值,以实现2048k的上下文窗口。
- 在8k长度上重新调整LongRoPE,以恢复短上下文窗口的性能。在扩展到非常长的上下文窗口后,可能会发现模型在原始较短的上下文窗口内的性能有所下降。为了解决这个问题,可以对扩展后的模型进行额外的调整,以恢复在较短上下文窗口内的性能。这可能涉及到对位置嵌入(RoPE)的重缩放因子进行优化,以适应不同的上下文长度。
一个示例展示在不同插值方法下的RoPE嵌入。上图:直接外推下的RoPE。中图:线性位置插值下的重新缩放RoPE。下图:LongRoPE充分利用了识别出的两种非均匀性,导致在不同标记位置的RoPE维度上进行变化的插值和外推。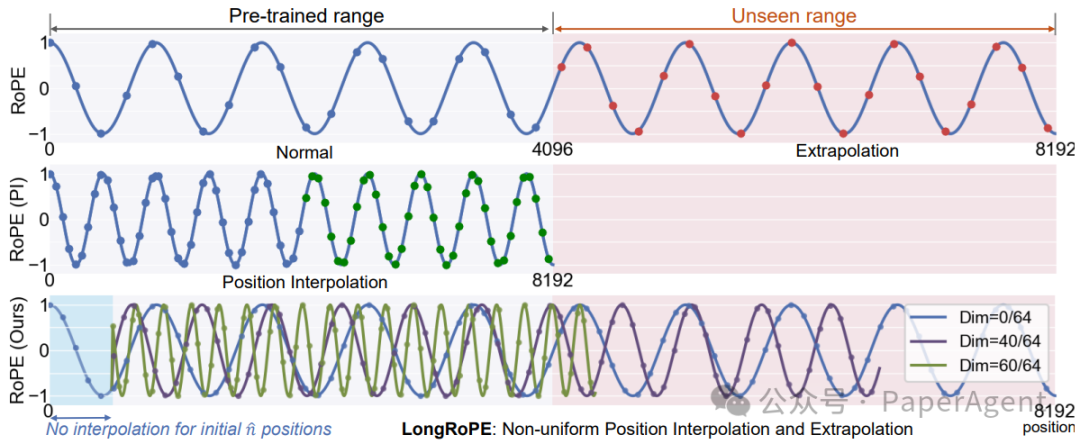
在LLaMA2和Mistral模型上进行的广泛实验表明,该方法在各种长上下文任务中都非常有效。通过LongRoPE扩展的模型保留了原始架构,并对位置嵌入进行了轻微修改,可以重用大多数现有的优化。LongRoPE在256k上下文长度内也超越了其它不同位置插值方法(困惑度)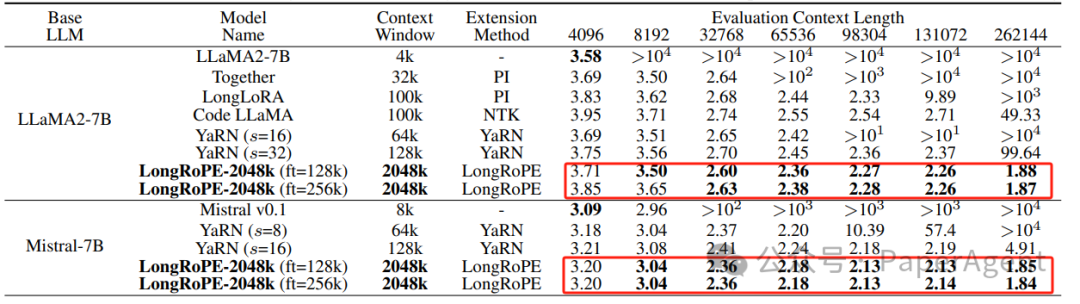
LongRoPE无需额外的微调,训练时的上下文窗口大小为 128k 和 256k,有效地扩展到了极长的 2048k 上下文大小 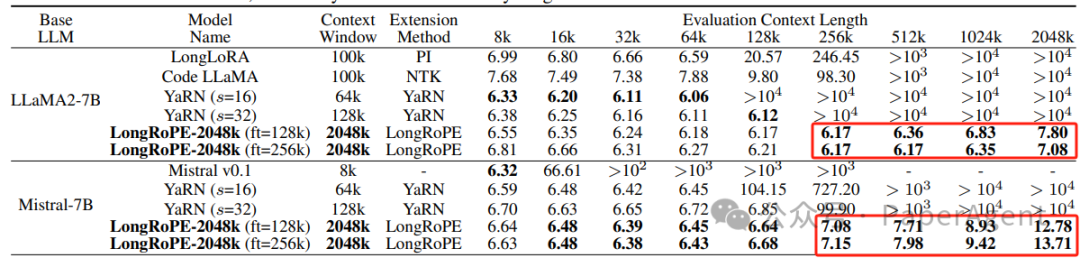
论文的实验部分也展示了LongRoPE在长文档上的低困惑度(perplexity)表现,以及在标准基准测试中的可比准确性。此外,LongRoPE在长上下文任务中,如密钥检索,也表现出色。在 Hugging Face Open LLM 基准测试中,长上下文LLMs与原始 LLaMA2 和 Mistral 的比较。 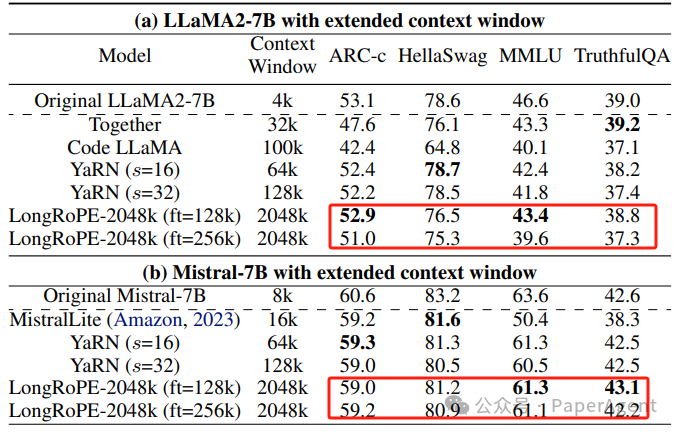
长上下文LLMs的密钥检索准确率。展示了LongRoPE在从数百万级别的标记池中准确检索密钥的显著能力。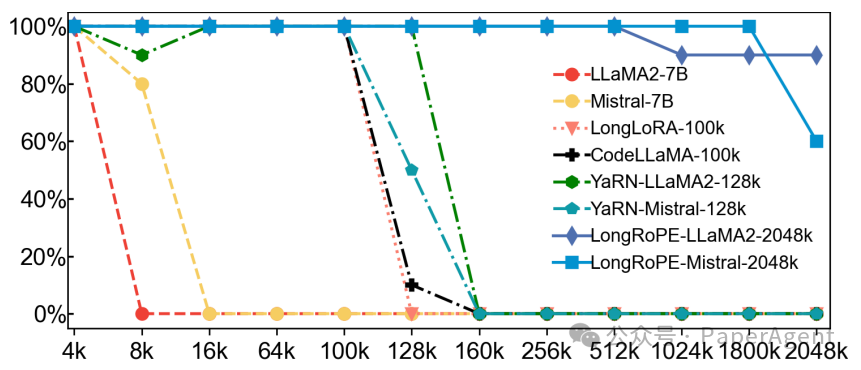
| 









