ingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;letter-spacing: 0.544px;text-wrap: wrap;background-color: rgb(255, 255, 255);visibility: visible;margin-bottom: 0px;text-align: center;">什么是KV Cache
ingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;letter-spacing: 0.544px;text-wrap: wrap;background-color: rgb(255, 255, 255);visibility: visible;margin-bottom: 0px;">
ingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;letter-spacing: 0.544px;text-wrap: wrap;background-color: rgb(255, 255, 255);visibility: visible;margin-bottom: 0px;">KV cache,即键值对缓存(Key-Value Cache),是一种存储结构,用于快速访问数据。在计算机科学中,键值对是一种数据结构,其中每个键(Key)映射到一个值(Value)。缓存是一种临时存储数据的方法,以便快速访问,减少对原始数据源的访问次数,提高系统性能。ingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;letter-spacing: 0.544px;text-wrap: wrap;background-color: rgb(255, 255, 255);visibility: visible;margin-bottom: 0px;">
ingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;letter-spacing: 0.544px;text-wrap: wrap;background-color: rgb(255, 255, 255);visibility: visible;margin-bottom: 0px;">在大模型领域,KV Cache是一种推理优化手段。ingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;letter-spacing: 0.544px;text-wrap: wrap;background-color: rgb(255, 255, 255);visibility: visible;margin-bottom: 0px;">
ingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;letter-spacing: 0.544px;text-wrap: wrap;background-color: rgb(255, 255, 255);visibility: visible;margin-bottom: 0px;">在大模型推理的时候,我们最看重的是两个指标:
ingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;letter-spacing: 0.544px;text-wrap: wrap;background-color: rgb(255, 255, 255);visibility: visible;margin-bottom: 0px;">ingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;letter-spacing: 0.544px;text-wrap: wrap;background-color: rgb(255, 255, 255);visibility: visible;margin-bottom: 0px;">ingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;letter-spacing: 0.544px;text-wrap: wrap;background-color: rgb(255, 255, 255);visibility: visible;margin-bottom: 0px;">一个是吞吐量:吞出量是针对后端系统而言的。吞吐量代表了大模型单位时间内处理Tokens的数量,这里的Tokens一般指输入和输出Tokens数量的总和,在Infra条件一样的情况下,吞吐量越大,大模型推理系统的资源利用效率更高,推理的成本也就是更低(毕竟推理主要就是看成本)一个时延:时延是针对最终用户而言的。时延用户平均收到每个Token所花费的时间,业务通常认为这个数值如果小于50ms,则用户可以收获相对良好的使用体验。Transformer模型的显著特性在于,每次推理过程仅生成一个token作为输出。该token随后与之前生成的所有tokens结合,形成下一轮推理的输入。这个过程不断重复,直至生成完整的输出序列。然而,由于每轮的输入仅比上一轮多出一个token,导致了大量的冗余计算。KV Cache技术的出现正是为了解决这一问题,它通过存储可复用的键值向量,有效避免了这些不必要的重复计算,显著提高了推理的效率。 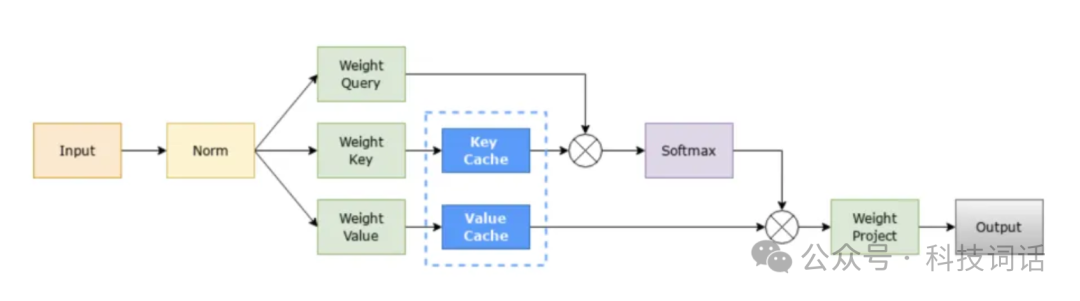
如果没有KV缓存,每次生成新token时,都需要重新计算所有token的键和值,这会导致计算复杂度呈平方增长。而KV缓存通过存储之前生成的token的键和值,使得新token的生成只需要与这些缓存的数据进行交互,从而将复杂度降低到线性。 推理的两个阶段 KV Cache技术的引入,将推理过程分为两个阶段,为进一步优化提供了新的可能。 预填充阶段(Prefill):典型特点为compute-bound。在生成第一个输出token的过程中,该阶段启动。在此阶段,系统会为每个Transformer层精确计算并存储key cache和value cache。此时的浮点运算次数(FLOPs)与未使用KV Cache时保持一致,涉及大量的通用矩阵乘法(GEMM)操作,属于计算密集型任务,需要FP16或者Int8算力值更大的GPU芯片。 解码阶段(Decode):典型特点为memory-bound。当生成第二个输出token开始,直至生成最后一个token,该阶段便启动。此时,由于KV Cache已经存储了之前所有轮次的键值结果,每轮推理只需从Cache中读取数据,并将新计算出的Key和Value添加到Cache中。这导致每轮的FLOPs降低,推理速度比预填充阶段快得多,此时的计算转变为内存密集型,因为需要存储更多的数据,需要显存更大的GPU芯片。 KV Cache不是完美银弹 虽然KV缓存可以显著提高模型的运行效率,但它也带来了内存占用的问题。KV缓存的大小随着序列长度的增加而线性增长,有时甚至可以达到模型大小的数倍。这种内存占用在推理场景中尤为常见,尤其是在显存受限的情况下,KV缓存的大小可能成为制约模型性能的瓶颈。 
KV Cache的优化策略:为了解决KV缓存带来的内存问题,研究人员提出了多种优化策略。例如,通过量化技术减少模型权重和KV缓存的内存占用,或者采用模型并行技术将模型分片到多个GPU上。此外,还有研究专注于KV缓存的压缩和内存管理,如FastGen方法,它通过自适应压缩技术,减少了KV缓存的内存需求,同时保持了模型的效率。
|










