|
ingFang SC", system-ui, -apple-system, BlinkMacSystemFont, "Helvetica Neue", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;letter-spacing: 0.544px;background-color: rgb(255, 255, 255);visibility: visible;">FastChat是加州大学伯克利分校LM-SYS发布的一个用于训练、服务和评估基于大型语言模型的聊天机器人的开放平台。
项目地址:https://github.com/lm-sys/FastChat.git ingFang SC", system-ui, -apple-system, BlinkMacSystemFont, "Helvetica Neue", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;letter-spacing: 0.544px;background-color: rgb(255, 255, 255);visibility: visible;">其核心功能包括:ingFang SC", system-ui, -apple-system, BlinkMacSystemFont, "Helvetica Neue", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;letter-spacing: 0.544px;background-color: rgb(255, 255, 255);visibility: visible;">ingFang SC", system-ui, -apple-system, BlinkMacSystemFont, "Helvetica Neue", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;letter-spacing: 0.544px;background-color: rgb(255, 255, 255);visibility: visible;">ingFang SC", system-ui, -apple-system, BlinkMacSystemFont, "Helvetica Neue", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;letter-spacing: 0.544px;background-color: rgb(255, 255, 255);visibility: visible;">最先进 LLM 模型的权重、训练代码和评估代码。ingFang SC", system-ui, -apple-system, BlinkMacSystemFont, "Helvetica Neue", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;letter-spacing: 0.544px;background-color: rgb(255, 255, 255);visibility: visible;">ingFang SC", system-ui, -apple-system, BlinkMacSystemFont, "Helvetica Neue", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;letter-spacing: 0.544px;background-color: rgb(255, 255, 255);visibility: visible;">带有 WebUI 和与 OpenAI 兼容的 RESTful API 的分布式多模型服务系统,可以平替,无缝迁移OpenAI GPT接口。ingFang SC", system-ui, -apple-system, BlinkMacSystemFont, "Helvetica Neue", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;letter-spacing: 0.544px;background-color: rgb(255, 255, 255);visibility: visible;">ingFang SC", system-ui, -apple-system, BlinkMacSystemFont, "Helvetica Neue", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;letter-spacing: 0.544px;background-color: rgb(255, 255, 255);visibility: visible;">提供了 WebUI 界面方便用户通过浏览器来使用 LLM。ingFang SC", system-ui, -apple-system, BlinkMacSystemFont, "Helvetica Neue", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;letter-spacing: 0.544px;background-color: rgb(255, 255, 255);visibility: visible;">
支持主流模型部署: FastChat支持多种模型,包括LLama 2, Vicuna, Alpaca, Baize, ChatGLM, Dolly, Falcon, FastChat- t5, GPT4ALL, Guanaco, MTP, OpenAssistant, RedPajama, StableLM, WizardLM等。 优点: Fastchat除了WebUI让大家便捷的使用和测试大模型外,还提供了restful API的服务调用方式,并且它提供的API与OpenAI开放出的API完全兼容,意味着以前大家基于OpenAI的API构建的一系列应用都可以无需任何改动,直接运行在FastChat框架上。 一个显而易见的好处就是,通过OpenAI的GPT模型已经获得原型验证甚至商业成功的应用,都可以采用这个框架将应用服务完整迁移到本地,通过选择开源的大模型即可实现私有化大模型服务部署,避免了数据出域、隐私安全等一系列问题。 
2.2.1 FastChat Server架构Fastchat的部署采用的架构是master-slave的模式, 由一个controller控制多个worker进行统筹管理。主要包括四个部分: 部署controller用于控制worker。 部署worker,然后worker注册到controller。 部署API服务,提供OpenAI API兼容的接口,可以平替OpenAI接口。 FastChat WebUI, Gradio Server,方便通过界面聊天
准备环境(可用智星云云服务器)
克隆代码gitclonehttps://github.com/lm-sys/FastChat.gitcdFastChat 创建虚拟环境python-mvenvenvsourceenv/bin/activate
设置依赖镜像和版本pip3configsetglobal.index-urlhttps://mirrors.bfsu.edu.cn/pypi/web/simplepip3configsetinstall.trusted-hostmirrors.bfsu.edu.cn 安装依赖pip3install--upgradepippip3install-e".[model_worker,webui]"pip3installgit+https://github.com/huggingface/transformerspip3installtransformers_stream_generatoreinop
安装成功 
注意:HuggingFace 在国内不能访问,可以切换到使用 ModelScope 的镜像。环境变量需要设置:export FASTCHAT_USE_MODELSCOPE=True FastChat API 部署第一步是启动控制器服务,启动命令: python-mfastchat.serve.controller--host0.0.0.0 用这种方式,可以后台运行
python-mfastchat.serve.controller--host0.0.0.0&
这次运行的FastChat的fastchat.serve.controller命令,--host参数是设置服务的主机地址,这里设置为0.0.0.0,表示可以通过任何地址访问,服务启动后默认端口是21001,端口可以修改 通过 --port执定。如果想该命令的更多信息可以执行python -m fastchat.serve.controller --help命令。 第二步是启动 Model Worker 服务,启动命令: pipinstall-Uhuggingface_hubexportHF_ENDPOINT=https://hf-mirror.comhuggingface-clidownload--resume-downloadQwen/Qwen-1_8B-Chat--local-dirQwen/Qwen-1_8B-Chat
exportCUDA_VISIBLE_DEVICES=0python-mfastchat.serve.model_worker\--model-pathQwen/Qwen-1_8B-Chat\--model-namesgpt-3.5-turbo\--port21002\--worker-addresshttp://localhost:21002
使用 FastChat 的fastchat.serve.model_worker命令来启动服务,通过--model-path参数来指定 LLM 的路径,服务启动后默认端口是 21002,可以通过--port参数来修改端口,如果想查看该命令的更多信息可以执行python -m fastchat.serve.model_worker --help命令,首次启动会下载模型,比较慢。 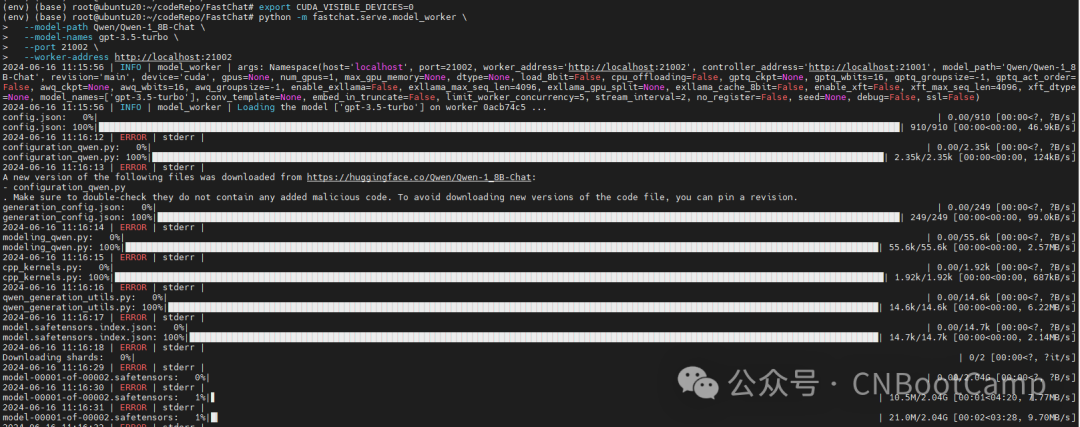
第三步是启动 RESTFul API 服务,启动命令:后面加&符号表示后台运行 python-mfastchat.serve.openai_api_server--host0.0.0.0--port8800

服务启动后,默认端口是8000,可以通过--port参数来修改端口,在浏览器中访问服务的这个路径http://127.0.0.1:8800/docs可以查看接口信息,这个服务就是我们最终要用的LLM API 服务,它的接口跟OpenAI 的接口是兼容的: 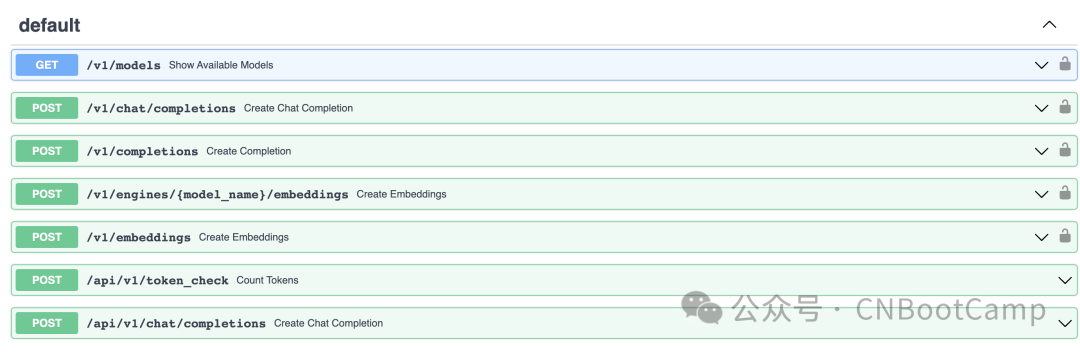
我们可以在Swagger里面直接请求对应的接口 
第四步,FastChat WebUI 部署,不是必须启动项目
定义api_endpoints.json {"gpt-3.5-turbo":{"model_name":"gpt-3.5-turbo","api_type":"openai","api_base":"http://127.0.0.1:8800/v1","api_key":"sk-******","anony_only":false,"recommended_config":{"temperature":0.7,"top_p":1.0},"text-arena":true,"vision-arena":false}}
启动gradio_web_server python3-mfastchat.serve.gradio_web_server--port8801--controller""--share--registerapi_endpoints.json 遇到OPENAI_API_KEY 错误,运行:export OPENAI_API_KEY='api_key'
遇到markupsafe 按这个版本安装:pip install markupsafe==2.0.1 
服务默认端口是 7860,可以通过--port参数来指定端口,还可以通过添加--share参数来开启 Gradio 的共享模式,这样就可以通过外网访问 WebUI 服务。 启动后我们会得到这样一个界面,这个界面类似ChatGPT,可以用来生成内容。 
接口参数含义: temperature:大于等于零的浮点数。果取值为0,此时推理几乎没有随机性;取值为正无穷时接近于取平均。一般temperature取值介于[0, 1]之间。取值越高输出效果越随机。如果该问答只存在确定性答案,则T值设置为0。反之设置为大于0。 top_k:大于0的正整数。从k个概率最大的结果中进行采样。k越大多样性越强,越小确定性越强。一般设置为20~100之间。 top_p:大于0的浮点数。使所有被考虑的结果的概率和大于p值,p值越大多样性越强,越小确定性越强。一般设置0.7~0.95之间。 repetition_penalty:大于等于1.0的浮点数。如何惩罚重复token,默认1.0代表没有惩罚。
|










