Skywork-13B-Base模型在3.2万亿个高质量多语言(主要是中文和英文)和代码数据上预训练,它在多种评测和各种基准测试上都展现了同等规模模型的最佳效果,包括Base、Chat、Math、MM模型及其量化版,支持用户在消费级显卡进行部署和推理。
Hello,大家好啊,我是Aitrainee,今天聊聊国产开源大模型:Skywork-13B。去年 7 月,Meta 发布了 LLaMA2,以其强大的性能和免费商用的优势,迅速赢得了开发者和企业的喜爱。各个版本的 LLaMA2 微调成果不断涌现,让大模型领域的竞争局势快速变化。很多人认为,这波开源攻势会削弱那些闭源大模型厂商的“护城河”,让中小企业和开发者有了更经济实惠的选择。不仅如此,国产大模型的开源力量也在加速追赶。然后,大模型开源仍面临三大挑战:首先,中文数据的稀缺和珍贵使得训练高质量模型变得困难;其次,模型训练的细节往往不公开,限制了开发者对模型的深度理解和优化;最后,模型开源在商用方面面临诸多限制,使得企业在实际应用中遇到许多障碍。而前不久,昆仑万维推出了重磅开源项目:天工 Skywork-13B 系列。为什么说重磅呢?因为 Skywork-13B 在多个基准测试(如 C-Eval,MMLU)中全面超越了 LLaMA2-13B。这次开源不仅包括 Skywork-13B-Base 模型、Skywork-13B-Math 模型,还有它们的量化版模型。更厉害的是,昆仑万维还开放了一个600GB、150B Tokens的高质量中文语料数据集「Skypile/Chinese-Web-Text-150B」,而且全面开放商用,开发者无需申请,零门槛就能用上。
▲Model Scope •Skywork-13B下载地址(ModelScope):https://modelscope.cn/organization/skywork•Skywork-13B下载地址(Github):https://github.com/SkyworkAI/Skywork•技术报告:https://arxiv.org/pdf/2310.19341.pdf 模型结构Llama模型有三个主要特点:首先,它使用RMSNorm代替传统的Layernorm,以保持训练的稳定性;其次,它使用SwiGLU激活函数而不是传统的ReLU;最后,它使用相对位置编码(RoPE等)而不是传统的绝对位置编码。实验结果表明,与GPT模型相比,Llama模型不仅训练得更快,而且效果也更好。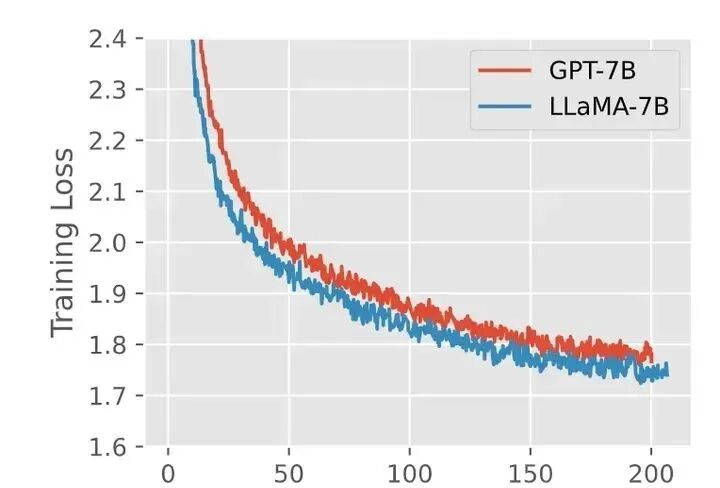 ▲GPT-3结构和Llama结构训练对比(摘自知乎盐海) 下面对相关名词作通俗化的解释:
相对位置编码(Rotary Position Embedding):这是一种用于编码输入序列中位置信息的方法。想象一下,你在看一本书,每页的页码告诉你这个字在哪里。RoPE就像在模型里给每个字加了页码,让它知道每个字在什么位置。 均方根归一化(Root Mean Square Normalization):这是一种归一化技术,用于调整神经网络层的输出。想象你在做一道菜,所有的配料都需要精确的分量。RMSNorm就像一个称重工具,确保每个步骤的配料量都准确无误,这样菜品才会美味。 SwiGLU(一种激活函数):结合了Swish和Gated Linear Units (GLU) 的特点。想象你有一个聪明的开关,它能决定什么时候打开、什么时候关闭,以确保电流流动最有效。SwiGLU就是这样一个聪明的开关,帮助模型更好地处理信息。 Skywork-13B模型比Llama-2-13B模型更“瘦长”:为了达到Llama2-13B的训练效率,Skywork-13B的训练批次大小增加到Llama2-13B的四倍。由于计算机集群带宽较低,所以需要更多的梯度累积来减少通讯开销。 根据之前的实验,当批次更大时,增加网络层数(即增加模型的复杂度)可以提高模型的表现。因此,模型的层数被增加到52层,同时减小每层的规模,使得模型的总体参数量和Llama2-13B差不多。 为了适应更大的数据批量,学习率被提高到Llama2-13B的两倍,这样可以确保训练时梯度的方差保持一致。 Skywork-13B总共52层,虽然每层的一些参数(FFN Dim和Hidden Dim)比Llama-2-13B模型小,但总的参数量是一样的。 | 模型结构 | Llama-2-13B | Skywork-13B | | 词表大小 | 32,000 | 65,536 | | Hidden Dim | 5,120 | 4,608 | | FFN Dim | 13,696 | 12,288 | | Head Dim | 128 | 128 | | Attention头数 | 40 | 36 | | 层数 | 40 | 52 | | 训练序列长度 | 4,096 | 4,096 | | 位置编码 | RoPE | RoPE |
训练效果:这种“瘦长”的设计在训练时效果更好。 Skywork-13B 与 LLama 中的 TokenizeringFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;font-size: 15px;margin: 1.5em 8px;letter-spacing: 0.1em;color: rgb(63, 63, 63);">在大模型中,tokenizer 扮演着重要的角色。以下是关于 Skywork-13B 与 LLama 模型中的 tokenizer 的一些关键概念:ingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;font-size: 15px;margin: 1.5em 8px;letter-spacing: 0.1em;color: rgb(63, 63, 63);">概念:Tokenize 就是将一段大文本分成更小的、容易处理的单元,通常是单词或短语。类似于读一本书时将其分成一章一章来读,使得处理和理解内容更加容易。ingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;font-size: 15px;margin: 1.5em 8px;letter-spacing: 0.1em;color: rgb(63, 63, 63);">Skywork-13B 中的 Tokenizer:Skywork-13B 的 tokenizer 带有浓厚的 LLama 风格,包含了 LLama 的 32000 个 token。ingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;font-size: 1.1em;font-weight: bold;margin-top: 2em;margin-right: 8px;margin-bottom: 0.75em;padding-left: 8px;border-left: 3px solid rgb(0, 152, 116);color: rgb(63, 63, 63);">中文支持ingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;font-size: 15px;margin: 1.5em 8px;letter-spacing: 0.1em;color: rgb(63, 63, 63);">背景:由于 LLama 模型原生不支持中文,因此需要额外的词汇扩展来增强其中文处理能力。ingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;font-size: 15px;margin: 1.5em 8px;letter-spacing: 0.1em;color: rgb(63, 63, 63);">实现:Skywork-13B 通过以下步骤增强了中文支持:ingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;font-size: 15px;padding-left: 1em;list-style: circle;color: rgb(63, 63, 63);" class="list-paddingleft-1">•从 BERT-Chinese 模型中引入 8000 个 token。 •另外添加了 25000 个中文高频词组。 •最终增加了 17 个保留字。 ingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;font-size: 1.1em;font-weight: bold;margin-top: 2em;margin-right: 8px;margin-bottom: 0.75em;padding-left: 8px;border-left: 3px solid rgb(0, 152, 116);color: rgb(63, 63, 63);">保留字ingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;font-size: 15px;margin: 1.5em 8px;letter-spacing: 0.1em;color: rgb(63, 63, 63);">定义:保留字是指模型中特别需要保留的词汇,如“重要人物的名字”或“地点名称”。这些词在生成和理解过程中需要特殊对待。ingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;font-size: 15px;margin: 1.5em 8px;letter-spacing: 0.1em;color: rgb(63, 63, 63);">比较:Skywork-13B 只有 17 个保留字,这显得相对较少。相比之下,Baichuan2 模型有几千个保留字,可能是为了多模态处理做准备。词表大小概念:词表大小指的是模型词典中包含的词条数量。词表越大,模型可以理解和处理的词汇越多。 Skywork-13B 的词表大小:Skywork-13B 的词表总大小为 65536 个词条,这意味着它有一个非常大的词典,可以处理多种不同的词语和短语。  小结 小结
tokenizer 的重要性:tokenizer 在 Skywork-13B 和 LLama 大模型中起到分词和词汇表管理的重要角色,通过合理的分词和丰富的词汇表,可以大幅提高模型对不同语言和文本的理解和处理能力。这对于多语言支持和多模态应用尤为关键。 模型训练方法的简单解释Skywork-13B用了两阶段的方法。这个方法让模型先学习广泛的知识,然后再专注于特定领域的内容,比如科学和数学,这样可以让模型在解决复杂问题时表现更好。 第一阶段:通用训练在第一阶段,我们让模型学习大量的通用内容,这些内容就像是百科全书里的各种知识。通过这个阶段,模型可以获得广泛的基础知识。我们会监督模型的学习过程,观察它的进步和变化。这时候的模型被称为Skywork-13B-3.1T-Base。 
第二阶段:特定领域训练在第二阶段,我们在模型已经学到的基础知识上,加入了更多关于科学、技术、工程和数学(STEM)的内容。这个阶段的训练让模型在这些领域的能力更强,比如更好地解决数学问题或科学难题。这个阶段用了更多的数据来进一步提高模型的表现,最后我们得到了名为Skywork-13B-Base的最终模型。 
数据集大模型预训练需要从大量的文本数据中学习并存储知识。预训练数据主要有两类:网页数据(web data)和专有数据(curated high-quality corpora)。网页数据获取方便,比如CommonCrawl,是一个包含海量网页数据的公开数据集。而专有数据则是特定领域或行业的数据,比如高质量书籍和对话数据。 像OpenAI的GPT-3、4模型和谷歌的PaLM系列模型都大量使用了专有数据。这些高质量的数据往往不对公众开放,因此很多人认为,像GPT、PaLM等模型的成功,很大程度上归功于这些高质量、难以获取的专有数据。 但是,阿联酋阿布扎比技术创新研究所(TII)的团队提出了不同的观点。他们研究发现,仅通过更好的清洗和过滤策略,使用网页数据也能训练出强大的模型。 这篇论文展示了通过严格的URL过滤、文本提取和去重流程,使用CommonCrawl这样的网页数据训练出的Falcon-40B模型,其表现超过了很多依赖专有数据的模型。通过这种方式,不仅降低了数据获取和处理的成本,还展示了网页数据在大模型训练中的巨大潜力、 中文社区一直在苦苦寻觅高质量的数据集,而相比之下,英文社区已经发布了很多高质量的数据集,比如 C4、RefinedWeb、ThePile 和 The Stack 等等。 中文社区之前最大的开源数据集是 Wudao-data,但它的规模和英文数据集相比显得不足,仅包含大约 530 亿个 token,而 C4 的 token 数超过 1000 亿,RefinedWeb、ThePile 和 The Stack 更是达到了 5000 亿 token 量级。 不仅在数量上有所差距,Wudao-data 的数据质量也存在问题,尽管经过严格清洗过滤,仍然会发现一些格式错乱、重复和低质量的数据。为了填补这个空缺,天工开源了 Skypile-150B 数据集。 这是一个经过精细清洗、去重和过滤的高质量网页数据集,使用了FastText 和 BERT 等模型去除了不良内容和低质量数据。此外,天工Skywork-13B模型还充分利用了CommonCrawl数据集,这是一个海量的、非结构化的、多语言的网页数据集,通过挖掘其中的数百亿网页,提高了跨语言处理的能力。 这次开源的数据集总 token 数约为 1500 亿,硬盘占用 592GB,是目前最大的中文开源数据集。 你可以在以下地址下载 Skypile-150B 数据集: [Skypile-150B下载地址]:(https://modelscope.cn/organization/skywork)[Skypile-150BGitHub]:(https://github.com/SkyworkAI/Skywork) | 数据来源 | 百分比 | | 英文网页数据 | 39.8% | | 英文书籍数据 | 3.6% | | 英文学术论文 | 3.0% | | 英文百科全书 | 0.5% | | 其他英文数据 | 2.9% | | 中文网页数据 | 30.4% | | 中文社交媒体 | 5.5% | | 中文百科全书 | 0.8% | | 其他中文数据 | 3.1% | | 其他语言数据 | 2.4% | | 代码数据 | 8.0%
|
分词器| 类别 | 大小 | | 拉丁基础词和子词 | 32,000 | | 汉字和Unicode符号 | 8,000 | | 汉语词语 | 25,519 | | 保留符号 | 17 | | 总计 | 65,536 |
总结一下•高质量数据:用了大量高质量的英文、中文和代码数据来训练模型。 •瘦长设计:这个模型结构更加“瘦长”,层数更多,但每层的某些参数比Llama-2-13B模型小。 •分词器:分词器能处理多种字符和词语,确保模型能理解不同语言的内容。
语言模型的评估方式训练语言模型的目的是让它更准确地预测下一个词。评估模型的一个重要方式是计算它在生成文章时的概率。通常用“交叉熵损失函数”来衡量模型的预测准确性。具体来说,就是计算每个词的预测概率,然后取这些概率的对数平均值。为了更直观地比较不同模型的表现,我们将这个损失值转化为“困惑度”(perplexity)。困惑度越低,说明模型越好。 看看天工AI团队是怎么说的(向上滑动) Skywork-13B的训练选取了2023年9月发布的数百到上千篇高质量文章,这些文章不在任何模型的训练集中,并且来源广泛、质量高。测试结果显示,不同开源模型中,Skywork-13B-Base模型表现最好。 
▲图展示了不同开源模型的性能。Skywork-13B-Base 取得了最佳效果。 Skywork-13B-Base模型在不同基准测试中的表现在几个热门的基准测试上评估了Skywork-13B-Base模型,包括C-Eval、MMLU、CMMLU和GSM8K。按照5-shot和8-shot的测试方法,Skywork-13B-Base模型在中文开源模型中名列前茅,表现非常出色。具体来看,它在STEM、人文学科、社会科学和其他领域都有出色表现,尤其是在中文特定领域的测试中也显示了优越的能力。 
通过这些调整和评估,Skywork-13B-Base模型不仅在训练效率上达到了预期,还在多个测试中表现出色,证明了其作为开源中文模型的强大能力。 为了让大家更好地理解和复现这些结果,评测数据和评测脚本都已经开源。你可以在GitHub上找到相关代码并运行命令来复现这些评估结果。天工Skywork-13B在自然语言处理领域有广泛的应用,包括文本分类、情感分析、问答系统、代码生成和自动化编程等多个方面。此外,模型还支持多语言处理,使得跨语言交流变得更加便捷。模型微调的通俗化解释(结合Skywork-13B)在训练大语言模型时,微调(Fine-Tuning)是让模型更好地适应特定任务或数据的一种方法。这里有几种不同的微调方法,我们来逐个看看它们的区别和用法。 1. 全量微调(Full Fine-Tuning)是什么:这是最常见的一种微调方法,它会调整模型中的所有参数。 怎么做: 步骤: •预处理数据:使用脚本将训练数据准备好。 pythontrain/pt_data_preprocess.py-t$MODEL_PATH-idata/pt_train.jsonl-odata_cache/pt_train_demo •启动训练:设置环境变量并运行训练脚本。 exportWANDB_API_KEY=YOUR_WANDB_KEY
exportWANDB_ENTITY=skywork
exportWANDB_PROJECT=skywork-13b-opensource
exportMODEL_PATH=skywork-13b-models/skywork-13b-base
exportDATA_CACHE_DIR=data_cache/pt_train_demo/pt_train
bashbash_scripts/skywork_13b_pt.sh
适用场景:当你有大量的新数据,并且需要模型在这些数据上有很好的表现时,使用全量微调。 2. 有监督微调(Supervised Fine-Tuning, SFT)是什么:这种方法专注于让模型在特定任务上表现更好,比如回答问题或文本分类。 怎么做: 步骤: •预处理数据并启动训练:设置环境变量并运行训练脚本。 exportWANDB_API_KEY=YOUR_WANDB_KEY
exportWANDB_ENTITY=skywork
exportWANDB_PROJECT=skywork-13b-opensource
exportSFT_DATA_DIR=data/sft_data
exportDATA_CACHE_DIR=data_cache/sft_train_demo
bashbash_scripts/skywork_13b_sft.sh
适用场景:当你需要模型在某个特定任务上有很好的表现,比如客服机器人需要回答客户的问题。 3. LoRA微调(Low-Rank Adaptation, LoRA)是什么:LoRA是一种轻量级的微调方法,通过增加少量的适配层,来调整模型的部分参数。 怎么做: 步骤: •预处理数据:和全量微调类似,但适用于LoRA方法。 pythontrain/pt_data_preprocess.py-t$MODEL_PATH-idata/pt_train.jsonl-odata_cache/pt_train_demo •启动预训练微调:设置环境变量并运行训练脚本。 exportWANDB_API_KEY=YOUR_WANDB_KEY
exportWANDB_ENTITY=skywork
exportWANDB_PROJECT=skywork-13b-opensource
exportMODEL_PATH=skywork-13b-models/skywork-13b-base
exportDATA_CACHE_DIR=data_cache/pt_train_demo/pt_train
bashbash_scripts/skywork_13b_pt_lora.sh
适用场景:当计算资源有限,但仍希望模型能适应新数据或任务时,使用LoRA微调。 4. 使用LoRA进行有监督微调(SFT with LoRA)是什么:这种方法结合了LoRA和有监督微调的优点,既高效又能在特定任务上表现出色。 怎么做: 步骤: 适用场景:当希望在特定任务上高效微调模型,同时节省计算资源时,使用这方法。 总结一下这些方法各有优缺点,可以根据具体需求选择合适的微调方法。 依赖安装•Python 3.8及以上版本 •Pytorch 2.0及以上版本 •CUDA建议使用11.4以上版本。
Skywork-13B-Base模型,Skywork-13B-Chat模型和Skywork-13B-Math模型运行下面的脚本进行Python依赖安装。 pipinstall-rrequirements.txt Hugging Face模型测试Base 模型推理
fromtransformersimportAutoModelForCausalLM,AutoTokenizer
fromtransformers.generationimportGenerationConfig
importtorch
tokenizer=AutoTokenizer.from_pretrained("SkyworkAI/Skywork-13B-Base",trust_remote_code=True)
model=AutoModelForCausalLM.from_pretrained("SkyworkAI/Skywork-13B-Base",device_map="auto",trust_remote_code=True).eval()
inputs=tokenizer('陕西的省会是西安',return_tensors='pt').to(model.device)
response=model.generate(inputs.input_ids,max_length=128)
print(tokenizer.decode(response.cpu()[0],skip_special_tokens=True))
"""
陕西的省会是西安,西安是我国著名的古都,在历史上有十三个朝代在此建都,所以西安又被称为“十三朝古都”。西安是我国著名的旅游城市,每年都有大量的游客来到西安旅游,西安的旅游资源非常丰富,有很多著名的旅游景点,比如秦始皇兵马俑、大雁塔、华清池、大唐芙蓉园、西安城墙、大明宫国家遗址公园、西安碑林博物馆、西安钟楼、西安鼓楼、西安半坡博物馆、西安大兴善寺、西安小雁塔
"""
inputs=tokenizer('陕西的省会是西安,甘肃的省会是兰州,河南的省会是郑州',return_tensors='pt').to(model.device)
response=model.generate(inputs.input_ids,max_length=128)
print(tokenizer.decode(response.cpu()[0],skip_special_tokens=True))
"""
陕西的省会是西安,甘肃的省会是兰州,河南的省会是郑州,湖北的省会是武汉,湖南的省会是长沙,江西的省会是南昌,安徽的省会是合肥,江苏的省会是南京,浙江的省会是杭州,福建的省会是福州,广东的省会是广州,广西的省会是南宁,海南的省会是海口,四川的省会是成都,贵州的省会是贵阳,云南的省会是昆明,西藏的省会是拉萨,青海的省会是西宁,宁夏的省会是银川,新疆的省会是乌鲁木齐。
"""中国AI搜索鼻祖:启发式回答与多维搜索,破解知识碎片化,超越Perplexity的绝赞研究者模式!
|










