|
AI Agent(智能体)作为大模型的重要应用模式,能够通过使用外部工具来执行复杂任务,完成多步骤的工作流程。为了能全面评估模型的工具使用能力,司南及合作伙伴团队推出了 T-Eval 评测基准,相关成果论文已被ACL 2024主会录用。
查看原文:https://arxiv.org/abs/2312.14033使用了工具的大语言模型有着惊艳的问题解决能力,但是如何评估模型的工具使用能力还有很大的探索空间。现有评估方法通常只关注模型处理单步骤任务时的工具调用表现,缺少在多步骤复杂任务场景下模型使用工具能力的评估。因此,为了更全面地评估大语言模型的工具使用能力,司南及合作伙伴团队推出了 T-Eval (a step-by-step Tool Evaluation benchmark for LLMs) 评测基准,相较于之前整体评估模型的方式,论文中将大模型的工具使用分解为多个子过程,包括:规划、推理、检索、理解、指令跟随和审查。
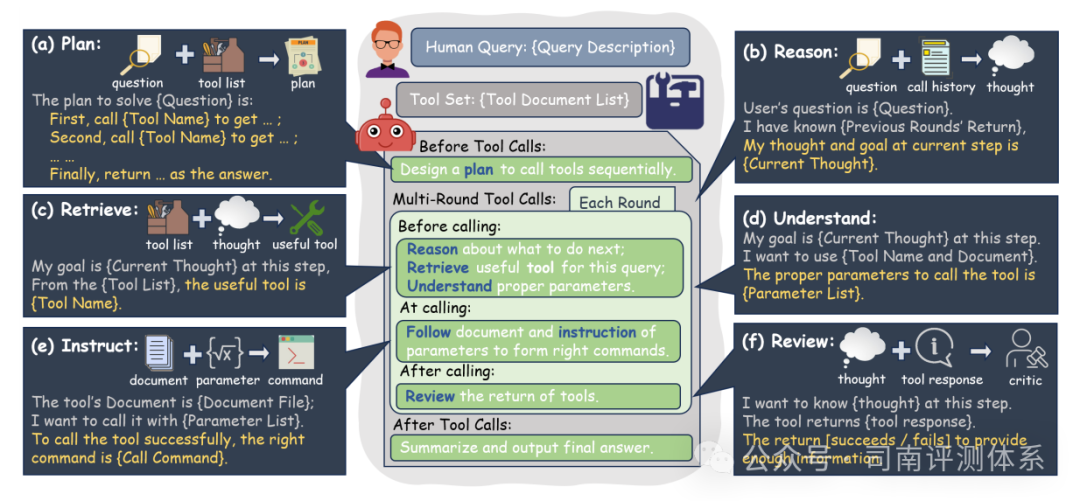
- 规划(PLAN):将用户问题分解为多个子问题,制定行动计划。
- 推理(REASON):对上个状态的完成情况的判断,下一步行动的思考。
- 检索(RETRIEVE):从给定的工具列表中选择合适的工具。
- 理解(UNDERSTAND):正确理解工具使用的参考文档和所需参数。
- 指令跟随(INSTRUCT):生成指定格式的工具调用请求。
- 审查(REVIEW):评估每个工具调用执行的结果,确保回答满足预期目标。
T-Eval 的构建主要包括 3 个阶段:工具收集、指令生成和参考答案标注。首先,我们根据可用性和使用率,挑选了15种基本工具,涵盖了研究、旅行、娱乐、网络、生活和金融等多个领域。此外,还为每个工具生成了详细的API文档,以减少因工具描述不充分而导致的工具调用失败案例。然后,我们利用 GPT-3.5 生成了初始问题,并通过 GPT-4 进一步完善问题。之后,我们开发了一个多智能体框架,利用所提供的工具解决问题,同时收集解决方案路径和工具响应。最后,我们使用人类专家来挑选高质量样本。

 细粒度评测:T-Eval将评测过程分解为多个子任务,分别评估模型在工具使用上的细粒度能力。 细粒度评测:T-Eval将评测过程分解为多个子任务,分别评估模型在工具使用上的细粒度能力。
多智能体数据生成:使用了由人类专家验证的多智能体数据生成流程,显著减少了外部因素的影响,使评测结果更加稳定、公平。广泛实验:通过在各种大模型上的广泛实验,验证了T-Eval的有效性和普适性,为当前大语言模型的工具使用能力瓶颈提供了宝贵的见解,并为改进工具使用能力提供了新的视角。我们在 T-Eval 上对 20 种大语言模型进行了评测,包括基于 API 的商业模型和开源模型。结果显示,GPT-4 在整体评分上取得了最高分,显示出其卓越的工具使用能力。对于开源模型,我们对三种不同规模的模型进行了实验,它们的尺寸大约是7B、13B和70B,可以发现,随着模型参数的增加,其表现也更加优秀。特别是 Qwen-72B 模型,其总得分已接近 API 模型水平。
T-Eval 现已加入 OpenCompass 评测平台,更多详细内容可参考以下链接!
GitHub:
https://github.com/open-compass/T-Eval
OpenCompass官网:
https://hub.opencompass.org.cn/dataset-detail/T-Eval
联系我们:
opencompass@pjlab.org.cn
| 









