|
编者:清华智谱GLM4-9B很惊艳。对比之前介绍的CohereAya23B,以及Llama3 -8B很有特点。其中有一点与加拿大CohereAya类似就是支持的语言到达26种,除了中文英文,更包括东亚日文,韩文及俄语、法语、德语、西班牙语、阿拉伯语等。这为中国企业全球化和一带一路的出海数字化支持提供了最坚实的新质生产力新引擎。上下文长度达到1M,训练数据量达到10T.而且具有多模态支持能力,所以眼前很一亮,可以用夏日的大模型市场惊鸿一瞥来描述,值得深入试用和推荐。 
目录
1关于GLM4-9B
2 9B模型介绍
3模型列表
4评测结果
4.1基座模型典型任务
4.2长文本
5多语言能力
6工具调用能力
7多模态能力
8快速调用
8.1硬件配置和系统要求
8.2基础功能调用
8.3使用以下方法快速调用 GLM-4-9B-Chat 语言模型
8.4使用以下方法快速调用 GLM-4V-9B 多模态模型
8.5完整项目列表
8.6友情链接
8.7协议
8.8引用
9附录 高效微调架构框架 1关于GLM4-9B
GLM-4系列:开源多语言多模态对话模型
开源许可:Apache-2.0 license Stars1.8kstars(Hugging Face 
2 GLM4-9B模型介绍
GLM-4-9B是智谱AI推出的最新一代预训练模型GLM-4系列中的开源版本。在语义、数学、推理、代码和知识等多方面的数据集测评中,GLM-4-9B及其人类偏好对齐的版本GLM-4-9B-Chat均表现出超越Llama-3-8B的卓越性能。除了能进行多轮对话,GLM-4-9B-Chat还具备网页浏览、代码执行、自定义工具调用(Function Call)和长文本推理(支持最大128K上下文)等高级功能。本代模型增加了多语言支持,支持包括日语,韩语,德语在内的26种语言。我们还推出了支持1M上下文长度(约200万中文字符)的GLM-4-9B-Chat-1M模型和基于GLM-4-9B的多模态模型GLM-4V-9B。GLM-4V-9B具备1120 * 1120高分辨率下的中英双语多轮对话能力,在中英文综合能力、感知推理、文字识别、图表理解等多方面多模态评测中,GLM-4V-9B表现出超越GPT-4-turbo-2024-04-09、Gemini 1.0 Pro、Qwen-VL-Max和Claude 3 Opus的卓越性能。
3模型列表

4评测结果
对话模型典型任务

4.1基座模型典型任务

由于GLM-4-9B在预训练过程中加入了部分数学、推理、代码相关的instruction数据,
所以将Llama-3-8B-Instruct也列入比较范围。
4.2长文本
在1M的上下文长度下进行大海捞针实验,结果如下:

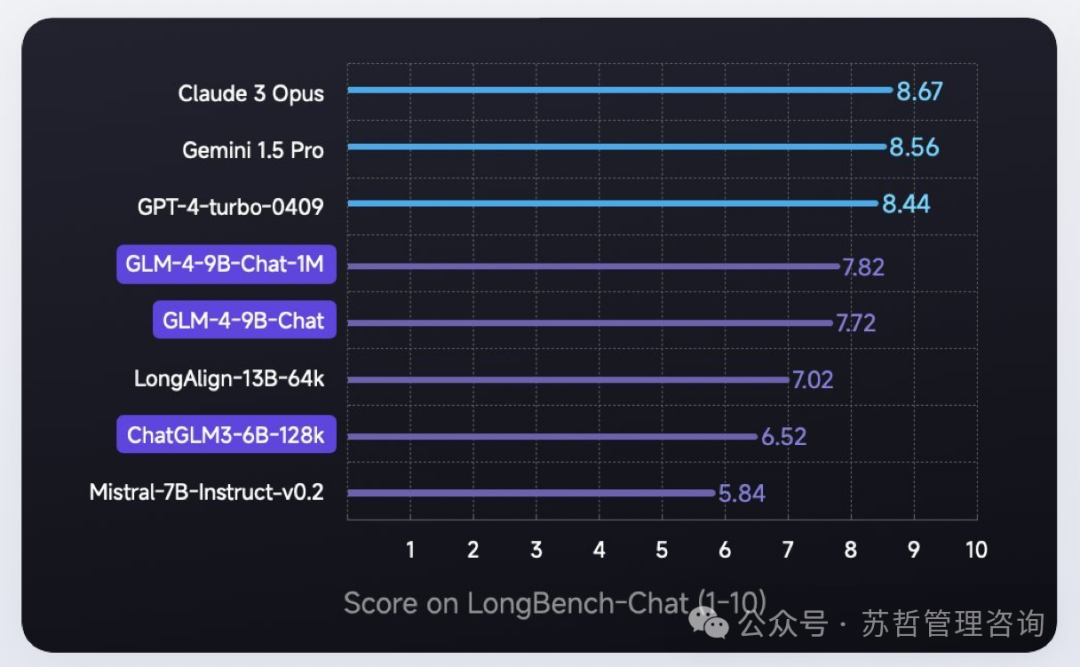
在LongBench-Chat上对长文本能力进行了进一步评测,结果如下:

5多语言能力
在六个多语言数据集上对GLM-4-9B-Chat和Llama-3-8B-Instruct进行了测试,测试结果及数据集对应选取语言如下表

6工具调用能力
我们在Berkeley Function Calling Leaderboard上进行了测试并得到了以下结果:


7多模态能力
GLM-4V-9B是一个多模态语言模型,具备视觉理解能力,其相关经典任务的评测结果如下:

8快速调用
8.1硬件配置和系统要求
本demo中,你将体验到如何使用GLM-4-9B开源模型进行基本的任务。
请严格按照文档的步骤进行操作,以避免不必要的错误。
设备和依赖检查
相关推理测试数据
本文档的数据均在以下硬件环境测试,实际运行环境需求和运行占用的显存略有不同,请以实际运行环境为准。
测试硬件信息:
相关推理的压力测试数据如下:
所有测试均在单张GPU上进行测试,所有显存消耗都按照峰值左右进行测算
GLM-4-9B-Chat
精度
| 显存占用
| Prefilling
| Decode Speed
| Remarks
| BF16
| 19 GB
| 0.2s
| 27.8 tokens/s
| 输入长度为1000
| BF16
| 21 GB
| 0.8s
| 31.8 tokens/s
| 输入长度为8000
| BF16
| 28 GB
| 4.3s
| 14.4 tokens/s
| 输入长度为32000
| BF16
| 58 GB
| 38.1s
| 3.4 tokens/s
| 输入长度为128000
|
精度
| 显存占用
| Prefilling
| Decode Speed
| Remarks
| INT4
| 8 GB
| 0.2s
| 23.3 tokens/s
| 输入长度为1000
| INT4
| 10 GB
| 0.8s
| 23.4 tokens/s
| 输入长度为8000
| INT4
| 17 GB
| 4.3s
| 14.6 tokens/s
| 输入长度为32000
|
GLM-4-9B-Chat-1M
精度
| 显存占用
| Prefilling
| Decode Speed
| Remarks
| BF16
| 75 GB
| 98.4s
| 2.3 tokens/s
| 输入长度为200000
|
如果您的输入超过200K,我们建议您使用vLLM后端进行多卡推理,以获得更好的性能。
GLM-4V-9B
精度
| 显存占用
| Prefilling
| Decode Speed
| Remarks
| BF16
| 28 GB
| 0.1s
| 33.4 tokens/s
| 输入长度为1000
| BF16
| 33 GB
| 0.7s
| 39.2 tokens/s
| 输入长度为8000
|
精度
| 显存占用
| Prefilling
| Decode Speed
| Remarks
| INT4
| 10 GB
| 0.1s
| 28.7 tokens/s
| 输入长度为1000
| INT4
| 15 GB
| 0.8s
| 24.2 tokens/s
| 输入长度为8000 |
最低硬件要求
如果您希望运行官方提供的最基础代码(transformers后端)您需要:
如果您希望运行官方提供的本文件夹的所有代码,您还需要:
安装依赖
pipinstall-rrequirements.txt 8.2基础功能调用
除非特殊说明,本文件夹所有demo并不支持Function Call和All Tools等进阶用法
使用transformers后端代码
pythontrans_cli_demo.py#GLM-4-9B-Chat python trans_cli_vision_demo.py # GLM-4V- 使用Gradio网页端与GLM-4-9B-Chat模型进行对话。 python trans_web_demo.py 使用Batch推理。 pythoncli_batch_request_demo.py使用vLLM后端代码 python vllm_cli_demo.py 自行构建服务端,并使用OpenAI API的请求格式与GLM-4-9B-Chat模型进行对话。本demo支持Function Call和All Tools功能。 启动服务端:
python openai_api_server.py 客户端请求: python openai_api_request.py 压力测试 用户可以在自己的设备上使用本代码测试模型在transformers后端的生成速度:
pythontrans_stress_test.py
8.3快速调用GLM-4-9B-Chat语言模型
使用transformers后端进行推理:
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
device = "cuda"
tokenizer = AutoTokenizer.from_pretrained("THUDM/glm-4-9b-chat", trust_remote_code=True)
query = "你好"
inputs = tokenizer.apply_chat_template([{"role": "user", "content": query}],
add_generation_prompt=True,
tokenize=True,
return_tensors="pt",
return_dict=True
)
inputs = inputs.to(device)
model = AutoModelForCausalLM.from_pretrained(
"THUDM/glm-4-9b-chat",
torch_dtype=torch.bfloat16,
low_cpu_mem_usage=True,
trust_remote_code=True
).to(device).eval()
gen_kwargs = {"max_length": 2500, "do_sample": True, "top_k": 1}
with torch.no_grad():
outputs = model.generate(**inputs, **gen_kwargs)
outputs = outputs[:, inputs['input_ids'].shape[1]:]
print(tokenizer.decode(outputs[0],skip_special_tokens=True))使用vLLM后端进行推理: from transformers import AutoTokenizer
from vllm import LLM, SamplingParams
# GLM-4-9B-Chat-1M
# max_model_len, tp_size = 1048576, 4
# 如果遇见 OOM 现象,建议减少max_model_len,或者增加tp_size
max_model_len, tp_size = 131072, 1
model_name = "THUDM/glm-4-9b-chat"
prompt = [{"role": "user", "content": "你好"}]
tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True)
llm = LLM(
model=model_name,
tensor_parallel_size=tp_size,
max_model_len=max_model_len,
trust_remote_code=True,
enforce_eager=True,
# GLM-4-9B-Chat-1M 如果遇见 OOM 现象,建议开启下述参数
# enable_chunked_prefill=True,
# max_num_batched_tokens=8192
)
stop_token_ids = [151329, 151336, 151338]
sampling_params = SamplingParams(temperature=0.95, max_tokens=1024, stop_token_ids=stop_token_ids)
inputs = tokenizer.apply_chat_template(prompt, tokenize=False, add_generation_prompt=True)
outputs = llm.generate(prompts=inputs, sampling_params=sampling_params)
print(outputs[0].outputs[0].text)
8.4快速调用GLM-4V-9B多模态模型
使用transformers后端进行推理: importtorch fromPILimportImage fromtransformersimportAutoModelForCausalLM,AutoTokenizer device="cuda" tokenizer=AutoTokenizer.from_pretrained("THUDM/glm-4v-9b",trust_remote_code=True)query='描述这张图片' image=Image.open("yourimage").convert('RGB')inputs=tokenizer.apply_chat_template([{"role":"user","image":image,"content":query}],add_generation_prompt=True,tokenize=True,return_tensors="pt", return_dict=True)#chatmode inputs=inputs.to(device) model=AutoModelForCausalLM.from_pretrained( "THUDM/glm-4v-9b", torch_dtype=torch.bfloat16, low_cpu_mem_usage=True, trust_remote_code=True ).to(device).eval() gen_kwargs={"max_length":2500,"do_sample":True,"top_k":1}withtorch.no_grad(): outputs=model.generate(**inputs,**gen_kwargs) outputs=outputs[:,inputs['input_ids'].shape[1]:] print(tokenizer.decode(outputs[0])注意:GLM-4V-9B暂不支持使用vLLM方式调用。 8.5完整项目列表
如果你想更进一步了解GLM-4-9B系列开源模型,本开源仓库通过以下内容为开发者提供基础的GLM-4-9B的使用和开发代码
·base:在这里包含了
·composite_demo:在这里包含了
·fintune_demo:在这里包含了
8.6友情链接

8.7 开源协议
·GLM-4模型的权重的使用则需要遵循模型协议。
·本开源仓库的代码则遵循Apache 2.0协议。
请您严格遵循开源协议。 8.8引用如果你觉得我们的工作有帮助的话,请考虑引用下列论文。
@inproceedings{zeng2022glm,title={{GLM-130B:}AnOpenBilingualPre-trainedModel},author={Zeng,AohanandLiu,XiaoandDu,ZhengxiaoandWang,ZihanandLai,HanyuandDing,MingandYang,ZhuoyiandXu,YifanandZheng,WendiandXia,Xiaoandothers},booktitle={TheEleventhInternationalConferenceonLearningRepresentations,{ICLR}2023,Kigali,Rwanda,May1-5,2023},year={2023},}@inproceedings{du2022glm,
title={GLM:GeneralLanguageModelPretrainingwithAutoregressiveBlankInfilling},author={Du,ZhengxiaoandQian,YujieandLiu,XiaoandDing,MingandQiu,JiezhongandYang,ZhilinandTang,Jie},booktitle={Proceedingsofthe60thAnnualMeetingoftheAssociationforComputationalLinguistics(Volume1 ongPapers)}, ongPapers)},pages={320--335},year={2022}}title={CogVLM:VisualExpertforPretrainedLanguageModels},
author={WeihanWangandQingsongLvandWenmengYuandWenyiHongandJiQiandYanWangandJunhuiJiandZhuoyiYangandLeiZhaoandXixuanSongandJiazhengXuandBinXuandJuanziLiandYuxiaoDongandMingDingandJieTang},year={2023},eprint={2311.03079},archivePrefix={arXiv},primaryClass={cs.CV}}
9附录高效微调架构框架

9.1微调大型语言模型可能很容易,因为...... 选择路径:
1.合作:https://colab.research.google.com/drive/1eRTPn37ltBbYsISy9Aw2NuI2Aq5CQrD9?usp=sharing
2.PAI-DSW:https://gallery.pai-ml.com/#/preview/deepLearning/nlp/llama_factory
3.本地机:请参考使用情况 | 









