|
本文分析和总结Llama模型中的核心技术点,了解当前大语言模型的一般趋势和做法。 模型家族(不同Size模型,预训练和指令微调版本)
预训练提供70B和8B量级模型,8B更适合资源有限场景部署,但是质量弱于80B模型。 除了基本预训练模型提供给用户,也提供指令微调版本,用于对话,代码生产等场景直接用。
Meta Llama 3,可供广泛使用。此版本具有预训练和指令微调的语言模型,具有 8B 和 70B 参数,可支持广泛的用例。
使用预训练版本8B:
torchrun--nproc_per_node1example_text_completion.py\--ckpt_dirMeta-Llama-3-8B/\--tokenizer_pathMeta-Llama-3-8B/tokenizer.model\--max_seq_len128--max_batch_size4br 使用指令微调版本8B:
torchrun--nproc_per_node1example_chat_completion.py\--ckpt_dirMeta-Llama-3-8B-Instruct/\--tokenizer_pathMeta-Llama-3-8B-Instruct/tokenizer.model\--max_seq_len512--max_batch_size6br 其提供针对代码微调和负责任的AI微调的版本: 
2.开源与闭源 Llama3是开源,但是注意License,目前Hugging Face上的模型有不同License,有的是到一定规模商用需要付费。 https://llama.meta.com/llama3/license/ 3. 不同B的模型是独立训练还是量化得出的? 独立训练 4. 评测性能 指令微调版本模型:  目前评测角度及benchmark展示的为: 目前评测角度及benchmark展示的为:
该评估集包含 1,800 个提示,涵盖 12 个关键用例:寻求建议、头脑风暴、分类、封闭式问答、编码、创意写作、提取、栖息角色/角色、开放式问答、推理、重写和总结。(asking for advice, brainstorming, classification, closed question answering, coding, creative writing, extraction, inhabiting a character/persona, open question answering, reasoning, rewriting, and summarization. )
总结起来是目前是纯语言模型,做文本输出,代码输出等场景。
为了防止过拟合数据,以及针对真实场景评测,同时做了人工评测。对比的是当前的主流开源模型或闭源模型。目前得胜率超过其他几个代表性模型。评测任务为:This evaluation set contains 1,800 prompts that cover 12 key use cases: asking for advice, brainstorming, classification, closed question answering, coding, creative writing, extraction, inhabiting a character/persona, open question answering, reasoning, rewriting, and summarization.

5. 模型卡片: 输入模型仅输入文本。 输出模型仅生成文本和代码。 自回归模型
纯解码器架构:根据Scaling Law,模型超参数和结构影响较小,遵从当前主流架构。 128K 标记词汇表的分词器,可以更有效地编码语言,从而大大提高模型性能。应对未来问题就是如果是国内的很多新网络用语,新的标记不一定能识别。所以新词发现本身和分词器相关,分词器和模型强绑定。分词器越大 所有模型都使用分组查询注意力 (GQA) 来提高训练和推理效率。 8,192 个令牌的序列上进行了训练。也就是训练数据是8192个长度的上下文数据。所以也决定了上下文长度是8K。 训练数据量15T+的标记数量。
调整后的版本使用监督微调 (SFT) 和带有人类反馈的强化学习 (RLHF),以符合人类对有用性和安全性的偏好。

6. 输入输出安全性评测与保障 对Llama Guard模型为例: 它充当 LLM:它在其输出中生成文本,指示 给定的提示或响应是安全的/不安全的,如果基于策略不安全,则 还列出了违规的子类别。下面是一个示例: 
7. SFT和RLHF作用 具体领域任务微调+遵从预定义指令及格式:调整后的版本使用监督微调 (SFT) 针对下游任务,例如code版本写代码。
安全对齐+已有的采样答案选择:带有人类反馈的强化学习 (RLHF),以符合人类对有用性和安全性的偏好。 为了在聊天用例中充分释放预训练模型的潜力,还对指令调整方法进行了创新。 后培训方法是监督微调 (SFT)、拒绝抽样、近端策略优化 (PPO) 和直接偏好优化 (DPO) 的组合。 SFT 中使用的提示的质量以及 PPO 和 DPO 中使用的偏好排名对对齐模型的性能有很大影响。 在模型质量方面的一些最大改进来自于仔细管理这些数据,并对人工注释者提供的注释执行多轮质量保证。 通过 PPO 和 DPO 从偏好排名中学习也大大提高了 Llama 3 在推理和编码任务上的表现。 为什么做RLHF:其发现,如果你问一个模型一个它难以回答的推理问题,模型有时会产生正确的推理痕迹:模型知道如何产生正确的答案,但它不知道如何选择它。对偏好排名的训练使模型能够学习如何选择它。 8. 15Ttoken和128K标记的分词器 因为文本中有大量冗余标记组合成文本,所以分词器代表去冗余后的唯一标记数量。 9. 训练数据 目前代价较高的是还需要引入人工标注数据。目前开源模型一般不用公司生产闭源数据,都是用的公开数据+人工新标注的数据。以防止数据泄露。一般根据发布时间为2024.4月推断,有1年的时间滞后性。
概述Llama 3 在来自公开来源的超过 15 万亿个数据代币上进行了预训练。微调数据包括公开可用的指令数据集,以及超过1000万个人工注释的示例。预训练和微调数据集均不包含元用户数据。 数据新鲜度8B 的预训练数据截止时间分别为 2023 年 3 月和 2023 年 12 月(70B 模型)。 10. 需要构建内部评测库 虽然很多是公开数据集但是需要内部评测库自动化评测。
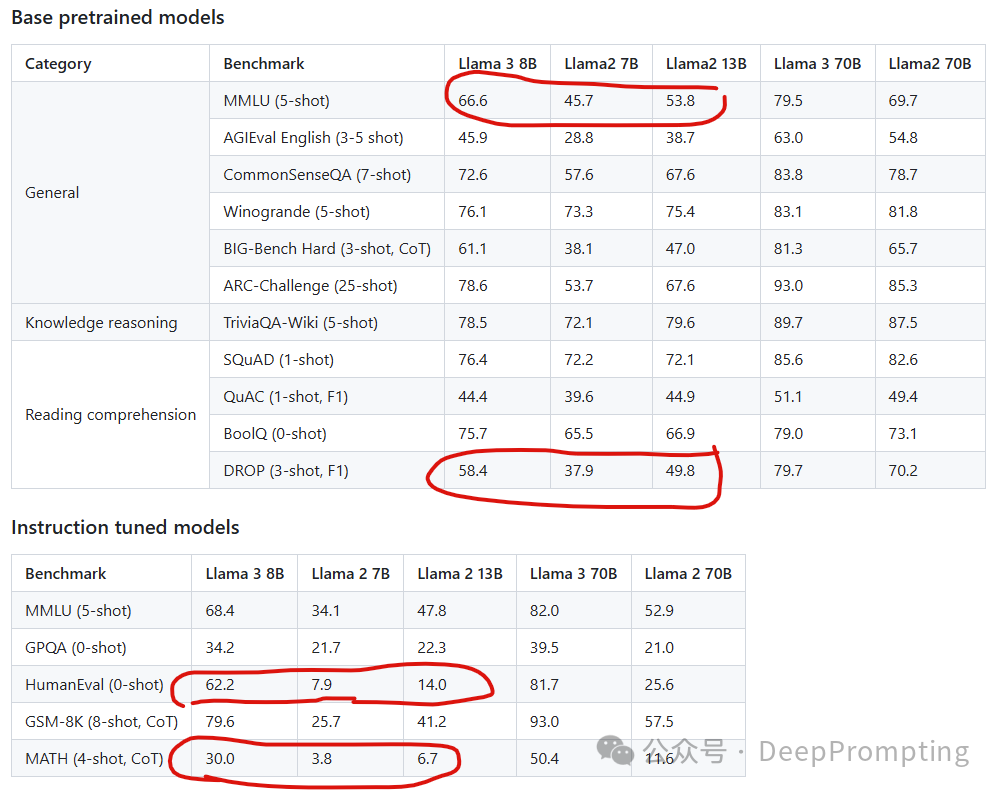
In this section, we report the results for Llama 3 models on standard automatic benchmarks. For all the evaluations, we use our internal evaluations library. For details on the methodology seehere. 11. 为什么需要微调版本 普通版本基本做文本类的任务,微调版本可以做代码生成,Math数学等更复杂的合成与推理任务。同时高B模型效果更好,新一代模型效果更好。 
为了在聊天用例中充分释放预训练模型的潜力,我们还对指令调整方法进行了创新。 我们的后培训方法是监督微调 (SFT)、拒绝抽样、近端策略优化 (PPO) 和直接偏好优化 (DPO) 的组合。 SFT 中使用的提示的质量以及 PPO 和 DPO 中使用的偏好排名对对齐模型的性能有很大影响。 我们在模型质量方面的一些最大改进来自于仔细管理这些数据,并对人工注释者提供的注释执行多轮质量保证。 通过 PPO 和 DPO 从偏好排名中学习也大大提高了 Llama 3 在推理和编码任务上的表现。 我们发现,如果你问一个模型一个它难以回答的推理问题,模型有时会产生正确的推理痕迹:模型知道如何产生正确的答案,但它不知道如何选择它。对偏好排名的训练使模型能够学习如何选择它。 12 Scaling Law的应用 应用场景为了预估已知模型尺寸下,用多少数据,或多少计算量(训练时间)能达到预期准确度,进而进行预算的预估。
为了在 Llama 3 模型中有效地利用我们的预训练数据,我们投入了大量精力来扩大预训练。具体而言,我们为下游基准评估制定了一系列详细的扩展法则。
这些缩放定律使我们能够选择最佳的数据组合,并就如何最好地使用我们的训练计算做出明智的决策。重要的是,缩放定律允许我们在实际训练模型之前预测最大模型在关键任务上的性能(例如,在 HumanEval 基准测试中评估的代码生成——见上文)。这有助于我们确保最终模型在各种用例和功能中具有强大的性能。
我们在 Llama 3 的开发过程中对缩放行为进行了一些新的观察。例如,虽然 8B 参数模型的 Chinchilla 最优训练计算量对应于 ~200B 标记,但我们发现,即使在模型使用两个数量级的数据进行训练后,模型性能仍在继续提高。我们的 8B 和 70B 参数模型在我们对高达 15T 的代币进行训练后,继续对数线性改进。较大的模型可以与这些较小模型的性能相匹配,但训练计算较少,但通常首选较小的模型,因为它们在推理过程中效率更高。
13 并行化策略 评测指标:计算利用率 compute utilization。

本质是针对张量不同维度进行切分。 数据并行:输入数据的批尺寸维度 模型并行:权重张量的行和列维度 流水并行:工作流流水线切分 序列并行:输入数据的序列长度维度(标记维度)
为了训练我们最大的 Llama 3 模型,我们结合了三种类型的并行化:数据并行化、模型并行化和管道并行化。我们最高效的实现是在 16K GPU 上同时训练时,每个 GPU 的计算利用率超过 400 TFLOPS。我们在两个定制的24K GPU 集群上执行了训练运行。为了最大限度地延长 GPU 正常运行时间,我们开发了一种先进的新训练堆栈,可自动执行错误检测、处理和维护。 其是混合精度训练,其达到了接近40%的计算利用率。 

14 系统稳定性保障 评测指标:有效训练时间。总时间减去down机和hang时间,除以总时间的比例。 总之,这些改进将 Llama 3 的训练效率提高了 ~3 倍,比 Llama 2 提高了 ~3 倍。 15 数据预处理技巧 完成特定任务一定经过这类数据训练(例如多语言,但是语料数量和质量不同,英语已知是效果最好和语料数据十分相关),开源模型一般采用公开数据,数据会投入大量资金。数据质量一般通过过滤保留高质量数据,过滤方法是基于规则,字典和基于模型,围绕安全和质量。数据混合方法通过类似自动化机器学习做实验方式尝试出来。 为了训练最佳语言模型,管理大型、高质量的训练数据集至关重要。根据我们的设计原则,我们在预训练数据方面投入了大量资金。 Llama 3 在超过 15T 的代币上进行了预训练,这些代币都是从公开来源收集的。 我们的训练数据集比 Llama 2 使用的数据集大 7 倍,包含的代码是 Llama 2 的 4 倍。结合评测,看到效果有实质性大幅提升。
为了应对即将到来的多语言用例,Llama 3 预训练数据集的 5% 以上由涵盖 30 多种语言的高质量非英语数据组成。但是,其预计这些语言的性能水平与英语不同。 为了确保 Llama 3 接受最高质量的数据训练,我们开发了一系列数据过滤管道。这些管道包括使用启发式筛选器、NSFW 筛选器、语义重复数据删除方法和文本分类器来预测数据质量。我们发现前几代 Llama 在识别高质量数据方面出奇地好,因此我们使用 Llama 2 为 Llama 3 提供支持的文本质量分类器生成训练数据。【模型评判数据或合成数据以促进新模型训练】 我们还进行了广泛的实验,以评估在最终的预训练数据集中混合来自不同来源的数据的最佳方法。这些实验使我们能够选择一种数据组合,确保 Llama 3 在包括琐事问题、STEM、编码、历史知识等在内的用例中表现良好。【特征工程,自动化机器学习再次】
16 下一步工作
| 









