对于 RAG(Retrieval-Augmented Generation,检索增强生成)来说,从文档中提取信息是一个不可避免的步骤。确保从源文档中有效提取内容对于提高最终的输出质量至关重要。
在实施 RAG 时,不应低估这一过程。在解析过程中信息提取不佳可能导致对 PDF 文件中所含信息的理解和利用受限。
RAG 中解析过程的位置如图 1 所示:
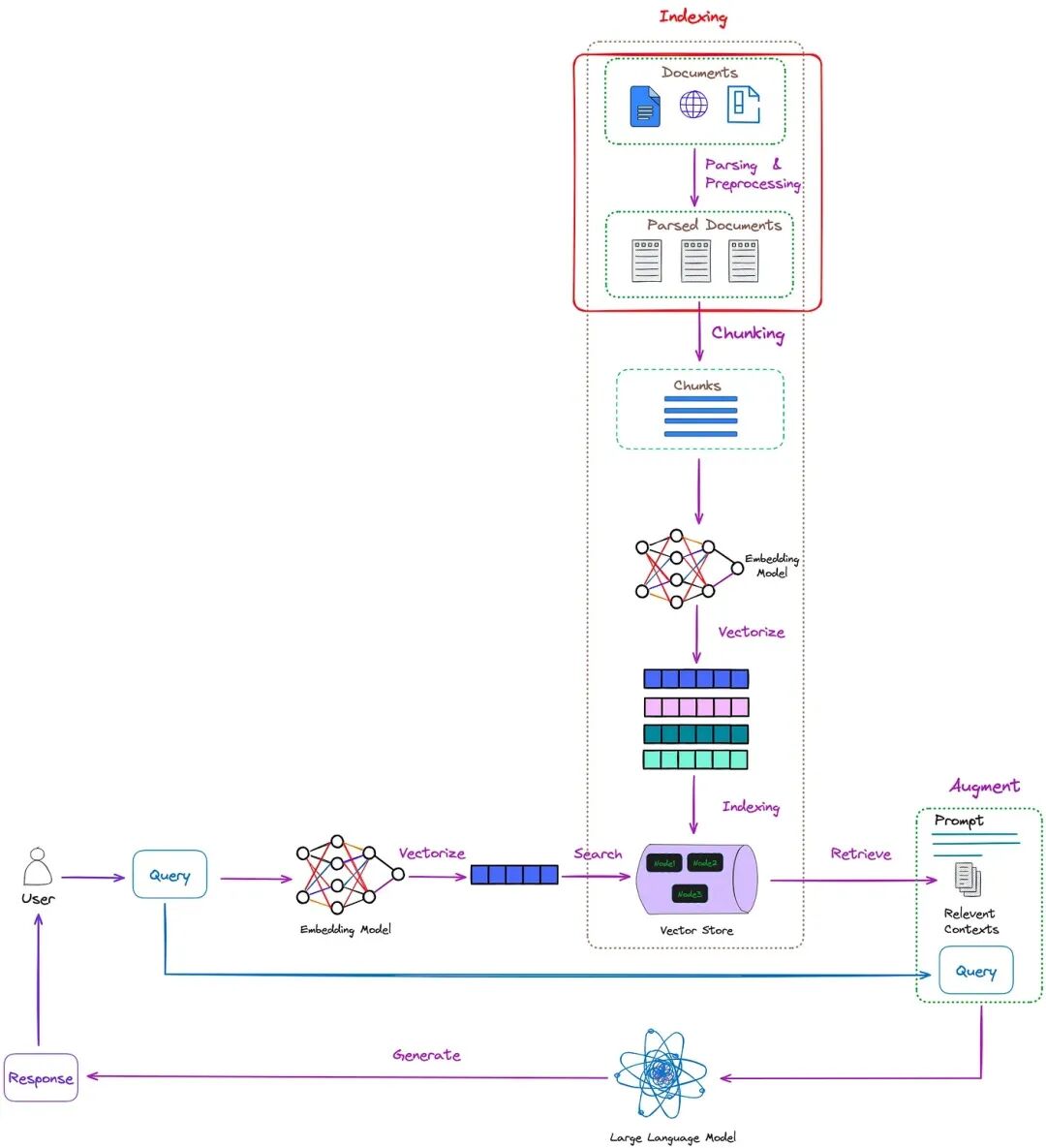
图1
在实际工作中,非结构化数据比结构化数据要丰富得多。如果无法解析这些大量的数据,它们巨大的价值就无法实现。
在非结构化数据中,PDF 文件占了大多数。 有效处理 PDF 文件也可以极大地帮助管理其他类型的非结构化文档。
本文主要介绍了解析 PDF 文件的方法。它提供了有效解析 PDF 文档和尽可能多地提取有用信息的算法和建议。
解析 PDF 的挑战
PDF 文档是非结构化文档的代表,然而,从 PDF 文档中提取信息是一个具有挑战性的过程。
将 PDF 简单定义为数据格式并不准确,更恰当的描述是它是一套打印指令的组合。PDF 文件由一系列指令组成,这些指令告诉 PDF 阅读器或打印机在屏幕或纸张上如何及在哪里呈现字符。这与如 HTML 和 docx 等文件格式不同,后者使用标签来组织不同的逻辑结构,如图2所示。

图2
解析 PDF 文档的难点主要在于如何精确地捕捉页面的整体布局,并将包括表格、标题、段落及图片在内的内容转译为文档的文字形式。这一过程包括处理文本抽取的不精确、图像的识别问题,以及表格中行与列关系的识别混乱。
如何解析 PDF 文档
通常,有三种解析 PDF 的方法:
- 基于规则的方法:这种方法依据文档的组织特性来确定每个部分的样式和内容。但是,鉴于 PDF 的种类和布局千差万别,这种方法的适用性较差,很难通过预设的规则覆盖所有情形。
- 基于深度学习模型的方法:比如,一个流行的解决方案是结合了物体检测和 OCR(光学字符识别)模型。
- 基于多模态大模型的方法:通过这种方法可以解析 PDF 中的复杂结构或提取关键信息。
基于规则的方法
其中最具代表性的工具之一是pypdf,这是一个广泛使用的基于规则的解析器。它是LangChain和LlamaIndex中解析PDF文件的标准方法。
下面是使用 pypdf 解析《Attention Is All You Need》论文第6页的尝试。原始页面如图3所示。

图3
代码如下:
importPyPDF2
filename="/Users/Florian/Downloads/1706.03762.pdf"
pdf_file=open(filename,'rb')
reader=PyPDF2.PdfReader(pdf_file)
page_num=5
page=reader.pages[page_num]
text=page.extract_text()
print('--------------------------------------------------')
print(text)
pdf_file.close()
执行的结果是(为简洁起见省略其余部分):
(py)Florian:~Florian$piplist|greppypdf
pypdf3.17.4
pypdfium24.26.0
(py)Florian:~Florian$python/Users/Florian/Downloads/pypdf_test.py
--------------------------------------------------
Table1:Maximumpathlengths,per-layercomplexityandminimumnumberofsequentialoperations
fordifferentlayertypes.nisthesequencelength,distherepresentationdimension,kisthekernel
sizeofconvolutionsandrthesizeoftheneighborhoodinrestrictedself-attention.
LayerTypeComplexityperLayerSequentialMaximumPathLength
Operations
Self-AttentionO(n2·d)O(1)O(1)
RecurrentO(n·d2)O(n)O(n)
ConvolutionalO(k·n·d2)O(1)O(logk(n))
Self-Attention(restricted)O(r·n·d)O(1)O(n/r)
3.5PositionalEncoding
Sinceourmodelcontainsnorecurrenceandnoconvolution,inorderforthemodeltomakeuseofthe
orderofthesequence,wemustinjectsomeinformationabouttherelativeorabsolutepositionofthe
tokensinthesequence.Tothisend,weadd"positionalencodings"totheinputembeddingsatthe
bottomsoftheencoderanddecoderstacks.Thepositionalencodingshavethesamedimensiondmodel
astheembeddings,sothatthetwocanbesummed.Therearemanychoicesofpositionalencodings,
learnedandfixed[9].
Inthiswork,weusesineandcosinefunctionsofdifferentfrequencies:
PE(pos,2i)=sin(pos/100002i/dmodel)
PE(pos,2i+1)=cos(pos/100002i/dmodel)
whereposisthepositionandiisthedimension.Thatis,eachdimensionofthepositionalencoding
correspondstoasinusoid.Thewavelengthsformageometricprogressionfrom2πto10000·2π.We
chosethisfunctionbecausewehypothesizeditwouldallowthemodeltoeasilylearntoattendby
relativepositions,sinceforanyfixedoffsetk,PEpos+kcanberepresentedasalinearfunctionof
PEpos.
...
...
...
根据 PyPDF 检测的结果,可以观察到它将 PDF 中的字符序列序列化成一个长序列,而没有保留结构信息。换句话说,它将文档的每一行视为由换行符“\n”分隔的序列,这阻碍了对段落或表格的准确识别。
这一限制是基于规则方法的固有特性。
基于深度学习模型的方法
这种方法的优势是它能够准确地识别整个文档的布局,包括表格和段落。它甚至能理解表格内的结构。这意味着它能将文档划分为定义明确、信息完整的单元,同时保留预期的意义和结构。
然而,也存在一些局限性。对象检测和 OCR 阶段可能会耗时。因此,建议使用GPU或其他加速设备,并采用多进程和多线程进行处理。
这种方法涉及对象检测和 OCR 模型,我已经测试了几个代表性的开源框架:
- Unstructured:它已被集成到langchain中。在启用 infer_table_structure=True 的 hi_res 策略下,表格识别效果良好。然而,fast 策略表现不佳,因为它没有使用对象检测模型,错误地识别了许多图像和表格。
- Layout-parser:如果需要识别复杂结构的 PDF,建议使用最大的模型以获得更高的准确性,尽管可能会稍慢一些。此外,Layout-parser的模型 在过去两年中似乎没有更新。
- PP-StructureV2:采用多种模型组合进行文档分析,性能优于平均水平。架构展示于图4:
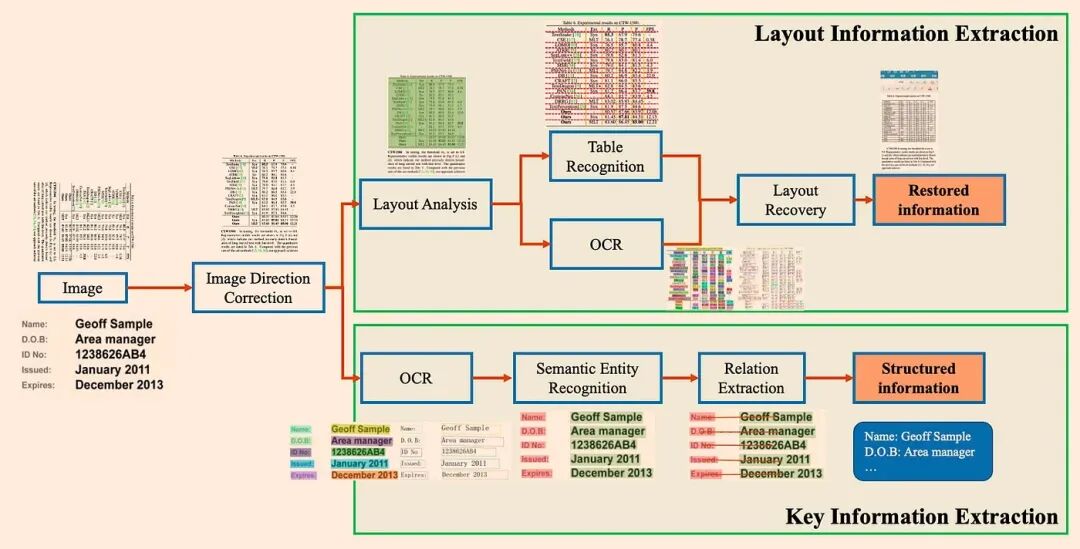
图4
除了开源工具之外,还有一些如 ChatDOC 这样的付费工具,采用基于布局的识别加上OCR 技术来解析 PDF 文档。
下面,我们将介绍如何利用开源的 unstructured 框架来解析 PDF,并针对三大关键挑战进行说明。
挑战1:如何从表格和图片中抽取数据
这里,我们将使用 unstructured 框架作为例子。检测到的表格数据能够被直接导出为HTML格式。具体的代码实现如下:
fromunstructured.partition.pdfimportpartition_pdf
filename="/Users/Florian/Downloads/Attention_Is_All_You_Need.pdf"
#infer_table_structure=Trueautomaticallyselectshi_resstrategy
elements=partition_pdf(filename=filename,infer_table_structure=True)
tables=[elforelinelementsifel.category=="Table"]
print(tables[0].text)
print('--------------------------------------------------')
print(tables[0].metadata.text_as_html)
我已经详细跟踪了 partition_pdf 函数的内部执行流程。图5展示了其基础流程图。
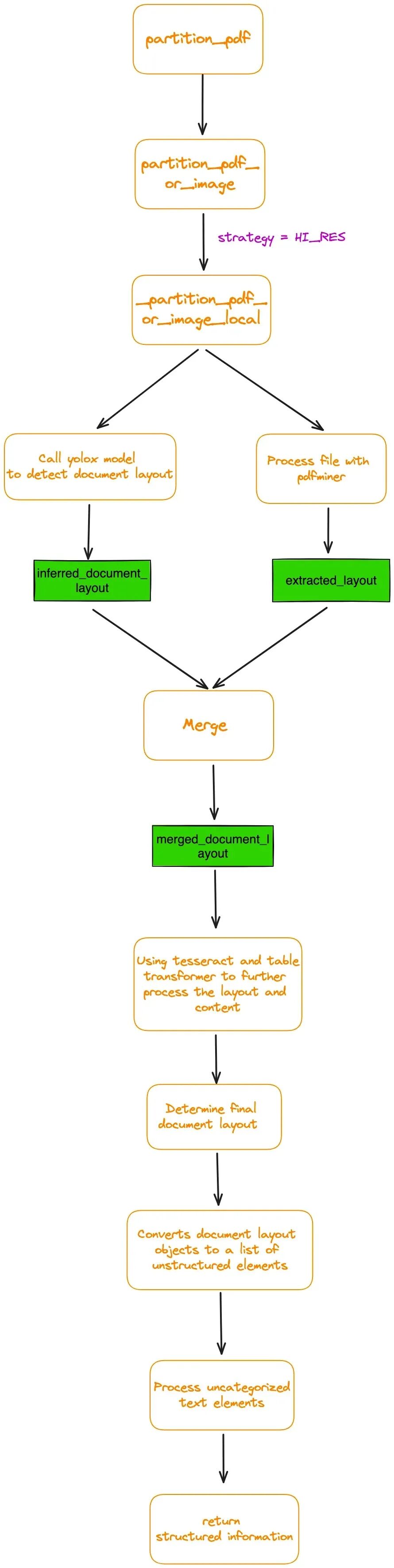
图5
代码的运行结果如下:
LayerTypeSelf-AttentionRecurrentConvolutionalSelf-Attention(restricted)ComplexityperLayerO(n2·d)O(n·d2)O(k·n·d2)O(r·n·d)SequentialMaximumPathLengthOperationsO(1)O(n)O(1)O(1)O(1)O(n)O(logk(n))O(n/r)
--------------------------------------------------
<table><thead><th>LayerType</th><th>ComplexityperLayer</th><th>SequentialOperations</th><th>MaximumPathLength</th></thead><tr><td>Self-Attention</td><td>O(n?-d)</td><td>O(1)</td><td>O(1)</td></tr><tr><td>Recurrent</td><td>O(n-d?)</td><td>O(n)</td><td>O(n)</td></tr><tr><td>Convolutional</td><td>O(k-n-d?)</td><td>O(1)</td><td>O(logy(n))</td></tr><tr><td>Self-Attention(restricted)</td><td>O(r-n-d)</td><td>ol)</td><td>O(n/r)</td></tr></table>
复制 HTML 标签并将它们保存为 HTML 文件。然后,使用 Chrome 打开它,结果如图6所示:

图6
可以观察到,unstructured 算法基本上恢复了整个表格。
挑战2:如何对检测到的内容块进行重新排列?特别是在处理双栏PDF文件时。
在处理双栏PDF时,以论文《BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding》为例。阅读顺序由红色箭头显示:

图7
在确定了布局之后,unstructured 框架会将每个页面划分为若干个矩形区块,详细展示请见图8。

图8
每个矩形块的详细信息可以通过以下格式获取:
[
LayoutElement(bbox=Rectangle(x1=851.1539916992188,y1=181.15073777777613,x2=1467.844970703125,y2=587.8204599999975),text='Theseapproacheshavebeengeneralizedtocoarsergranularities,suchassentenceembed-dings(Kirosetal.,2015;LogeswaranandLee,2018)orparagraphembeddings(LeandMikolov,2014).Totrainsentencerepresentations,priorworkhasusedobjectivestorankcandidatenextsentences(Jerniteetal.,2017;LogeswaranandLee,2018),left-to-rightgenerationofnextsen-tencewordsgivenarepresentationoftheprevioussentence(Kirosetal.,2015),ordenoisingauto-encoderderivedobjectives(Hilletal.,2016).',source=<Source.YOLOX:'yolox'>,type='Text',prob=0.9519357085227966,image_path=None,parent=None),
LayoutElement(bbox=Rectangle(x1=196.5296173095703,y1=181.1507377777777,x2=815.468994140625,y2=512.548237777777),text='wordbasedonlyonitscontext.Unlikeleft-to-rightlanguagemodelpre-training,theMLMob-jectiveenablestherepresentationtofusetheleftandtherightcontext,whichallowsustopre-Inaddi-trainadeepbidirectionalTransformer.tiontothemaskedlanguagemodel,wealsousea“nextsentenceprediction”taskthatjointlypre-trainstext-pairrepresentations.Thecontributionsofourpaperareasfollows:',source=<Source.YOLOX:'yolox'>,type='Text',prob=0.9517233967781067,image_path=None,parent=None),
LayoutElement(bbox=Rectangle(x1=200.22352600097656,y1=539.1451822222216,x2=825.0242919921875,y2=870.542682222221),text='•Wedemonstratetheimportanceofbidirectionalpre-trainingforlanguagerepresentations.Un-likeRadfordetal.(2018),whichusesunidirec-tionallanguagemodelsforpre-training,BERTusesmaskedlanguagemodelstoenablepre-traineddeepbidirectionalrepresentations.ThisisalsoincontrasttoPetersetal.(2018a),whichusesashallowconcatenationofindependentlytrainedleft-to-rightandright-to-leftLMs.',source=<Source.YOLOX:'yolox'>,type='List-item',prob=0.9414362907409668,image_path=None,parent=None),
LayoutElement(bbox=Rectangle(x1=851.8727416992188,y1=599.8257377777753,x2=1468.0499267578125,y2=1420.4982377777742),text='ELMoanditspredecessor(Petersetal.,2017,2018a)generalizetraditionalwordembeddingre-searchalongadifferentdimension.Theyextractcontext-sensitivefeaturesfromaleft-to-rightandaright-to-leftlanguagemodel.Thecontextualrep-resentationofeachtokenistheconcatenationoftheleft-to-rightandright-to-leftrepresentations.Whenintegratingcontextualwordembeddingswithexistingtask-specificarchitectures,ELMoadvancesthestateoftheartforseveralmajorNLPbenchmarks(Petersetal.,2018a)includingques-tionanswering(Rajpurkaretal.,2016),sentimentanalysis(Socheretal.,2013),andnamedentityrecognition(TjongKimSangandDeMeulder,2003).Melamudetal.(2016)proposedlearningcontextualrepresentationsthroughatasktopre-dictasinglewordfrombothleftandrightcontextusingLSTMs.SimilartoELMo,theirmodelisfeature-basedandnotdeeplybidirectional.Fedusetal.(2018)showsthattheclozetaskcanbeusedtoimprovetherobustnessoftextgenerationmod-els.',source=<Source.YOLOX:'yolox'>,type='Text',prob=0.938507616519928,image_path=None,parent=None),
LayoutElement(bbox=Rectangle(x1=199.3734130859375,y1=900.5257377777765,x2=824.69873046875,y2=1156.648237777776),text='•Weshowthatpre-trainedrepresentationsreducetheneedformanyheavily-engineeredtask-specificarchitectures.BERTisthefirstfine-tuningbasedrepresentationmodelthatachievesstate-of-the-artperformanceonalargesuiteofsentence-levelandtoken-leveltasks,outper-formingmanytask-specificarchitectures.',source=<Source.YOLOX:'yolox'>,type='List-item',prob=0.9461237788200378,image_path=None,parent=None),
LayoutElement(bbox=Rectangle(x1=195.5695343017578,y1=1185.526123046875,x2=815.9393920898438,y2=1330.3272705078125),text='•BERTadvancesthestateoftheartforelevenNLPtasks.Thecodeandpre-trainedmod-elsareavailableathttps://github.com/google-research/bert.',source=<Source.YOLOX:'yolox'>,type='List-item',prob=0.9213815927505493,image_path=None,parent=None),
LayoutElement(bbox=Rectangle(x1=195.33956909179688,y1=1360.7886962890625,x2=447.47264000000007,y2=1397.038330078125),text='2RelatedWork',source=<Source.YOLOX:'yolox'>,type='Section-header',prob=0.8663332462310791,image_path=None,parent=None),
LayoutElement(bbox=Rectangle(x1=197.7477264404297,y1=1419.3353271484375,x2=817.3308715820312,y2=1527.54443359375),text='Thereisalonghistoryofpre-traininggenerallan-guagerepresentations,andwebrieflyreviewthemostwidely-usedapproachesinthissection.',source=<Source.YOLOX:'yolox'>,type='Text',prob=0.928022563457489,image_path=None,parent=None),
LayoutElement(bbox=Rectangle(x1=851.0028686523438,y1=1468.341394166663,x2=1420.4693603515625,y2=1498.6444497222187),text='2.2UnsupervisedFine-tuningApproaches',source=<Source.YOLOX:'yolox'>,type='Section-header',prob=0.8346447348594666,image_path=None,parent=None),
LayoutElement(bbox=Rectangle(x1=853.5444444444446,y1=1526.3701822222185,x2=1470.989990234375,y2=1669.5843488888852),text='Aswiththefeature-basedapproaches,thefirstworksinthisdirectiononlypre-trainedwordem-(Col-beddingparametersfromunlabeledtextlobertandWeston,2008).',source=<Source.YOLOX:'yolox'>,type='Text',prob=0.9344717860221863,image_path=None,parent=None),
LayoutElement(bbox=Rectangle(x1=200.00000000000009,y1=1556.2037353515625,x2=799.1743774414062,y2=1588.031982421875),text='2.1UnsupervisedFeature-basedApproaches',source=<Source.YOLOX:'yolox'>,type='Section-header',prob=0.8317819237709045,image_path=None,parent=None),
LayoutElement(bbox=Rectangle(x1=198.64227294921875,y1=1606.3146266666645,x2=815.2886352539062,y2=2125.895459999998),text='Learningwidelyapplicablerepresentationsofwordshasbeenanactiveareaofresearchfordecades,includingnon-neural(Brownetal.,1992;AndoandZhang,2005;Blitzeretal.,2006)andneural(Mikolovetal.,2013 enningtonetal.,2014)methods.Pre-trainedwordembeddingsareanintegralpartofmodernNLPsystems,of-feringsignificantimprovementsoverembeddingslearnedfromscratch(Turianetal.,2010).Topre-trainwordembeddingvectors,left-to-rightlan-guagemodelingobjectiveshavebeenused(MnihandHinton,2009),aswellasobjectivestodis-criminatecorrectfromincorrectwordsinleftandrightcontext(Mikolovetal.,2013).',source=<Source.YOLOX:'yolox'>,type='Text',prob=0.9450697302818298,image_path=None,parent=None),
enningtonetal.,2014)methods.Pre-trainedwordembeddingsareanintegralpartofmodernNLPsystems,of-feringsignificantimprovementsoverembeddingslearnedfromscratch(Turianetal.,2010).Topre-trainwordembeddingvectors,left-to-rightlan-guagemodelingobjectiveshavebeenused(MnihandHinton,2009),aswellasobjectivestodis-criminatecorrectfromincorrectwordsinleftandrightcontext(Mikolovetal.,2013).',source=<Source.YOLOX:'yolox'>,type='Text',prob=0.9450697302818298,image_path=None,parent=None),
LayoutElement(bbox=Rectangle(x1=853.4905395507812,y1=1681.5868488888855,x2=1467.8729248046875,y2=2125.8954599999965),text='Morerecently,sentenceordocumentencoderswhichproducecontextualtokenrepresentationshavebeenpre-trainedfromunlabeledtextandfine-tunedforasuperviseddownstreamtask(DaiandLe,2015;HowardandRuder,2018;Radfordetal.,2018).Theadvantageoftheseapproachesisthatfewparametersneedtobelearnedfromscratch.Atleastpartlyduetothisadvantage,OpenAIGPT(Radfordetal.,2018)achievedpre-viouslystate-of-the-artresultsonmanysentence-leveltasksfromtheGLUEbenchmark(Wanglanguagemodel-Left-to-rightetal.,2018a).',source=<Source.YOLOX:'yolox'>,type='Text',prob=0.9476840496063232,image_path=None,parent=None)
]
其中(x1, y1)代表左上角顶点的坐标,而(x2, y2)则是右下角顶点的坐标:
(x_1,y_1)--------
||
||
||
----------(x_2,y_2)
此时,您可以选择重新排列页面的阅读顺序。Unstructured 自带一个内置的排序算法,但我发现在处理双栏情况时排序结果并不令人满意。
因此,需要设计一个算法。最简单的方法是首先按左上顶点的水平坐标排序,如果水平坐标相同,则按垂直坐标排序。其伪代码如下:
layout.sort(key=lambdaz z.bbox.x1,z.bbox.y1,z.bbox.x2,z.bbox.y2))
z.bbox.x1,z.bbox.y1,z.bbox.x2,z.bbox.y2))
然而,我们发现即使是同一列中的块也可能在它们的水平坐标上有变化。如图9所示,紫色线块的水平坐标 bbox.x1 实际上更靠左。在排序时,它会被放置在绿色线块之前,这显然违反了阅读顺序。

图9
在这种情况下,一种可行的算法步骤如下:
- 首先,对所有左上角的 x 坐标 x1 进行排序,以此确定最小的 x1(x1_min)。
- 然后,对所有右下角的 x 坐标 x2 进行排序,以此确定最大的 x2(x2_max)。
- 接下来,我们需要计算页面中央线的x坐标,具体方法是:
x1_min=min([el.bbox.x1forelinlayout])
x2_max=max([el.bbox.x2forelinlayout])
mid_line_x_coordinate=(x2_max+x1_min)/2
接下来,如果 bbox.x1 < mid_line_x_coordinate,则将该块归类为左列的一部分。否则,它被视为右列的一部分。
一旦分类完成,根据它们的y坐标对列中的每个块进行排序。最后,将右列连接到左列的右侧。
left_column=[]
right_column=[]
forelinlayout:
ifel.bbox.x1<mid_line_x_coordinate:
left_column.append(el)
else:
right_column.append(el)
left_column.sort(key=lambdaz:z.bbox.y1)
right_column.sort(key=lambdaz:z.bbox.y1)
sorted_layout=left_column+right_column
值得一提的是,这种改进同样适用于单栏 PDF。
挑战3:如何提取多级标题
提取标题,包括多级标题的目的是为了提高大语言模型(LLM)回答的准确性。
例如,如果用户想要了解图9中第2.1节的主要内容,通过准确提取第2.1节的标题,并将其与相关内容一起作为上下文发送给 LLM,最终答案的准确性将显著提高。
该算法仍然依赖于图9中显示的布局块。我们可以提取类型为 'Section-header' 的块,并计算高度差(bbox.y2 - bbox.y1)。高度差最大的块对应于一级标题,其次是二级标题,然后是三级标题。
基于多模态大模型解析PDF中的复杂结构
多模态模型兴起后,也可以使用多模态模型来解析表格。以下是几个选项:
- 检索相关图像(PDF页面)并将其发送给 GPT4-V 来响应查询。
- 将每个 PDF 页面视为一张图像,让 GPT4-V 对每一页进行图像推理。为图像推理构建向量索引。针对向量索引来查询答案。
- 使用表格变换器从检索到的图像中裁剪表格信息,然后将这些裁剪的图像发送给 GPT4-V 进行查询响应。
- 在裁剪的表格图像上应用 OCR,并将数据发送给 GPT4/GPT-3.5 以回答查询。
经过测试,可以确定的是第三种方法最为有效。
此外,我们可以使用多模态模型从图像中提取或总结关键信息(PDF 文件可以轻松转换为图像),如图10所示。

图10
结论
总体上,非结构化文档极具灵活性,其解析需采用多种技术。目前尚无统一意见确定哪一种是最佳方法。
因此,选择一种最符合您项目需求的方法显得尤为重要。不同类型的 PDF 文件,如学术论文、书籍及财务报表,应根据其特定特性采取相应的处理策略。
如果条件允许,推荐使用基于深度学习或多模态的技术。这些技术能够有效地对文档进行分割,确保信息单元的完整性和清晰度,最大限度地保留文档原有的意图和结构。










