随着数据驱动应用的兴起,如何高效地存储和查询高维向量数据成为了一个重要的问题。向量数据库应运而生,它专门设计用于处理高维向量数据,如文本、图像、音频等,具有高效的存储、索引和检索能力。本文将介绍向量数据库的基本概念、主流向量数据库对比,并以Chroma为例展示如何保存和查询数据。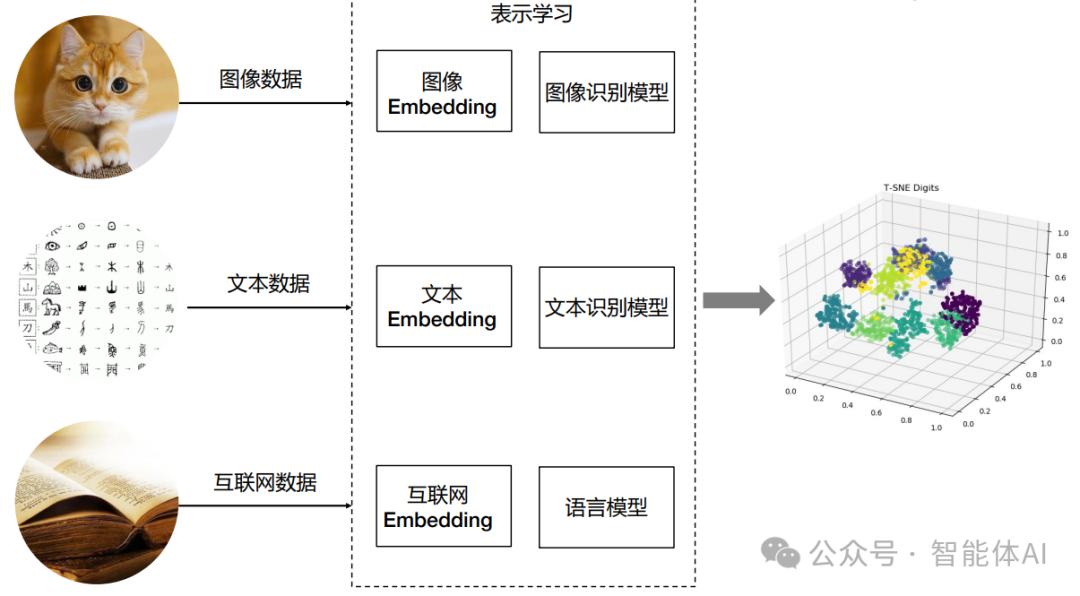
一. 什么是向量数据库?向量数据库是一种专门用于存储、索引和检索高维向量的数据库系统。它在处理和管理向量数据的应用中非常高效,如自然语言处理中的词嵌入、图像处理中的特征向量等。
向量数据库的特点:- 向量表示:将数据转换为向量表示,使其能够捕捉数据的语义或特征。
- 高效查询:通过专门的索引结构和算法,实现快速的相似性查询。
- 应用场景:广泛应用于图像搜索、文本检索、推荐系统等领域。
二. 主流的向量数据库对比目前市场上有几种主流的向量数据库,各有其特点和优势。下面是一张对比表: | | | | | | 支持大规模、高效相似性搜索,支持CPU和GPU加速 | | | | 基于森林的近似最近邻搜索算法,适用于内存中存储和查询 | | | | 开源、高性能,支持大规模数据存储和高效检索,支持分布式部署 | | | Yury Malkov和Dmitry Yashunin | 基于小世界图理论的高效近似最近邻搜索库,支持高维和大规模数据 | | | Elasticsearch with Vector Search | | | | | | 完全托管的向量数据库,提供简单的API接口,自动扩展和优化 | | | Chroma (Community-driven) | 开源,专注于易用性和高性能,支持多种索引和查询优化 | |
三、使用Chroma进行数据保存和查询以Chroma为例,展示如何保存和查询数据。Chroma是一款开源且易用的向量数据库,适用于各种向量搜索和数据分析应用。3.1 安装Chroma3.2 数据插入(保存)以下代码展示了如何将数据插入到Chroma数据库中:from chroma import ChromaClientimport numpy as np
# 连接到Chroma服务器client = ChromaClient()
# 创建集合collection_name = "example_collection"dimension = 128# 向量的维度client.create_collection(name=collection_name, dimension=dimension)
# 生成数据ids = [str(i) for i in range(10)]vectors = [np.random.random(dimension).tolist() for _ in range(10)]metadata = [{"id": i} for i in ids]
# 插入数据client.insert(collection_name=collection_name, ids=ids, vectors=vectors, metadata=metadata)
3.3 创建索引为了加速查询,可以创建索引。Chroma通常会自动处理索引创建,但如果需要手动控制,可以如下操作:# 创建索引(如果Chroma支持手动索引创建)# client.create_index(collection_name=collection_name, index_type="IVF_FLAT", params={"nlist": 128})
3.4 查询数据# 查询向量query_vector = np.random.random(dimension).tolist()search_params = {"metric_type": "L2",# 或其他支持的度量类型"params": {"nprobe": 10}}
results = client.search(collection_name=collection_name,query_vector=query_vector,top_k=5,# 返回前5个相似结果search_params=search_params)
# 输出查询结果for result in results:print("ID:", result['id'], "Distance:", result['distance'])
3.5. 管理数据# 删除数据client.delete(collection_name=collection_name, ids=["1"])
# 更新数据updated_vector = np.random.random(dimension).tolist()client.update(collection_name=collection_name, id="2", vector=updated_vector)
四. 基于大模型和向量数据库的问答系统的工作流程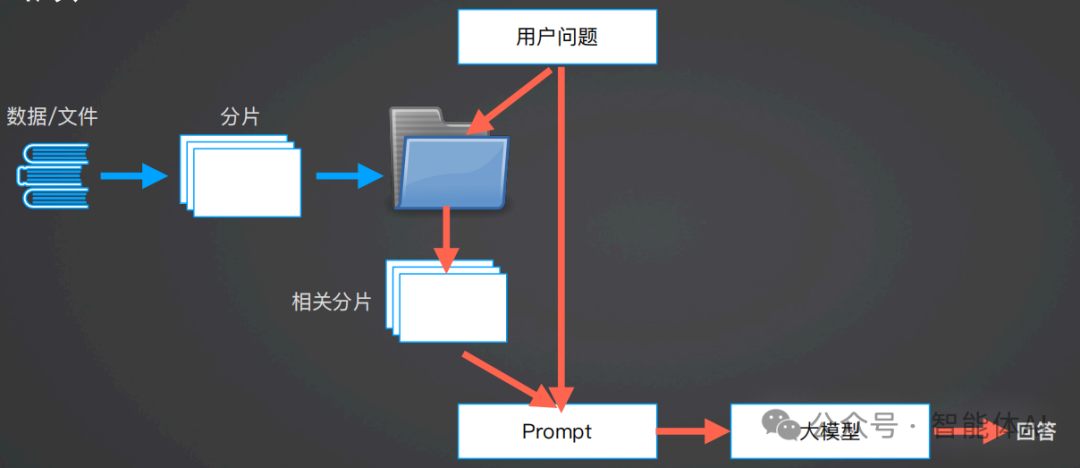
1、数据/文件:这是整个系统的原始数据来源,可能是各种类型的文档、文本数据、数据库等。2、分片:原始数据会被切分成更小的片段。这一步的目的是为了便于后续的处理和检索。4、用户问题:用户向系统提出的问题,触发系统开始处理和回答。5、相关分片:系统从存储的文件夹中检索出与用户问题相关的片段。这一步通常涉及使用向量数据库或其他搜索算法来找到与问题最匹配的内容片段。6、Prompt:相关片段和用户问题被组合成一个提示(Prompt),用于引导大模型生成回答。这个提示可能包括上下文信息和问题本身。7、大模型:大模型(如GPT-4)接收Prompt并生成回答。大模型利用其训练中学到的知识和提示中提供的上下文信息来生成响应。这个流程展示了如何利用大模型和向量数据库等技术来实现一个高效的问答系统,通过分片、检索和提示等步骤来生成高质量的回答。import openaiimport osfrom math import *from pdfminer.high_level import extract_pagesfrom pdfminer.layout import LTTextContainerimport warningsimport chromadbfrom nltk.tokenize import sent_tokenizeimport json
# 加载 .env 文件from dotenv import load_dotenv, find_dotenv_ = load_dotenv(find_dotenv())
warnings.simplefilter("ignore") # 屏蔽 ES 的一些Warnings# 从环境变量中获得你的 OpenAI Keyopenai.api_key = os.getenv('OPENAI_API_KEY')openai.api_base = os.getenv('OPENAI_API_URL')model = os.getenv('MODEL')
#首先要先启动chroma run --path /db_pathclass MyVectorDBConnector:def __init__(self, collection_name, embedding_fn):"""初始化向量数据库连接器。
参数:- collection_name: 数据库集合名称。- embedding_fn: 文本嵌入函数。"""chroma_client = chromadb.HttpClient(host='localhost', port=8000)
# 创建一个 collectionself.collection = chroma_client.get_or_create_collection(name="demo_text_split")self.embedding_fn = embedding_fn
def add_documents(self, documents, metadata={}):"""向 collection 中添加文档与向量。
参数:- documents: 要添加的文档列表。- metadata: 元数据字典(可选)。"""self.collection.add(embeddings=self.embedding_fn(documents), # 每个文档的向量documents=documents, # 文档的原文ids=[f"id{i}" for i in range(len(documents))] # 每个文档的 id)
def search(self, query, top_n):"""检索向量数据库。
参数:- query: 查询文本。- top_n: 返回结果的数量。
返回:- 检索结果。"""results = self.collection.query(query_embeddings=self.embedding_fn([query]),n_results=top_n)return results
def split_text(paragraphs,chunk_size=300,overlap_size=100):'''按指定 chunk_size 和 overlap_size 交叠割文本'''sentences = [s.strip() for p in paragraphs for s in sent_tokenize(p)]chunks = []i= 0while i < len(sentences):chunk = sentences[i]overlap = ''prev_len = 0prev = i - 1# 向前计算重叠部分while prev >= 0 and len(sentences[prev])+len(overlap) <= overlap_size:overlap = sentences[prev] + ' ' + overlapprev -= 1chunk = overlap+chunknext = i + 1# 向后计算当前chunkwhile next < len(sentences) and len(sentences[next])+len(chunk) <= chunk_size:chunk = chunk + ' ' + sentences[next]next += 1chunks.append(chunk)i = nextreturn chunks
def get_completion(prompt, model=model):"""获取完成的回复。
参数:- prompt: 提示信息。- model: 使用的 OpenAI 模型。
返回:- 模型生成的回复内容。"""messages = [{"role": "user", "content": prompt}]
response = openai.ChatCompletion.create(model=model,messages=messages,temperature=0,# 模型输出的随机性,0 表示随机性最小)return response.choices[0].message["content"]
def build_prompt(prompt_template, **kwargs):"""将 Prompt 模板赋值。
参数:- prompt_template: Prompt 模板字符串。- kwargs: 关键字参数,用于替换模板中的变量。
返回:- 替换后的 Prompt 字符串。"""prompt = prompt_templatefor k, v in kwargs.items(): if isinstance(v,str):val = velif isinstance(v, list) and all(isinstance(elem, str) for elem in v):val = '\n'.join(v)else:val = str(v)prompt = prompt.replace(f"__{k.upper()}__",val)return prompt
class RAG_Bot:def __init__(self, vector_db, llm_api, n_results=2):"""初始化 RAG 机器人。
参数:- vector_db: 向量数据库对象。- llm_api: 语言模型 API。- n_results: 检索结果数量,默认为 2。"""self.vector_db = vector_dbself.llm_api = llm_apiself.n_results = n_resultsdef chat(self, user_query):"""与用户进行对话。
参数:- user_query: 用户的查询。
返回:- 机器人回复的内容。"""# 1. 检索search_results = self.vector_db.search(user_query,self.n_results)prompt_template = """你是一个问答机器人。你的任务是根据下述给定的已知信息回答用户问题。确保你的回复完全依据下述已知信息。不要编造答案。如果下述已知信息不足以回答用户的问题,请直接回复"我无法回答您的问题"。
已知信息:__INFO__
用户问:__QUERY__
请用中文回答用户问题。"""
# 2. 构建 Promptprompt = build_prompt(prompt_template, info=search_results['documents'][0], query=user_query)# 3. 调用 LLMresponse = self.llm_api(prompt)return response
def get_embeddings(texts, model="text-embedding-ada-002"):"""封装 OpenAI 的 Embedding 模型接口。
参数:- texts: 要嵌入的文本列表。- model: 使用的嵌入模型,默认为 "text-embedding-ada-002"。
返回:- 嵌入向量列表。"""data = openai.Embedding.create(input = texts, model=model).datareturn [x.embedding for x in data]
def init_db():"""初始化数据库,从 PDF 中提取文本并添加到向量数据库。"""# 为了演示方便,我们只取两页(第一章)paragraphs = extract_text_from_pdf(r"E:\vspythonwork\llama2.pdf",page_numbers=[2,3],min_line_length=10)chunks = split_text(paragraphs,300,100)# 创建一个向量数据库对象vector_db = MyVectorDBConnector("demo_text_split",get_embeddings)# 向向量数据库中添加文档vector_db.add_documents(chunks)user_query = "Llama 2有多少参数"results = vector_db.search(user_query, 2)for para in results['documents'][0]:print(para+"\n")
def query(user_query):"""用户查询接口,向量数据库中查询与用户查询相关的文档。
参数:- user_query: 用户的查询。"""vector_db = MyVectorDBConnector("demo_text_split",get_embeddings)results = vector_db.search(user_query, 2)for para in results['documents'][0]:print(para+"\n")
def extract_text_from_pdf(filename,page_numbers=None,min_line_length=1):"""从 PDF 文件中(按指定页码)提取文字。
参数:- filename: PDF 文件名。- page_numbers: 要提取的页码列表,默认为 None(提取所有页)。- min_line_length: 最小行长度,默认为 1。
返回:- 提取的段落列表。"""paragraphs = []buffer = ''full_text = ''# 提取全部文本for i, page_layout in enumerate(extract_pages(filename)):# 如果指定了页码范围,跳过范围外的页if page_numbers is not None and i not in page_numbers:continuefor element in page_layout:if isinstance(element, LTTextContainer):full_text += element.get_text() + '\n'# 按空行分隔,将文本重新组织成段落lines = full_text.split('\n')for text in lines:if len(text) >= min_line_length:buffer += (' '+text) if not text.endswith('-') else text.strip('-')elif buffer: paragraphs.append(buffer)buffer = ''if buffer:paragraphs.append(buffer)return paragraphs
def test_promopt():"""测试 Prompt 构建和 RAG 机器人功能。"""# 创建一个RAG机器人vector_db = MyVectorDBConnector("demo_text_split",get_embeddings)bot = RAG_Bot(vector_db,llm_api=get_completion)#user_query="llama 2有多少参数?"#user_query = "how many parameters does llama 2 have?"user_query="llama 2可以商用吗?"response = bot.chat(user_query)print(response)
def test_promopt2():"""测试 Prompt 构建和 RAG 机器人功能。"""# 创建一个RAG机器人vector_db = MyVectorDBConnector("demo_text_split",get_embeddings)bot = RAG_Bot(vector_db,llm_api=get_completion)user_query="llama 2有多少参数?"#user_query = "how many parameters does llama 2 have?"#user_query="llama 2可以商用吗?"response = bot.chat(user_query)print(response)
if __name__ == '__main__':#init_db() # 第一次才要初始化,之后可以注释掉#首先要先启动chroma run --path /db_path# user_query = "Llama 2有多少参数"# query(user_query)test_promopt()
基于大模型和向量数据库的问答系统通过数据切分、向量化、智能检索和大模型生成回答,实现了高效、准确和灵活的问答服务。它在多个领域展现了强大的应用潜力和价值,成为现代智能系统的重要组成部分。通过不断优化和提升,这类系统将在未来发挥更加重要的作用。
| 









