PEFT(Parameter-Efficient Fine-Tuning)是一种在保持预训练模型大部分参数不变的情况下,通过仅调整少量额外参数来适应新任务的技术。这些额外参数可以是新添加的嵌入层、低秩矩阵或其他类型的参数,它们被用来“引导”或“调整”预训练模型的输出,以使其更适合新任务。ingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;letter-spacing: 0.034em;">Parameter-Efficient Fine-TuningingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;letter-spacing: 0.034em;">PEFT的主要方法包括ingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;letter-spacing: 0.034em;">Prefix Tuning(在模型输入层添加可训练的前缀嵌入),LoRA(通过低秩矩阵近似模型参数更新),以及Adapter Tuning(在模型层间插入小型神经网络adapters)。ingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;letter-spacing: 0.034em;"> ingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;letter-spacing: 0.034em;">Parameter-Efficient Fine-Tuning ingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;letter-spacing: 0.034em;">Parameter-Efficient Fine-Tuning
ingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", "Source Han Sans CN", sans-serif, "Apple Color Emoji", "Segoe UI Emoji";font-size: 15px;line-height: 1.7;color: rgb(5, 7, 59);letter-spacing: normal;text-align: start;text-wrap: wrap;background-color: rgb(253, 253, 254);" class="list-paddingleft-1">Prefix Tuning LoRA(Low-Rank Adaptation) Adapter Tuning ingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;letter-spacing: 0.034em;">Parameter-Efficient Fine-TuningingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;letter-spacing: 0.034em;"> ingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;letter-spacing: 0.034em;">
ingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;letter-spacing: 0.544px;visibility: visible;">一、Prefix Tuning(前缀微调) 什么是Prefix Tuning?Prefix Tuning在原始文本进行词嵌入之后,在前面拼接上一个前缀矩阵,或者将前缀矩阵拼在模型每一层的输入前。这个前缀与输入序列一起作为注意力机制的输入,从而影响模型对输入序列的理解和表示。由于前缀是可学习的,它可以在微调过程中根据特定任务进行调整,使得模型能够更好地适应新的领域或任务。Transformer进行Prefix Tuning?对Transformer进行Prefix Tuning以实现问答、文本分类等自然语言处理任务。主要步骤包括在Transformer模型的输入层或各层输入前添加可学习的前缀嵌入,并通过训练这些前缀嵌入来优化模型在特定任务上的表现。初始化前缀嵌入
将前缀嵌入与输入序列拼接 训练模型 微调与优化 什么是LoRA?LoRA(Low-Rank Adaptation)基于预训练模型具有较低的“内在维度”(intrinsic dimension)的假设,即模型在任务适配过程中权重的改变量可以是低秩的。LoRA通过在预训练模型中引入一个额外的线性层(由低秩矩阵A和B组成),并使用特定任务的训练数据来微调这个线性层,从而实现对模型的高效微调。什么是低秩矩阵?低秩矩阵的秩(即矩阵中最大的线性无关行或列向量的个数)远小于矩阵的行数或列数。LoRA将预训练模型的权重矩阵的增量(即微调前后的权重差异)分解为一个低秩矩阵A和一个原始矩阵B的乘积,即ΔW = AB。在微调过程中,仅训练低秩矩阵A的参数,而保持原始矩阵B和预训练模型的其他部分不变。LoRA参数主要包括秩(lora_rank,影响性能和训练时间)、缩放系数(lora_alpha,确保训练稳定)、Dropout系数(lora_dropout,防止过拟合)和学习率(learning_rate,控制权重更新步长),它们共同影响模型微调的效果和效率。1.秩(Rank)2.缩放系数(Alpha)3.Dropout系数4.学习率(Learning Rate)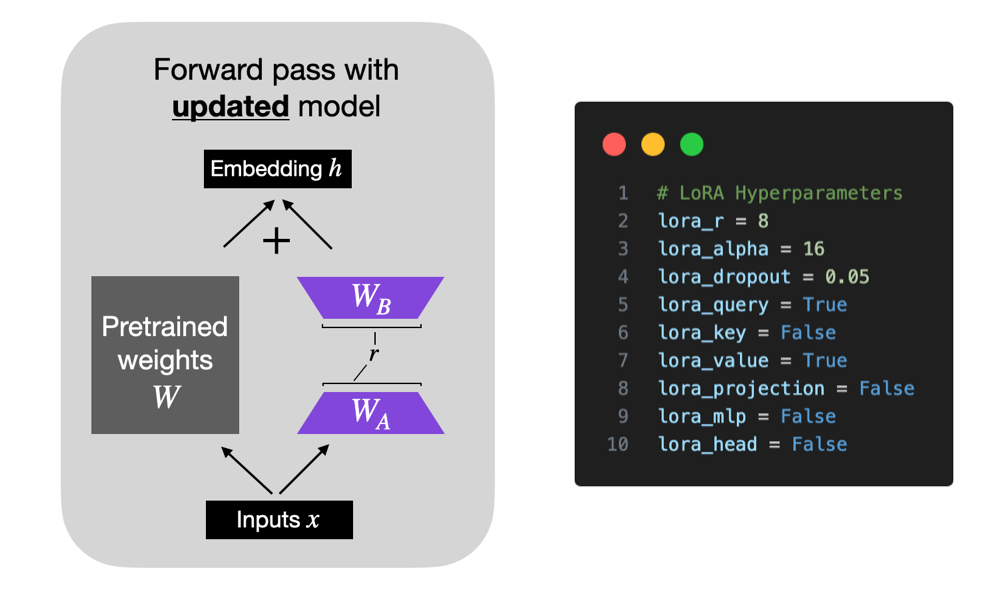
什么是Adapter Tuning?Adapter Tuning能够在保持模型参数数量相对较小的情况下,通过增加少量可训练参数(即适配器)来提高模型在特定任务上的表现。Adapter Tuning的核心思想是在预训练模型的中间层中插入小的可训练层或“适配器”。这些适配器通常包括一些全连接层、非线性激活函数等,它们被设计用来捕获特定任务的知识,而不需要对整个预训练模型进行大规模的微调。
Adapter Tuning如何实现?Adapter Tuning在预训练模型中插入设计的适配器模块,仅训练这些模块参数以微调模型,同时保持预训练模型参数不变,并在特定任务数据集上评估性能。AdapterTuning 准备环境:安装并配置好深度学习框架(如 PyTorch 或 TensorFlow)和相关的库,这些框架和库将用于模型的训练、评估和部署。 定义 Adapter 模块:根据任务的具体需求,设计适配器的结构。适配器通常包括输入层、输出层、可能的下投影和上投影前馈层(用于调整特征的维度),以及非线性激活函数等。这些组件共同构成了能够学习特定任务知识的轻量级模块。 在预训练模型中插入 Adapter:将设计好的适配器模块插入到预训练模型的特定位置,通常是 Transformer 架构中的某些层之间,比如两个全连接层(也称为前馈网络或FFN)之间。这样做可以使得适配器能够捕获并转换经过该层的特征表示,从而适应新的任务。 准备数据集:收集并处理用于微调的数据集,包括训练集、验证集和测试集。这些数据集应该能够反映目标任务的特性,以便模型能够从中学习到有效的表示和决策规则。 定义模型:将预训练模型与插入的适配器模块相结合,定义出完整的模型结构。在这个过程中,需要确保模型能够正确地处理输入数据,并通过适配器模块进行特征的转换和提取。 训练模型:在特定任务的数据集上训练模型。在训练过程中,只调整适配器模块的参数,而保持预训练模型的主要参数不变。这样做可以保持预训练模型在通用任务上的性能,同时使模型能够快速适应新的特定任务。 评估模型:在测试集上评估模型的性能。通过比较模型在测试集上的预测结果与实际标签之间的差异,可以评估模型在特定任务上的准确性和泛化能力。根据评估结果,可以对模型进行进一步的调整和优化。
|










