【导读】:本文是ingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;font-size: 12px;letter-spacing: 0.544px;text-wrap: wrap;background-color: rgb(255, 255, 255);outline: 0px;visibility: visible;">LLM知识点ingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;font-size: 12px;letter-spacing: 0.544px;text-wrap: wrap;background-color: rgb(255, 255, 255);outline: 0px;visibility: visible;">第一篇,整理了10个Transformer面试ingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;font-size: 12px;letter-spacing: 0.544px;text-wrap: wrap;background-color: rgb(255, 255, 255);outline: 0px;visibility: visible;">相关知识!
ingFang SC", Cambria, Cochin, Georgia, Times, "Times New Roman", serif;letter-spacing: normal;text-align: left;background-color: rgb(255, 255, 255);border-bottom: 2px solid rgb(239, 112, 96);visibility: visible;">【1】为何现在的主流的LLM模型大部分是Decoder only结构?【1】为何现在的主流的LLM模型大部分是Decoder only结构?引用知乎Sam多吃香菜的回答:
1.用过去研究的经验说话,decoder-only的泛化性能更好,在最大5B参数量、170Btoken数据量的规模下做了一系列实验,发现用next token prediction预训练的decoder-only模型在各种下游任务上zero-shot泛化性能最好;另外,许多工作表明decoder-only模型的few-shot(即上下文学习,in-contextlearning)泛化能力更强,参见论文[2]和@Minimum大佬回答的第3点。zero-shot的表现:decoder-only结构模型在没有任何微调数据的情况下,zero-shot的表现能力最好。而encoder-decoder则需要在一定量的标注数据上做multitask-finetuning才能够激发最佳性能。2.效率问题,decoder-only支持一直复用KV-Cache,对多轮对话更友好,因为每个token的表示只和它之前的输入有关,而encoder-decoder和PrefixLM就难以做到;3.谈谈轨迹依赖的问题:OpenAI作为开拓者勇于挖坑踩坑,以decoder-only架构为基础摸索出了一套行之有效的训练方法和Scaling Law,后来者继续沿用decoder-only架构。在工程生态上,decoder-only架构也形成了先发优势,Megatron和flash attention等重要工具对causal attention的支持更好。4.LLM之所以主要都用Decoder-only架构,除了训练效率和工程实现上的优势外,在理论上是因为Encoder的双向注意力会存在低秩问题,这可能会削弱模型表达能力,就生成任务而言,引入双向注意力并无实质好处。而Encoder-Decoder架构之所以能够在某些场景下表现更好,大概只是因为它多了一倍参数。所以,在同等参数量、同等推理成本下,Decoder-only架构就是最优选择了。【苏神】
5.博采众家之言,分析科学问题,阐述decoder-only泛化性能更好的潜在原因:
【★】为什么现在的LLM都是Decoder only的架构?-sam多吃香菜的回答【202401】:https://www.zhihu.com/question/588325646/answer/3357252612 ingFang SC", Cambria, Cochin, Georgia, Times, "Times New Roman", serif;letter-spacing: normal;text-align: left;background-color: rgb(255, 255, 255);border-bottom: 2px solid rgb(239, 112, 96);visibility: visible;">【2】简述Transformer内部结构和其内部细节?【2】简述Transformer内部结构和其内部细节。Transformer 整体结构: 
基于Transformer结构的编码器和解码器结构如图所示,左侧和右侧分别对应着编码器(Encoder)和解码器(Decoder)结构。它们均由若干个基本的 Transformer 块(Block)组成(对应着图中的灰色框)。这里 N×表示进行了 N 次堆叠。每个 Transformer 块都接收一个向量序列{xi }作为输入,并输出一个等长的向量序列作为输出{yi }。 这里的 xi和 yi 分别对应着文本序列中的一个单词的表示。而 yi 是当前 Transformer 块对输入 xi 进一步整合其上下文语义后对应的输出。 在从输入{xi }到输出{yi }的语义抽象过程中,主要涉及到如下几个模块: 1.注意力层:使用多头注意力(Multi-Head Attention)机制整合上下文语义,它使得序列中任意两个单词之间的依赖关系可以直接被建模而不基于传统的循环结构,从而更好地解决文本的长程依赖。2.位置感知前馈层(Position-wise FFN):通过全连接层对输入文本序列中的每个单词表示进行更复杂的变换。3.残差连接:对应图中的 Add 部分。它是一条分别作用在上述两个子层当中的直连通路,被用于连接它们的输入与输出。从而使得信息流动更加高效,有利于模型的优化。4.层归一化:对应图中的 Norm 部分。作用于上述两个子层的输出表示序列中,对表示序列进行层归一化操作,同样起到稳定优化的作用。
ingFang SC", Cambria, Cochin, Georgia, Times, "Times New Roman", serif;letter-spacing: normal;text-align: left;background-color: rgb(255, 255, 255);border-bottom: 2px solid rgb(239, 112, 96);visibility: visible;">【3】简介Encoder结构计算流程+Decoder结构计算流程【3】简介Encoder结构计算流程+Decoder结构计算流程
Transformer的Encoderblock结构,可以看到是由MultiHeadAttention,Add&Normalize,Feed Forward, Add &Normalize组成的。1.Add& Norm 层由 Add 和 Normmalize 两部分组成,其计算公式如下: 
其中: X表示Multi-HeadAttention或者FeedForward的输入,MultiHeadAttention(X)和FeedForward(X)表示输出(输出与输入X维度是一样的,所以可以相加)。 Add指X+MultiHeadAttention(X)残差连接,通常用于解决多层网络训练的问题,可以让网络只关注当前差异的部分。 Norm指Layer Normalization,LN会将每一层神经元的输入都转成均值方差都一样的,这样可以加快收敛。
2.Feed Forward层是两层的全连接层,第一层的激活函数为 Relu,第二层不使用激活函数,对应的公式如下: 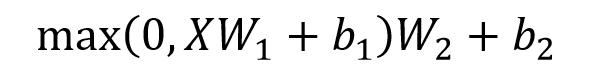
X是输入,FeedForward最终得到的输出矩阵的维度与X一致。
3.组成Encoder:Encoder block接收输入矩阵?(?×?)并输出一个矩阵?(?×?)。通过多个 Encoder block 叠加就可以组成 Encoder。第一个Encoderblock的输入为句子单词的表示向量矩阵,后续Encoderblock的输入是前一个Encoderblock的输出,最后一个Encoderblock输出的矩阵就是编码信息矩阵C,这一矩阵后续会用到 Decoder 中。
Transformer 的 Decoder block 结构,与 Encoder block 相似,但是存在一些区别:包含两个 Multi-Head Attention 层。第一个 Multi-Head Attention 层采用了 Masked 操作。第二个Multi-HeadAttention层的K,V矩阵使用Encoder的编码信息矩阵C进行计算,而Q使用上一个 Decoder block 的输出计算。最后有一个 Softmax 层计算下一个翻译单词的概率。
1.第一个Multi-HeadAttention+Masked
Decoder block 的第一个 Multi-Head Attention 采用了 Masked 操作,因为在翻译的过程中是顺序翻译的,即翻译完第 i 个单词,才可以翻译第 i+1 个单词。通过 Masked 操作可以防止第 i 个单词知道 i+1 个单词之后的信息。
下面以"我有一只猫"翻译成"I have a cat"为例,了解一下 Masked 操作。在 Decoder 的时候,是需要根据之前的翻译,求解当前最有可能的翻译,如下图所示。首先根据输入"<Begin>"预测出第一个单词为"I",然后根据输入"<Begin> I"预测下一个单词"have"。

Decoder 可以在训练的过程中使用 Teacher Forcing 并且并行化训练,即将正确的单词列(<Begin> I have a cat)和对应输出(I have a cat <end>)传递到 Decoder。那么在预测第 i 个输出时,就要将第 i+1 之后的单词掩盖住,注意 Mask 操作是在 Self-Attention 的 Softmax 之前使用的,下面用0 1 2 3 4 5 分别表示"<Begin> I have a cat <end>"。
第一步:是Decoder的输入矩阵和Mask矩阵,输入矩阵包含<Begin>Ihaveacat"(0,1,2,3,4) 五个单词的表示向量,Mask是一个 5×5 的矩阵。在Mask可以发现单词0只能使用单词0的信息,而单词 1 可以使用单词0, 1 的信息,即只能使用之前的信息。

第二步:接下来的操作和之前的Self-Attention一样,通过输入矩阵X计算得到Q,K,V矩阵。然后计算Q和 Kᐪ的乘积 QKᐪ。
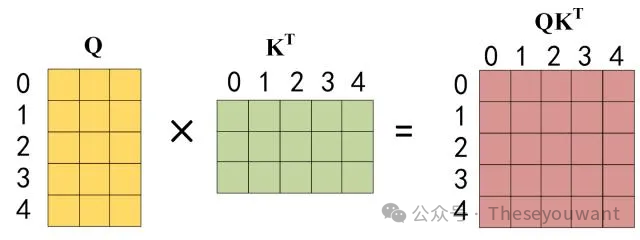
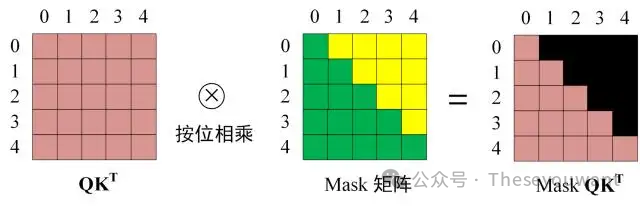
第三步:在得到QKᐪ之后需要进行Softmax,计算attentionscore,在Softmax之前需要使用Mask矩阵遮挡住每一个单词之后的信息,遮挡操作如下:--,得到MaskQKᐪ之后在MaskQKᐪ上进行 Softmax,每一行的和都为 1。但是单词0在单词 1, 2, 3, 4 上的 attention score 都为0。
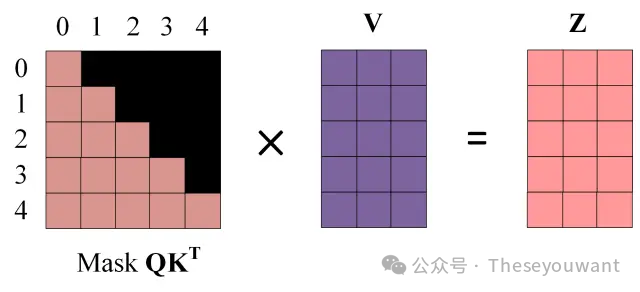
第四步:使用MaskQKᐪ与矩阵V相乘,得到输出Z,则单词 1 的输出向量?1 是只包含单词 1 信息的。
第五步:通过上述步骤就可以得到一个MaskSelf-Attention的输出矩阵??,然后和Encoder类似,通过Multi-HeadAttention拼接多个输出 ?? 然后计算得到第一个Multi-HeadAttention的输出Z,Z与输入X维度一样。
2.第二个Multi-HeadAttention Decoderblock第二个Multi-HeadAttention变化不大,主要的区别在于其中Self-Attention的K, V矩阵不是使用上一个 Decoder block 的输出计算的,而是使用 Encoder 的编码信息矩阵 C 计算的。
根据Encoder的输出C计算得到K,V,根据上一个Decoderblock的输出Z计算Q(如果是第一个 Decoderblock则使用输入矩阵X进行计算),后续的计算方法与之前描述的一致。这样做的好处是在 Decoder的时候,每一位单词都可以利用到Encoder所有单词的信息(这些信息无需Mask)。
3.Softmax预测输出单词 Decoder block 最后的部分是利用 Softmax 预测下一个单词,在之前的网络层可以得到一个最终的输出 Z,因为 Mask 的存在,使得单词0的输出 Z0只包含单词0的信息,如下: 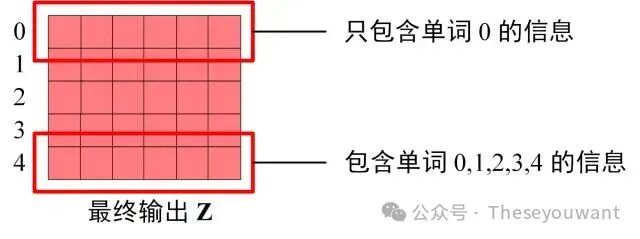
Softmax 根据输出矩阵的每一行预测下一个单词:
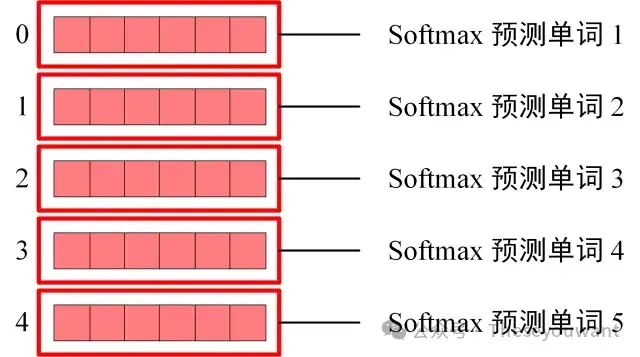
这就是 Decoder block 的定义,与 Encoder 一样,Decoder 是由多个 Decoder block 组合而成。 ingFang SC", "Microsoft YaHei", "Source Han Sans SC", "Noto Sans CJK SC", "WenQuanYi Micro Hei", sans-serif;font-optical-sizing: inherit;font-kerning: inherit;font-feature-settings: inherit;font-variation-settings: inherit;margin-top: 24px;margin-bottom: 24px;color: rgb(25, 27, 31);letter-spacing: normal;text-align: start;text-wrap: wrap;background-color: rgb(255, 255, 255);">【★】Transformer模型详解(图解最完整版)-初识CV# 2.Transformer 的输入+4.Encoder 结构+5.Decoder结构【202012】:https://zhuanlan.zhihu.com/p/338817680 ingFang SC", "Microsoft YaHei", "Source Han Sans SC", "Noto Sans CJK SC", "WenQuanYi Micro Hei", sans-serif;font-optical-sizing: inherit;font-kerning: inherit;font-feature-settings: inherit;font-variation-settings: inherit;margin-top: 24px;color: rgb(25, 27, 31);letter-spacing: normal;text-align: start;text-wrap: wrap;background-color: rgb(255, 255, 255);margin-bottom: 0px;">ingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;font-size: var(--articleFontsize);letter-spacing: 0.034em;">补充:训练时:第i个decoder的输入= encoder输出+ ground truth embedding。预测时:第i个decoder的输入= encoder输出+第(i-1)个decoder输出。训练时因为知道ground truth embedding,相当于知道正确答案,网络可以一次训练完成。
预测时,首先输入start,输出预测的第一个单词然后start和新单词组成新的query,再输入decoder来预测下一个单词,循环往复直至end。ingFang SC", Cambria, Cochin, Georgia, Times, "Times New Roman", serif;letter-spacing: normal;text-align: left;background-color: rgb(255, 255, 255);border-bottom: 2px solid rgb(239, 112, 96);visibility: visible;">【4】Attention的计算方式以及参数量,Attention Layer代码手写【4】Attention的计算方式以及参数量,Attention layer代码手写。1. 缩放点积注意力:Scaled Dot-Product Attention 
根据上面的公式,直觉上会觉得attention只有3个矩阵。但是transformer中使用的是Multi-Head Attention,会多出一个输出权重矩阵,变成4个矩阵。(划重点)为什么多出一个输出权重矩阵?请看原论文中的图解,各个head的结果concat后会再过一个linear层,这个linear层就是输出权重矩阵。2.Multi-head Attention 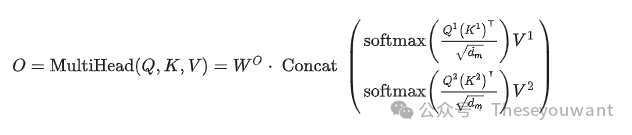
为什么这个输出权重矩阵??变得重要,大模型时代参数量激增,如果有个矩阵被遗忘了,那么参数量就完全算不准了。 Attention的参数量: 
上面是一个简化的算法,multi-head attention也符合这个参数量,但实际上需要分head计算再组合。
值得关注的点是: 1.偏置矩阵有没有用?在实现Q、K、V矩阵时是有一个参数bias的。不同模型设置不同,从代码观察到,LLaMA没有用(划重点),ChatGLM v1用了,这里参数量不同,但因为是1次项,所以几乎不影响参数量。
2.一般hidden size是多少?LLaMA从4096到8192。可以记住7B模型是,32个头,每个小矩阵[128*4096] 
手写Attention代码 以前self-attention的考察针对BERT,但是大模型时代有所不同,主要是以下4点。 现在生成式大模型的attention实现,涉及到RoPE和KVcache,前者是最主流的位置编码,后者是decoder-only模型必备的加速解码手段。另外,decoder-only模型是单向注意力,attentionmask是下三角阵。LLM的模型参数大都是fp16的,但softmax时用fp32计算。 使用hf的代码实现(删掉RoPE)代码如下: fromtorchimportnn
classLlamaAttention(nn.Module):
"""Multi-headedattentionfrom'AttentionIsAllYouNeed'paper"""
def__init__(self,config lamaConfig): lamaConfig):
super().__init__()
self.config=config
self.hidden_size=config.hidden_size
self.num_heads=config.num_attention_heads
self.head_dim=self.hidden_size//self.num_heads
self.max_position_embeddings=config.max_position_embeddings
self.q_proj=nn.Linear(self.hidden_size,self.num_heads*self.head_dim,bias=False)
self.k_proj=nn.Linear(self.hidden_size,self.num_heads*self.head_dim,bias=False)
self.v_proj=nn.Linear(self.hidden_size,self.num_heads*self.head_dim,bias=False)
self.o_proj=nn.Linear(self.num_heads*self.head_dim,self.hidden_size,bias=False)
defforward(
self,
hidden_states:torch.Tensor,
attention_mask:Optional[torch.Tensor]=None,
position_ids:Optional[torch.LongTensor]=None,
past_key_value:Optional[Tuple[torch.Tensor]]=None,
output_attentions:bool=False,
use_cache:bool=False,
)->Tuple[torch.Tensor,Optional[torch.Tensor],Optional[Tuple[torch.Tensor]]]:
bsz,q_len,_=hidden_states.size()
#获得qkv向量
query_states=self.q_proj(hidden_states).view(bsz,q_len,self.num_heads,self.head_dim).transpose(1,2)
key_states=self.k_proj(hidden_states).view(bsz,q_len,self.num_heads,self.head_dim).transpose(1,2)
value_states=self.v_proj(hidden_states).view(bsz,q_len,self.num_heads,self.head_dim).transpose(1,2)
#拼接kvcache
kv_seq_len=key_states.shape[-2]
ifpast_key_valueisnotNone:
kv_seq_len+=past_key_value[0].shape[-2]
ifpast_key_valueisnotNone:
#reusek,v,self_attention
key_states=torch.cat([past_key_value[0],key_states],dim=2)
value_states=torch.cat([past_key_value[1],value_states],dim=2)
past_key_value=(key_states,value_states)ifuse_cacheelseNone
#计算attention权重
attn_weights=torch.matmul(query_states,key_states.transpose(2,3))/math.sqrt(self.head_dim)
#加入mask矩阵,decoder-only为下三角
ifattention_maskisnotNone:
attn_weights=attn_weights+attention_mask
dtype_min=torch.tensor(
torch.finfo(attn_weights.dtype).min,device=attn_weights.device,dtype=attn_weights.dtype
)
attn_weights=torch.max(attn_weights,dtype_min)
#计算softmax,这里需要从fp16升为fp32
#upcastattentiontofp32
attn_weights=nn.functional.softmax(attn_weights,dim=-1,dtype=torch.float32).to(query_states.dtype)
attn_output=torch.matmul(attn_weights,value_states)
attn_output=attn_output.transpose(1,2)
attn_output=attn_output.reshape(bsz,q_len,self.hidden_size)
attn_output=self.o_proj(attn_output)
ifnotoutput_attentions:
attn_weights=None
LLaMA的huggingface实现:https://github.com/huggingface/transformers/blob/main/src/transformers/models/llama/modeling_llama.py#L207 meta仓库的原版实现:https://github.com/meta-llama/llama/blob/main/llama/model.py#L76
【★】大模型八股答案基础知识-suc16【202310】:https://zhuanlan.zhihu.com/p/643829565 附简易面试专用版代码如下:
importtorch
importtorch.nnasnn
importtorch.nn.functionalasF
importmath
classMultiHeadAttention(nn.Module):
def__init__(self,d_model,num_heads):
super(MultiHeadAttention,self).__init__()
self.num_heads=num_heads
self.d_model=d_model
assertd_model%self.num_heads==0
#Definethedimensionofeachheadorsubspace
self.d_k=d_model//self.num_heads
#Thesearestillofdimensiond_model.Theywillbesplitintonumberofheads
self.W_q=nn.Linear(d_model,d_model)
self.W_k=nn.Linear(d_model,d_model)
self.W_v=nn.Linear(d_model,d_model)
#Outputsofallsub-layersneedtobeofdimensiond_model
self.W_o=nn.Linear(d_model,d_model)
defscaled_dot_product_attention(self,Q,K,V,mask=None):
batch_size=Q.size(0)
K_length=K.size(-2)
#Scalingbyd_ksothatthesoft(arg)maxdoesn'texplode
QK=torch.matmul(Q,K.transpose(-2,-1))/math.sqrt(self.d_k)
#Applythemask
ifmaskisnotNone:
QK=QK.masked_fill(mask.to(QK.dtype)==0,float('-inf'))
#Calculatetheattentionweights(softmaxoverthelastdimension)
weights=F.softmax(QK,dim=-1)
#Applytheselfattentiontothevalues
attention=torch.matmul(weights,V)
returnattention,weights
defsplit_heads(self,x,batch_size):
"""
Theoriginaltensorwithdimensionbatch_size*seq_length*d_modelissplitintonum_heads
sowenowhavebatch_size*num_heads*seq_length*d_k
"""
returnx.view(batch_size,-1,self.num_heads,self.d_k).transpose(1,2)
defforward(self,q,k,v,mask=None):
batch_size=q.size(0)
#linearlayers
q=self.W_q(q)
k=self.W_k(k)
v=self.W_v(v)
#splitintomultipleheads
q=self.split_heads(q,batch_size)
k=self.split_heads(k,batch_size)
v=self.split_heads(v,batch_size)
#selfattention
scores,weights=self.scaled_dot_product_attention(q,k,v,mask)
#concatenateheads
concat=scores.transpose(1,2).contiguous().view(batch_size,-1,self.d_model)
#finallinearlayer
output=self.W_o(concat)
returnoutput,weights
在面试中还被问到过一点,出于运算速度的考虑,认为“一次大的矩阵乘法的执行速度实际上比多次较小的矩阵乘法更快”,因此你也可以:
self.qkv=nn.Linear(d_model,3*d_model)
#在forward方法中
qkv=self.qkv(x)#(batch_size,seq_len,3*d_model)
q,k,v=torch.split(qkv,d_model,dim=-1)#splitintothreetensors 【★】大模型面试八股-花甘者浅狐【202307】:https://zhuanlan.zhihu.com/p/643560888 【5】为什么Scaled Dot-product Attention在计算QK内积之后要除以根号dk?【5】在Transformer模型中,为什么Scaled Dot-product Attention在计算QKᐪ内积之后要除以根号dk?【dk是词向量/隐藏层的维度】 Self-Attention计算公式:
简单来说,就是需要压缩softmax输入值,以免输入值过大,进入了softmax的饱和区,导致梯度值太小而难以训练。如果不对attention值进行scaling,也可以通过在参数初始化时将方差除以根号dk ,同样可以起到预防softmax饱和的效果。 Scaling后进行softmax操作可以使得输入的数据的分布变得更好,想象softmax的公式,数值会进入softmax敏感区间,能够防止梯度消失,让模型能够更容易训练。
#Self-Attention为什么要除以根号d_k?:除以根号dk缩放后注意力分数矩阵中分数的方差由原来的缩小到了1,方差越小,点积的数量级越小。选择根号d_k是因为可以使得QKᐪ的结果满足期望为0,方差为1的分布,类似于归一化。论文中作者的解释是发现当维度dk值很大时,输入softmax的值QKᐪ就越大,会导致后面的softmax计算会有极小的梯度,不利于更新学习,因此除以dk,防止梯度消失。
【★】Self-Attention为什么要除以根号d_k【20231026】:https://blog.csdn.net/tailonh/article/details/120544719
#有其他方法不用除根号dk吗?有,只要能缓解梯度消失的问题就可以。详情可以了解Google T5的Xavier初始化。https://kexue.fm/archives/8620 【6】为什么Q和K要使用不同的权重矩阵进行线性变换投影?【6】Transformer自注意力计算中,为什么Q和K要使用不同的权重矩阵进行线性变换投影?Self-Attention计算公式:
#为什么要计算Q和K的点乘?1.先从点乘的物理意义说,两个向量的点乘表示两个向量的相似度。2. Q,K,V物理意义上是一样的,都表示同一个句子中不同token组成的矩阵。矩阵中的每一行,是表示一个token的word embedding向量。假设一个句子"Hello, how are you?"长度是6,embedding维度是300,那么Q,K,V都是(6, 300)的矩阵。简单的说,K和Q的点乘是为了计算一个句子中每个token相对于句子中其他token的相似度,这个相似度可以理解为attention score,关注度得分。比如说"Hello, how are you?"这句话,当前token为”Hello"的时候,我们可以知道”Hello“对于” , “, "how", "are", "you", "?"这几个token对应的关注度是多少。有了这个attention score,可以知道处理到”Hello“的时候,模型在关注句子中的哪些token。
#为什么Q和K要使用不同的权重矩阵进行线性变换投影?经过上面的解释,知道K和Q的点乘是为了得到一个attention score 矩阵,用来对V进行提纯。K和Q使用了不同的Wk, WQ来计算,可以理解为是在不同空间上的投影。正因为有了这种不同空间的投影,增加了表达能力,这样计算得到的attention score矩阵的泛化能力更高。这里解释下我理解的泛化能力,因为K和Q使用了不同的Wk, WQ来计算,得到的也是两个完全不同的矩阵,所以表达能力更强。但是如果不用Q,直接拿K和K点乘的话,你会发现attention score 矩阵是一个对称矩阵。因为是同样一个矩阵,都投影到了同样一个空间,所以泛化能力很差。这样的矩阵导致对V进行提纯的时候,效果也不会好。
【★】transformer中为什么使用不同的K 和 Q,为什么不能使用同一个值?【201906】:https://www.zhihu.com/question/319339652/answer/730848834
为什么Q和K要使用不同的权重矩阵进行线性变换投影?如果WQ和WK一样,则矩阵乘积的结果是一个对称矩阵,这样减弱了模型的表达能力。如果Q和K一样,乘积结果的对称矩阵中,对角线的值会比较大,导致每个位置过分关注自己。使用不同的投影矩阵,参数增多,可以增强模型表达能力。 【7】Transformer结构参数量的推演,和显存占用关系的推演。【7】Transformer结构参数量的推演,和显存占用关系的推演。
Decoder-only模型参数量回旋托马斯x:分析transformer模型的参数量、计算量、中间激活、KV cache2221 赞同 · 276 评论文章 1.现在都是fp16或者bf16训练和推理,那么如果是1个100亿参数量的模型(也就是储存了100亿个参数),它其实是一个10B大小的模型。(1Billion等于10的9次方,也就是10亿)2.1个字节占8bits,那么fp16就是占2个字节(Byte),那么10B模型的模型大小是20GB,是*2的关系。
那么对于 n B模型: 1.推理时显存的下限是 2n GB ,至少要把模型加载完全。 2.训练时,如果用Adam优化器,有个2+2+12的公式,训练时显存下限是16n GB,需要把模型参数、梯度和优化器状态(4+4+4),保持在显存,具体可以参考微软的ZeRO论文。
【★】分析transformer模型的参数量、计算量、中间激活、KV cache【202304】:https://zhuanlan.zhihu.com/p/624740065 【8】Self-Attention的计算过程【8】Self-Attention的计算过程图解 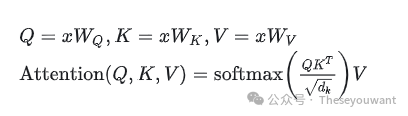
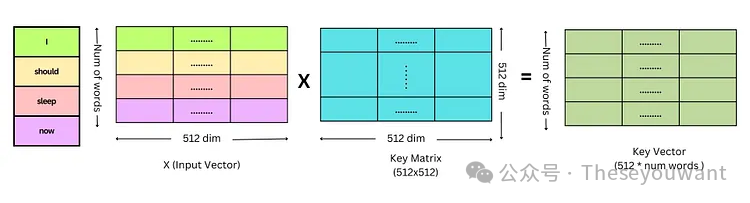
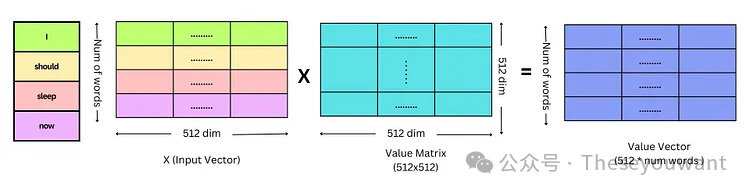
注:X, Q, K, V 的行数表示单词个数。X的列数表示词向量维度。dk是Q,K矩阵的列数,即词向量维度。
1.对Embedding词向量矩阵X与权重矩阵 相乘,得到Q,K,V矩阵。 相乘,得到Q,K,V矩阵。 2.将Q矩阵和K矩阵相乘,再除以√dk得到缩小后的score矩阵,计算score矩阵的softmax。 3.将softmax后的score矩阵与该单词的V矩阵相乘,最后对n个上述结果求和就得到了self-attention的输出结果Z。
某个单词Zi 的计算方法: softmax后的score矩阵的第 1 行表示单词 1 与其他所有单词的 attention 系数。最终单词 1 的输出?1 等于所有单词 i 的值??根据 attention 系数的比例加在一起得到,如下图所示:

Q,K,V矩阵的计算 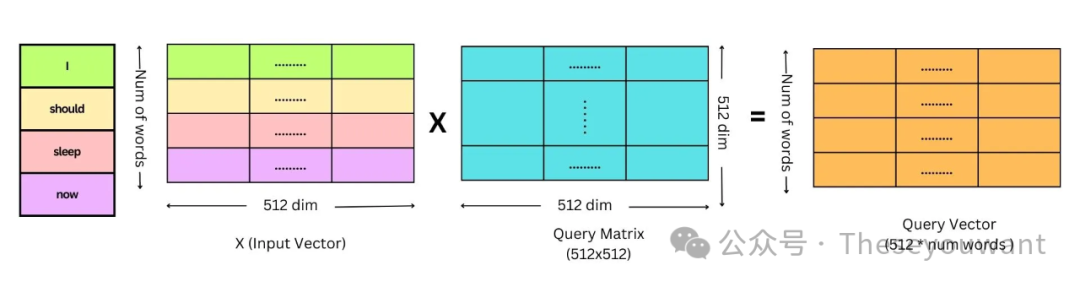
Self-Attention的计算 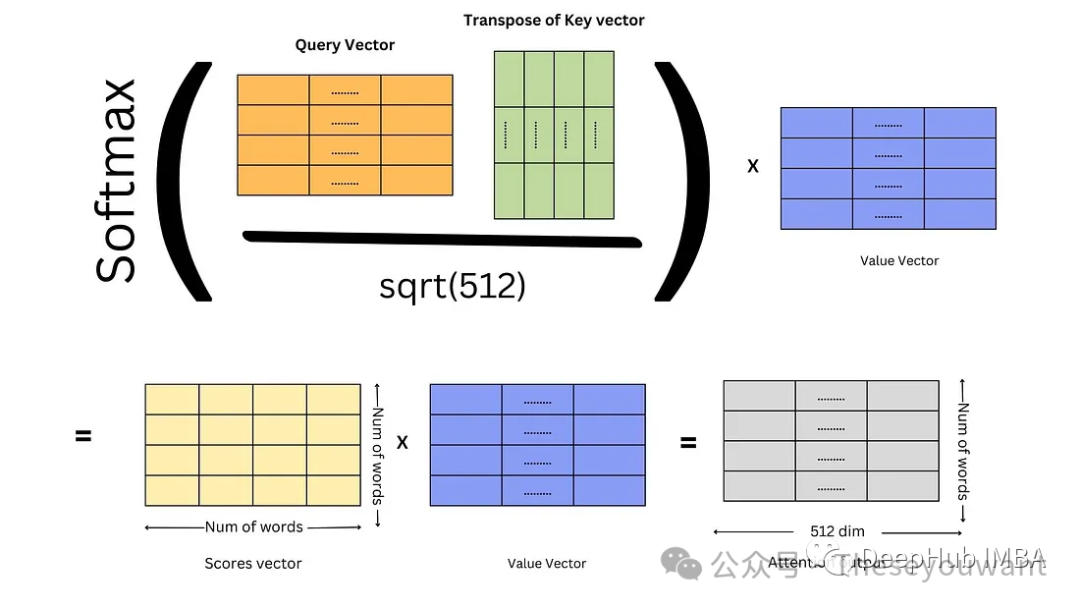
【9】Decoder端的Encoder-Decoder Attention的作用【9】Decoder端的Encoder-Decoder Attention作用? 多头Encoder-Decoderattention交互模块的形式与多头self-attention模块一致,唯一不同的是其Q,K,V矩阵的来源,其Q矩阵来源于下面子模块的输出(对应到图中即为 masked 多头 self-attention 模块经过 Add & Norm 后的输出),而K,V矩阵则来源于整个 Encoder 端的输出。 仔细想想其实可以发现,这里的交互模块就跟 seq2seq with attention 中的机制一样,目的就在于让 Decoder 端的单词(token)给予 Encoder 端对应的单词(token)“更多的关注(attention weight)”。
【10】Transformer中为什么舍弃BN改用LN?【10】Transformer为什么要舍弃BatchNormalization改用LayerNormalization呢?1.NLP中主流就是用LN,实验结果显示Layer Normalization这样做效果更好! 2.Transformer主要用的是Scaled-DotSelfAttention,里边的q,k是做内积的,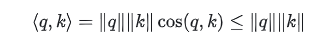 LN本质上是L2 Normalzation的简单变体,一般是LN之后再接一个Dense变换,这样||q||,||k||就会一定程度上得到控制,从而使Attention的值在合理范围内,不至于梯度消失/爆炸。如果换成BN,对||q||, ||k||的控制就没那么有效了。
为什么要做归一化:第一,归一化是有好处的,但不足以让归一化成为必选项。第二,以前主流的观点缓解ICS其实并不准确。第三,由于Variance Shift,对深层网络而言,归一化几乎是必选项。
探讨要做什么样的归一化(能在哪些维度做归一化)。对NLP(transformer)而言,对每个token的embedding也是经过叠加其他embedding产生的,所以对embedding进行归一化是必要操作。这就是layer normalization。
任何norm的意义都是为了让使用norm的网络的输入的数据分布变得更好,也就是转换为标准正态分布,数值进入敏感度区间,以减缓梯度消失,从而更容易训练。当然,这也意味着舍弃了除此维度之外其他维度的其他信息。
| 









