|
我们都知道,大模型的训练需要大量的训练数据。而合成数据 - synthetic data作为真实数据的补充,已经成为训练数据中的重要组成部分(甚至未来合成数据的占比可能会达到~99%)。 今天看到腾讯AI实验室的一篇paper,为创造合成数据提供了新的思路: Scaling Synthetic Data Creation with 1,000,000,000 Personas 下载地址https://arxiv.org/pdf/2401.02524 
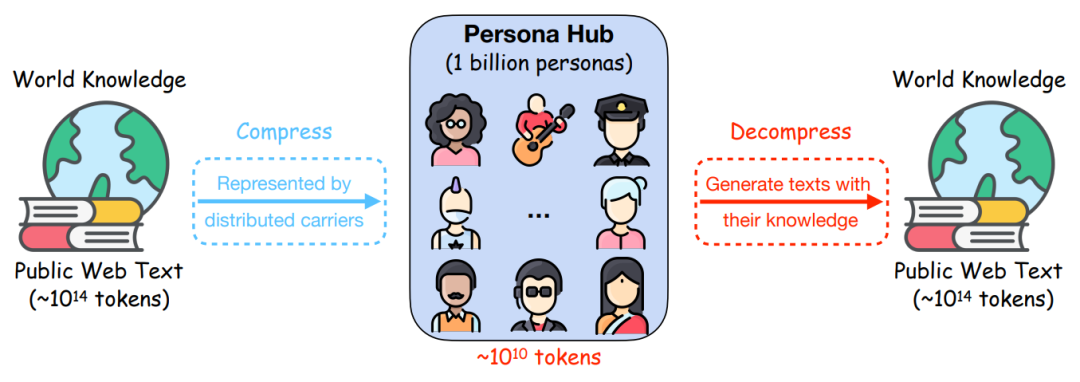
顾名思义,作者通过十亿个Persona人物角色(约占世界人口13%)来为合成数据scale up:we introduce Persona Hub – a collection
of 1 billion diverse personas automatically curated from web data。 通过这个Persona Hub,组建了一个由形形色色的不同角色组成的世界,这些人物角色作为世界知识的载体,可以大规模地生成各种场景下的合成数据。
合成数据的背景 合成数据对于训练和优化 LLMs 至关重要,现在人们会通过prompt来让LLM产出合成数据。但现有方法在批量生成多样化、高质量的数据方面存在局限。 为此,文章作者提出了基于人物角色Persona的方法,构建了10亿个Persona,创建了Persona Hub,即角色仓库,里面包含“搬家公司司机”、“科学研究员”、“音乐家”等多样化角色。这样一来,不同Persona利用LLM中的多种视角来创建丰富的合成数据。 
Persona Hub 的创新与构建 Persona Hub 是一个包含十亿个虚拟人物角色的集合,这些人物角色拥有不同的性格、背景和经历。构建 Persona Hub 的两种主要方法为: - 文本到角色Text-to-Persona。实施步骤:1)从网络数据中选取各种类型的文本,如新闻文章、学术论文、博客帖子等。2)人物特征推断:使用LLM分析文本,根据文本的主题、用词、结构等信息,推断出可能与文本相关联的人物角色。3)Persona描述生成:基于推断出的人物特征,生成详细的Persona描述。这可能包括角色的职业、兴趣、价值观、生活方式等。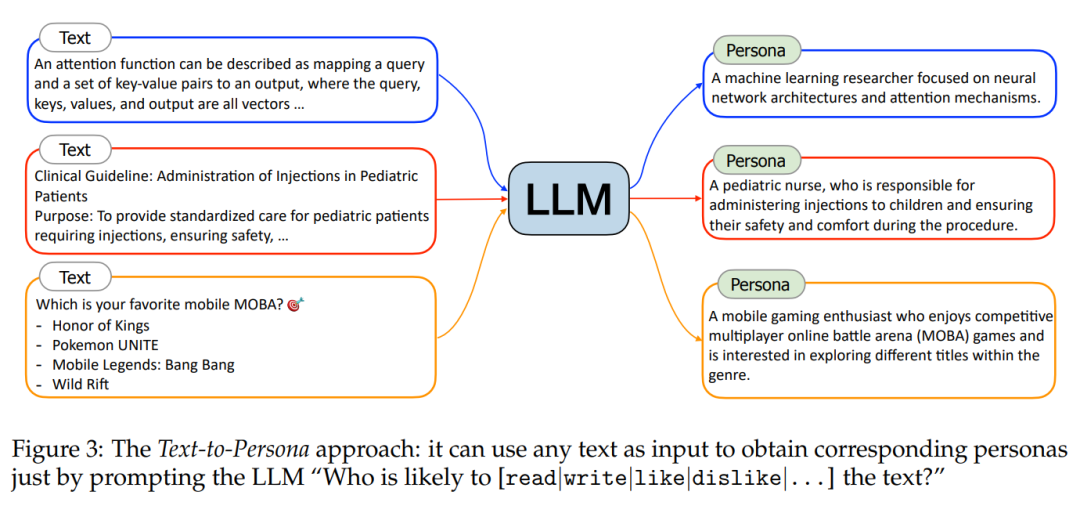
- 角色到角色Persona-to-Persona。通过现有人物角色间的社交关系,衍生出新的角色。Persona-to-Persona" 是一种用于丰富 Persona Hub 人物角色集合的方法。它通过已存在的人物角色(通过 Text-to-Persona 方法获得)来衍生出具有人际关系的新人物角色。这种方法的目的是补充那些在网络文本中不太可见或难以通过文本分析直接获得的人物角色,例如儿童、乞丐或电影的幕后工作人员。实施步骤:1)确定源人物角色:选择已通过 Text-to-Persona 方法创建的人物角色作为出发点。2)识别人际关系:确定源人物角色可能的人际关系,如家庭成员、朋友、同事或专业联系。3)衍生新人物角色:基于这些关系,创建与之相关联的新人物角色。
Persona Hub 创建合成数据 Persona Hub构建完毕,作者将Persona融入到不同的数据合成的prompt的适当位置,就可以批量生成多样化的合成数据。 作者展示了其在多个场景下创造合成数据的能力: - 数学和逻辑推理问题:生成具有挑战性的数学问题和逻辑推理题目。- 用户指令:模拟用户可能对 LLMs 提出的各种指令。- 知识型文本:创造富含知识的文本内容,适用于教育和信息传播。- 游戏 NPC:为游戏设计提供多样化的非玩家角色。- 工具和功能开发:预制工具和功能,以满足特定人物角色的需求。
一个生成数学题目的Demo 作者展示了如何使用一个Persona来引导LLM创建与该Persona相关的数学问题。例如,当给定一个对计算语言学感兴趣的语言学家人物角色时,LLM会创建一个与计算语言学相关的数学问题。此外,演示还强调了即使在提示中添加了Persona,仍然可以轻松指定所需数学问题的重点(例如,几何问题)或难度(例如,奥林匹克级别的问题)。 
Persona Hub 的潜在影响与未来展望 Persona Hub 的出现预示着合成数据领域的一次范式转变。它不仅能提升 LLMs 的训练效果,还能在聊天机器人、虚拟助手、模拟现实世界个体等多个领域发挥作用。此外,Persona Hub 还可为 LLMs 提供全面的记忆访问,使对话更加连贯和合理。 | 









