|
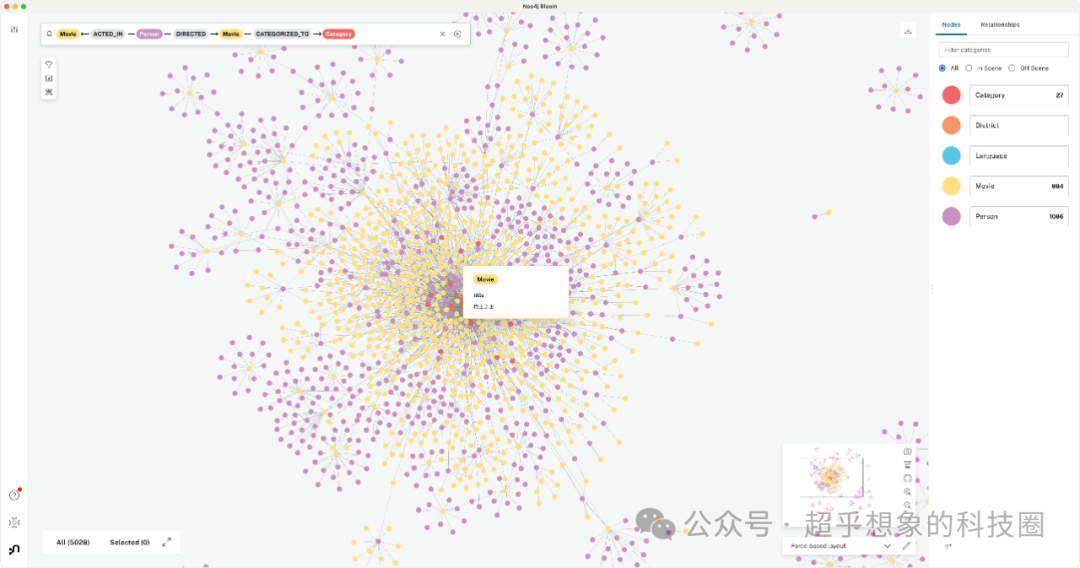
知识图谱在大语言模型兴起之前,一度被作为最有可能实现AGI的技术之一,只是大语言模型火了之后,这项技术慢慢没那么受关注了,但这项技术本身毋庸置疑还是可以解决一些问题的。本文使用一份开源的豆瓣电影数据,使用当前最流行的图数据库Neo4j,构建一个电影知识图谱,并在上面做一些简单的分析,诸如“演员最多的电影”、“参演电影超过10部的演员及其参演的电影”、“黄渤和莱昂纳多·迪卡普里奥的最短距离”等。本文清洗好的以便于导入Neo4j的数据已经在Github开源,地址为:https://github.com/Steven-Luo/neo4j-douban-movies
原始数据来源:http://data.openkg.cn/dataset/douban-movie-kg原始数据大家可以访问上面的链接,或者到Github仓库中,获取加工好的可以直接导入Neo4j的数据 3 数据预处理原始数据每条记录只有一个电影记录,并没有抽象出节点和关系,通过数据预处理,对节点和关系进行抽象和重组,消除数据冗余,便于后续分析。具体而言,有以下节点类型:
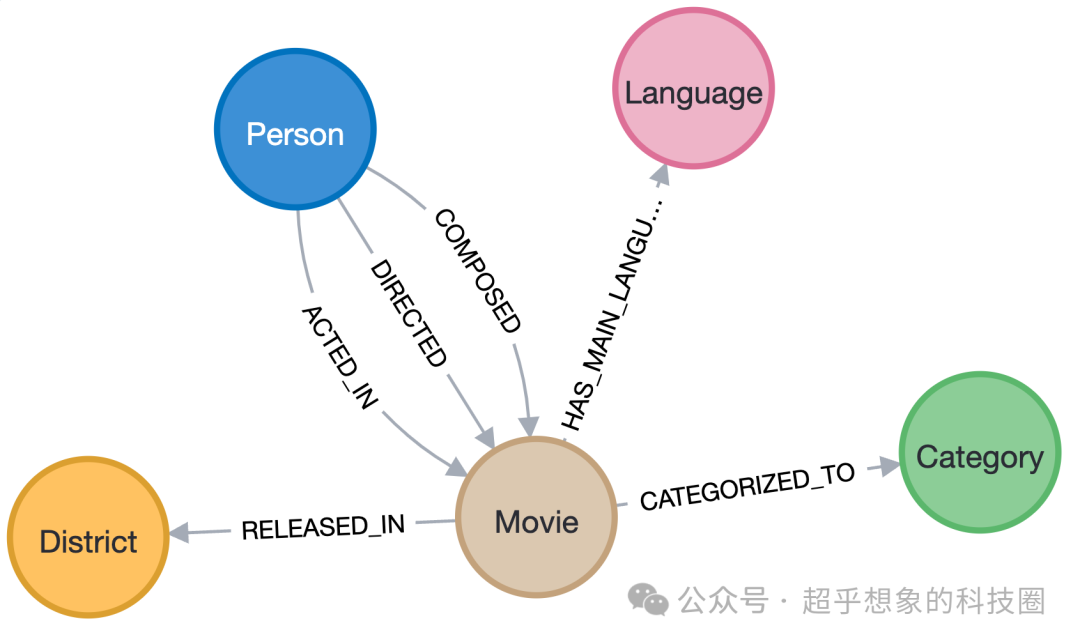
电影——Movie 人——Person 语言——Language 发行地区——District 电影类型——Category
有以下关系类型: schema或者所谓的本体如下:
os.makedirs(,exist_ok=)
data=json.load(())
persons=[]
categories=[]
languages=[]
movies=[]
districts=[]
acted_in=[]
categorized_to=[]
directed=[]
composed=[]
released_in=[]
has_main_language=[]
itemdata:
key(,,,,):
item[key]:
item[key]=[]
persons.extend(item[])
persons.extend(item[])
persons.extend(item[])
languages.extend(item[])
districts.extend(item[])
categories.extend(item[])
movies.append({
:item[],
:item[],
:item[],
:item[],
:item[],
 item[])item[],
item[])item[],
:item[]
})
directoritem[]:
directed.append({
:item[],
:director
})
composeritem[]:
composed.append({
:item[],
:composer
})
actoritem[]:
acted_in.append({
:item[],
:actor
})
categoryitem[]:
categorized_to.append({
:item[],
:category
})
regionitem[]:
released_in.append({
:item[],
:region
})
languageitem[]:
has_main_language.append({
:item[],
:language
})
item[
(,persons),
(,categories),
(,languages),
(,movies),
(,districts)
]:
item[]==:
pd.DataFrame(item[]).to_csv(os.path.join(,item[]+),index=)
:
pd.DataFrame((item[]),columns=[]).to_csv(os.path.join(,item[]+),index=)
rel[
(,acted_in),
(,categorized_to),
(,directed),
(,composed),
(,released_in),
(,has_main_language),
]:
pd.DataFrame(rel[]).to_csv(os.path.join(,rel[].upper()+),index=) item[])item[],
item[])item[],
:item[]
})
directoritem[]:
directed.append({
:item[],
:director
})
composeritem[]:
composed.append({
:item[],
:composer
})
actoritem[]:
acted_in.append({
:item[],
:actor
})
categoryitem[]:
categorized_to.append({
:item[],
:category
})
regionitem[]:
released_in.append({
:item[],
:region
})
languageitem[]:
has_main_language.append({
:item[],
:language
})
item[
(,persons),
(,categories),
(,languages),
(,movies),
(,districts)
]:
item[]==:
pd.DataFrame(item[]).to_csv(os.path.join(,item[]+),index=)
:
pd.DataFrame((item[]),columns=[]).to_csv(os.path.join(,item[]+),index=)
rel[
(,acted_in),
(,categorized_to),
(,directed),
(,composed),
(,released_in),
(,has_main_language),
]:
pd.DataFrame(rel[]).to_csv(os.path.join(,rel[].upper()+),index=)准备工作,首先要修改配置,在下图Settings...中,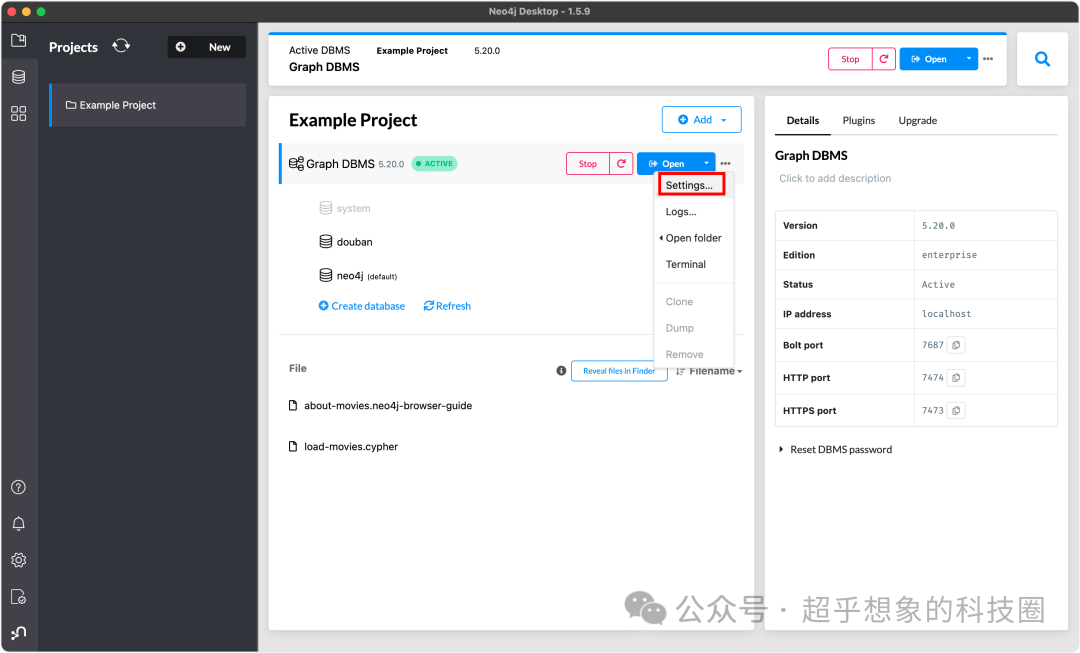 注释掉如下的语句,这样可以允许导入数据时,从任意路径导入: server.directories.import=import 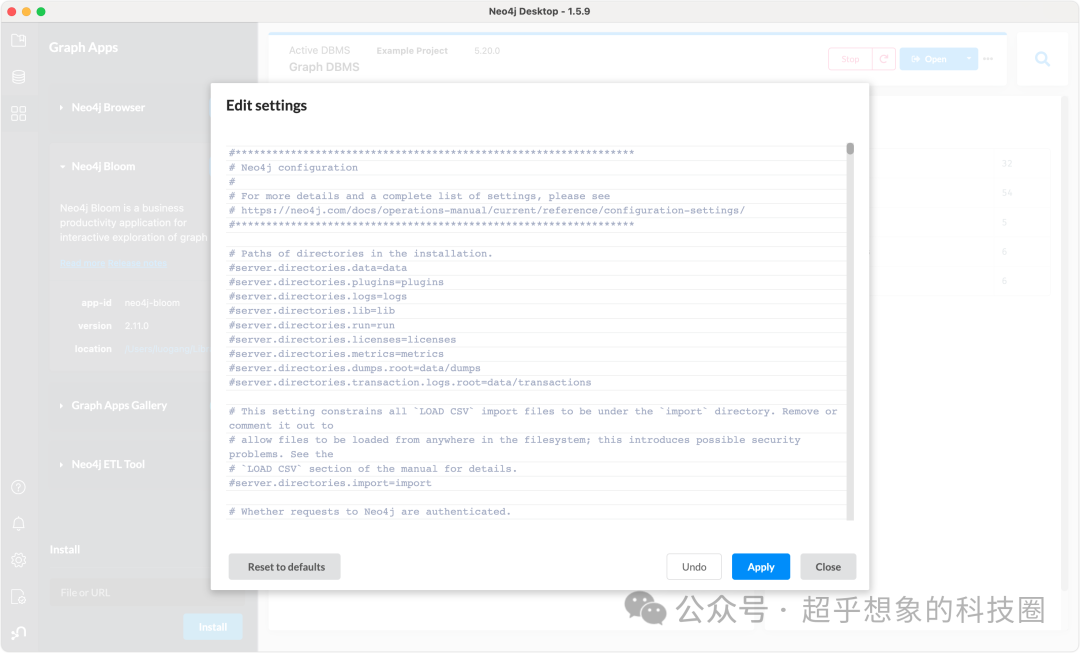
4.1.2 安装插件 另外,需要安装APOC插件 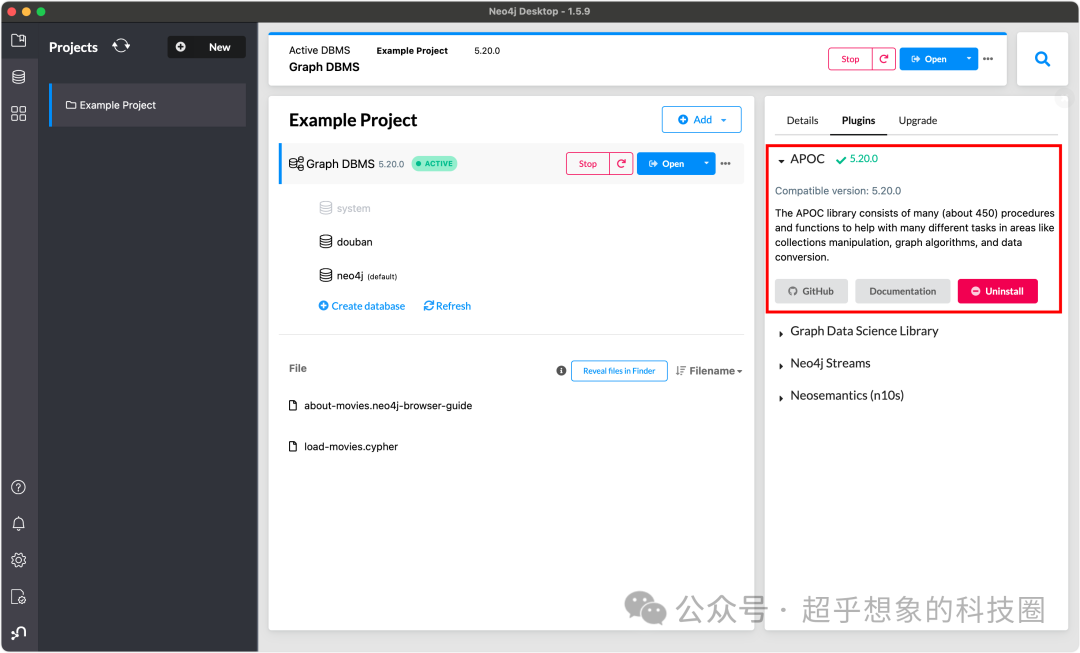
4.2 开始导入后续所有导入操作,在Neo4j Browser中进行
:auto
(:Movie{
id:line[id],
title:line[title],
cover:line[cover],
length:toInteger(line[length]),
rate:toFloat(line[rate]),
showtime:toInteger(line[showtime]),
url:line[url],
othername:line[othername]
})Neo4j 4.0及以上版本不再支持 USING PERIODIC COMMIT,需要使用 CALL { ... } IN TRANSACTIONS 进行替换。上面只是旧版本的示例,后续不再包含旧版本Cypher语句。 注意:路径中不要包含中文,否则会报Bad escape (Transactions committed: 0)
{
line
(:Movie{
id:line[id],
title:line[title],
cover:line[cover],
length:toInteger(line[length]),
rate:toFloat(line[rate]),
showtime:toInteger(line[showtime]),
url:line[url],
othername:line[othername]
})
}TRANSACTIONS{
line
( erson{
name:line[name]
})
}TRANSACTIONS erson{
name:line[name]
})
}TRANSACTIONS{
line
( istrict{
name:line[name]
})
}TRANSACTIONS istrict{
name:line[name]
})
}TRANSACTIONS{
line
( anguage{
name:line[name]
})
}TRANSACTIONS anguage{
name:line[name]
})
}TRANSACTIONS:autoLOADCSVWITHHEADERSFROMASline
CALL{
WITHline
CREATE(:Category{
name:line[]
})
}INTRANSACTIONS{
line
(serson{name:line[actor]}),(e:Movie{id:line[movie_id]})
(s)-[:ACTED_IN]->(e)
}TRANSACTIONS4.2.3.2 导入CATEGORIZED_TO关系{
line
(s:Movie{id:line[movie_id]}),(e:Category{name:line[category]})
(s)-[:CATEGORIZED_TO]->(e)
}TRANSACTIONS{
line
(serson{name:line[director]}),(e:Movie{id:line[movie_id]})
(s)-[IRECTED]->(e)
}TRANSACTIONS{
line
(serson{name:line[composer]}),(e:Movie{id:line[movie_id]})
(s)-[:COMPOSED]->(e)
}TRANSACTIONS{
line
(s:Movie{id:line[movie_id]}),(eistrict{name:line[region]})
(s)-[:RELEASED_IN]->(e)
}TRANSACTIONS4.2.3.6 导入HAS_MAIN_LANGUAGE关系{
line
(s:Movie{id:line[movie_id]}),(eanguage{name:line[language]})
(s)-[:HAS_MAIN_LANGUAGE]->(e)
}TRANSACTIONS
4.3 分析
p=(erson)-[r:ACTED_IN]->(m:Movie)
m,count(p)cnt
m.title,cntcnt path=(person)-[:ACTED_IN]-()
p,count(path)cnt
p.name,cntcnt 4.3.3 参演电影超过10部的演员,获取演员、电影(person)-[:ACTED_IN]->(m:Movie)
p,count(m)rels,collect(m)movies
rels>
p,movies,rels
rels path=(person)-[IRECTED]-()
p,count(path)cnt
p.name,cntcnt 4.3.5 “莱昂纳多·迪卡普里奥”和“黄渤”的最短路径,限定只能是ACTED_IN关系,同时限定必须是1至8度关系p=shortestPath((erson{name:})-[:ACTED_IN*..]-(:Person{name:}))
p 4.3.6 “莱昂纳多·迪卡普里奥”和“黄渤”的最短路径,限定只能是ACTED_IN或DIRECTED关系,同时限定必须是1至8度关系,获取他们的最短距离长度p=shortestPath((:Person{name:})-[r:ACTED_IN|DIRECTED*..]-(:Person{name:}))
size(r)
|










