|
大型语言模型(LLMs)在自然语言理解和生成方面表现出色,但面对现实世界问题的多样性和复杂性,单一静态方法的推理能力有限。现有的推理技术,如思维链(Chain-of-Thoughts)、思维树(Tree-of-Thoughts)等,虽然在特定任务上有所提升,但未能在不同任务中持续实现最佳性能。人类在认知过程中通过元推理(meta-reasoning)动态调整策略,以高效分配认知资源。受此启发,提出了元推理提示(Meta-Reasoning Prompting, MRP),以赋予LLMs类似的适应性推理能力。元推理提示(Meta-Reasoning Prompting,简称MRP)的示意图,以及与标准推理和传统推理方法的比较差异。 
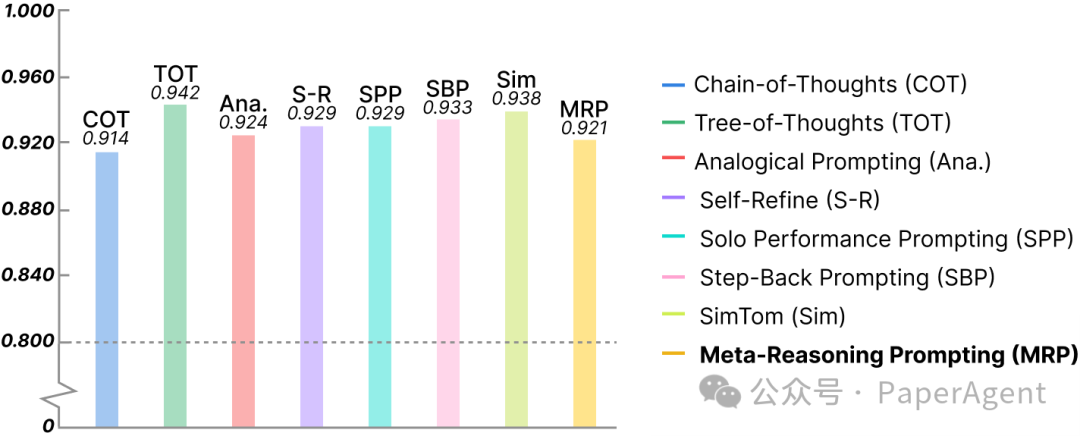
MRP如何工作?通过使用多个广泛使用的基准测试评估MRP的有效性,结果表明MRP在不同任务中的表现达到或接近最佳状态。MRP特别擅长需要结合不同推理策略的任务,在更大的模型如GPT-4中表现尤为出色。使用GPT4进行的实验:使用元推理提示(Meta-Reasoning Prompting)与其他独立方法在基准测试上的性能比较。加粗表示最佳性能,下划线表示次佳性能。 (a) 不同基准测试上的方法比较显示,引导大型语言模型(LLM)动态选择适当的推理方法,使元推理提示(MRP)在所有任务中持续实现更好的性能。(b) 将特定推理方法应用于所有基准测试的算术平均和调和平均性能表明,MRP在总体评估中始终表现卓越。


MetaReasoningforLargeLanguageModelshttps://arxiv.org/pdf/2406.11698,提升自己。 | 









