|

Hi,这里是Aitrainee,欢迎阅读本期新文章。 在这里我会告诉你如何用10行代码实现一个完整的文档聊天系统,这一切都在Python中完成,不使用任何框架如LangChain、LamaIndex或向量存储如Chroma。 首先,我们来看一下这个系统是如何工作的。RAG,或者说检索增强生成,其实是个老概念,就是从文档中提取信息。 你需要一个知识库或一堆文档,然后将它们分成小块,每个小块都要计算嵌入向量。这些嵌入向量是用来找到最相关文档的数值表示,通常会存储在向量存储中,但大多数情况下你不需要向量存储。 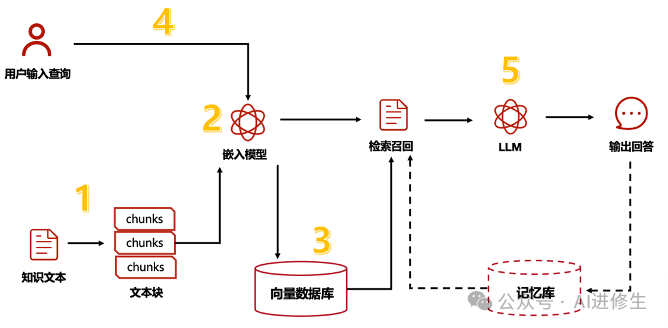
知识库创建部分完成后,当有新查询时,你需要为该查询计算嵌入,然后进行检索,找出与用户查询最接近的文档块。这些块会被附加到初始用户查询中,然后输入到LLM中生成响应。整个过程称为检索增强生成。 实现这个流程的框架有很多,最流行的是LangChain和LamaIndex,但你只需要Python、一个嵌入模型和一个LLM即可实现一个有效的RAG管道。 ingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;font-size: 16px;margin: 1.5em 8px;letter-spacing: 0.1em;color: rgb(63, 63, 63);"> 让我们把上面的步骤整理一下,系统的核心部分分为两个步骤:知识库创建和检索。 让我们把上面的步骤整理一下,系统的核心部分分为两个步骤:知识库创建和检索。
ingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;font-size: 16px;padding-left: 1em;color: rgb(63, 63, 63);" class="list-paddingleft-1">1.知识库创建: ingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;overflow-x: auto;border-radius: 8px;margin: 10px 8px;">!pipinstall-qsentence-transformers
!pipinstall-qwikipedia-api
!pipinstall-qnumpy
!pipinstall-qscipy
!pipinstall-qopenaiingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;font-weight: bold;margin: 2em 8px 0.5em;color: rgb(0, 152, 116);">第二步:加载嵌入模型ingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;font-size: 16px;margin: 1.5em 8px;letter-spacing: 0.1em;color: rgb(63, 63, 63);">我们将使用Sentence Transformer加载嵌入模型。这个模型将帮助我们将文本转换为嵌入向量。ingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;overflow-x: auto;border-radius: 8px;margin: 10px 8px;">fromsentence_transformersimportSentenceTransformer
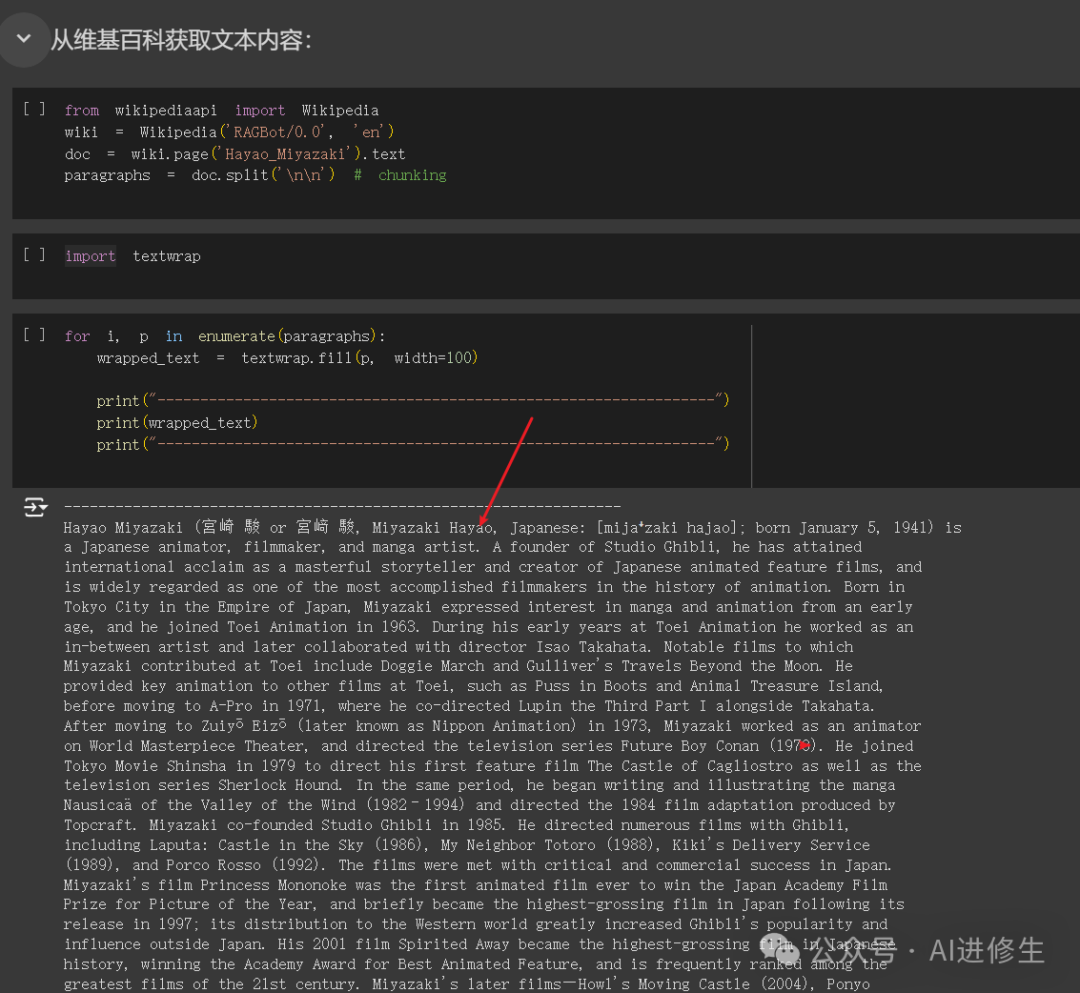
model=SentenceTransformer("Alibaba-NLP/gte-base-en-v1.5",trust_remote_code=True)ingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;font-weight: bold;margin: 2em 8px 0.5em;color: rgb(0, 152, 116);">第三步:获取维基百科内容并分块接下来,我们从维基百科获取文本内容,并将其分块。我们使用段落作为文档块。 fromwikipediaapiimportWikipedia
wiki=Wikipedia('RAGBot/0.0','en')
doc=wiki.page('Hayao_Miyazaki').text
paragraphs=doc.split('\n\n')#按段落分块
importtextwrap
fori,pinenumerate(paragraphs):
wrapped_text=textwrap.fill(p,width=100)
print("-----------------------------------------------------------------")
print(wrapped_text)
print("-----------------------------------------------------------------")
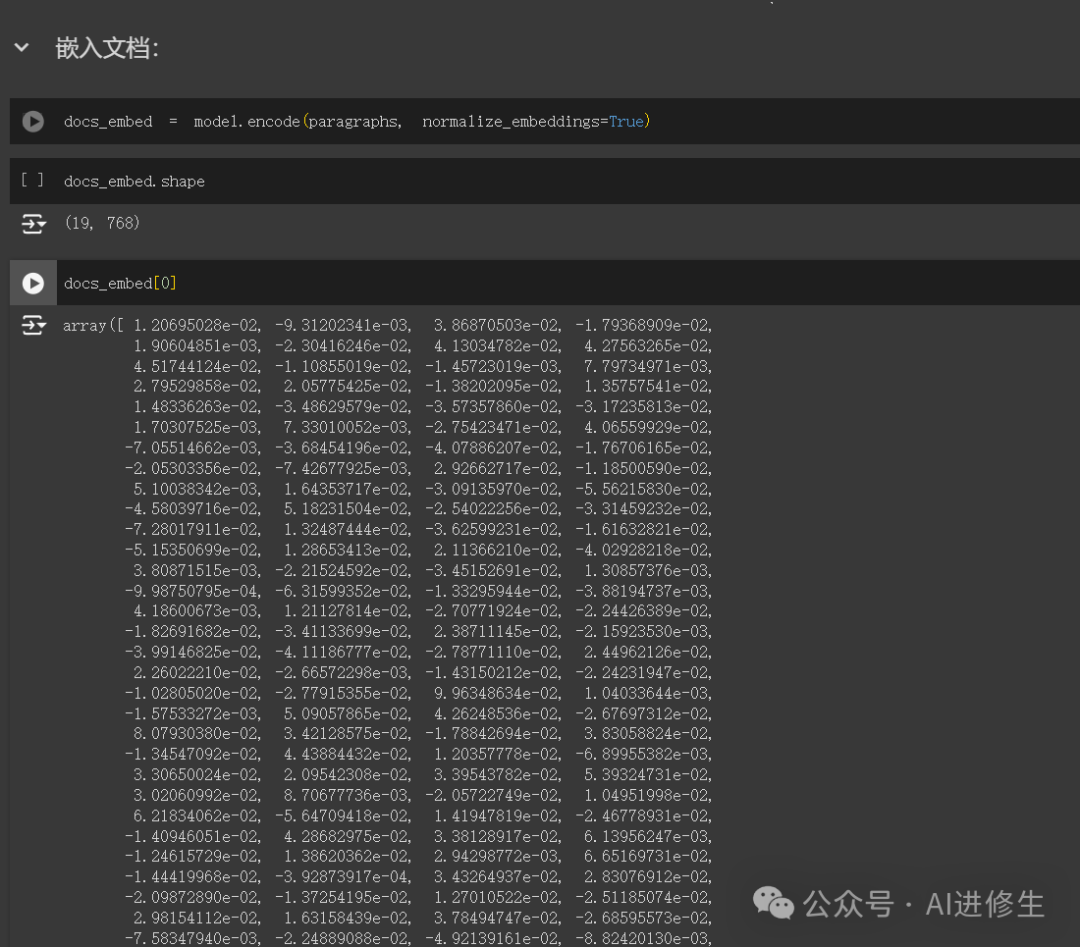
第四步:嵌入文档我们为每个文档块计算嵌入向量。 docs_embed=model.encode(paragraphs,normalize_embeddings=True)
print(docs_embed.shape)#输出嵌入向量的形状
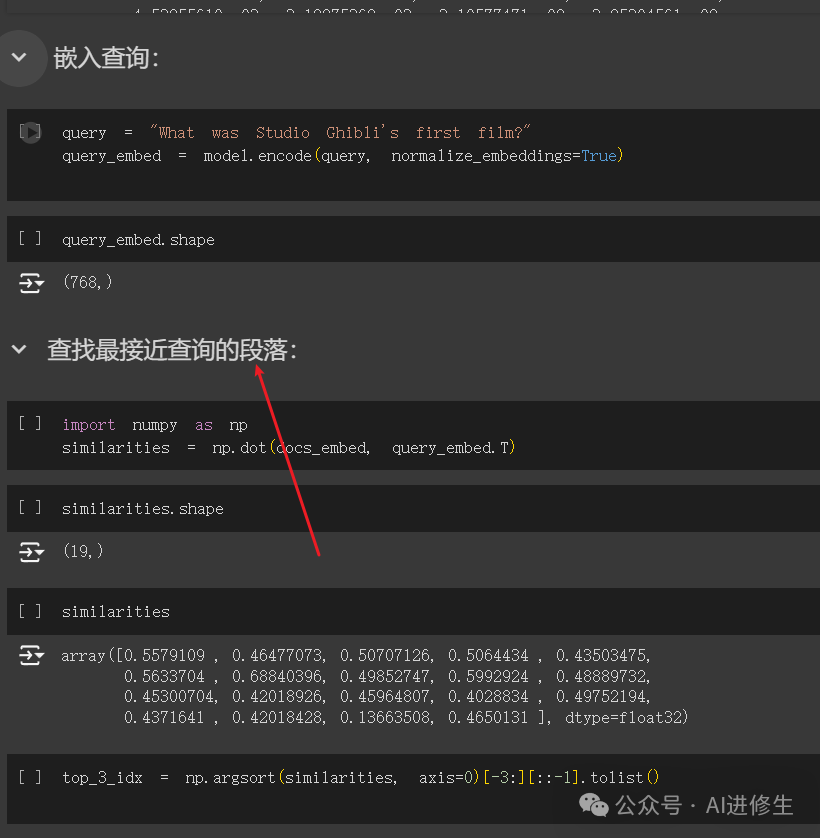
第五步:嵌入查询并检索相关文档块当用户输入查询时,我们计算查询的嵌入向量,并与文档块的嵌入向量进行比较,找出最相似的文档块。 query="WhatwasStudioGhibli'sfirstfilm?"
query_embed=model.encode(query,normalize_embeddings=True)
importnumpyasnp
similarities=np.dot(docs_embed,query_embed.T)#计算相似度(点积)
top_3_idx=np.argsort(similarities,axis=0)[-3:][::-1].tolist()#获取最相似的三个文档块索引
most_similar_documents=[paragraphs[idx]foridxintop_3_idx]
第六步:生成响应我们将最相关的文档块与用户的查询一起输入到LLM中,生成最终的响应。 CONTEXT=""
fori,pinenumerate(most_similar_documents):
wrapped_text=textwrap.fill(p,width=100)
print("-----------------------------------------------------------------")
print(wrapped_text)
print("-----------------------------------------------------------------")
CONTEXT+=wrapped_text+"\n\n"
prompt=f"""
UsethefollowingCONTEXTtoanswertheQUESTIONattheend.
Ifyoudon'tknowtheanswer,justsaythatyoudon'tknow,don'ttrytomakeupananswer.
CONTEXT:{CONTEXT}
QUESTION:{query}
"""
importopenai
client=openai.OpenAI(api_key="YOUR_API_KEY")
response=client.ChatCompletion.create(
model="gpt-4",
messages=[
{"role":"user","content":prompt},
]
)
print(response.choices[0].message.content)
通过以上步骤,你可以用纯Python实现一个简单的RAG系统。这不仅有助于理解RAG的工作原理,还能帮助你在不依赖框架的情况下构建定制的检索增强生成系统。 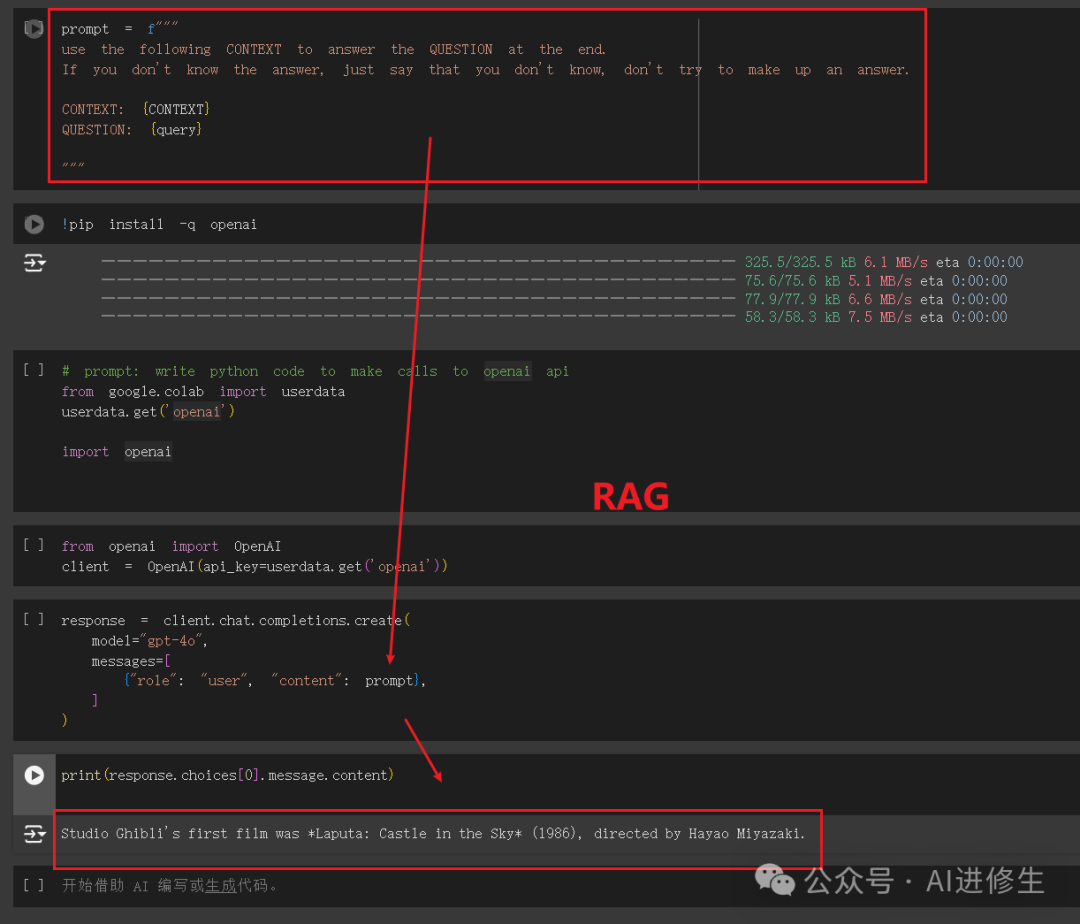
以上所有过程及中间结果: 向上滑动 / 双击放大 现在,由于需要大量的辅助代码,这超过了10行代码,但是基本的Rack流水线可以用近10行代码实现。
|











 实现步骤ingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;font-weight: bold;margin: 2em 8px 0.5em;color: rgb(0, 152, 116);">第一步:安装必要的库ingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;font-size: 16px;margin: 1.5em 8px;letter-spacing: 0.1em;color: rgb(63, 63, 63);">我们需要安装一些Python库来实现这个过程。可以使用以下命令在Google Colab中安装这些库:
实现步骤ingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;font-weight: bold;margin: 2em 8px 0.5em;color: rgb(0, 152, 116);">第一步:安装必要的库ingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;font-size: 16px;margin: 1.5em 8px;letter-spacing: 0.1em;color: rgb(63, 63, 63);">我们需要安装一些Python库来实现这个过程。可以使用以下命令在Google Colab中安装这些库: