• 用户层:API 拦截和 API forwarding。• 内核层:GPU 驱动拦截;GPU 驱动半虚拟化:Para Virtualization。SRIOV:Single Root I/O Virtualization;Nvidia MIG:Multi-Instance GPU。
(一)GPU 用户层虚拟化技术
用户层虚拟化技术包含本地 API 拦截和 API forwarding、远程 API forwarding、半虚拟化 API forwarding三种。
技术1:本地 API 拦截和 API forwarding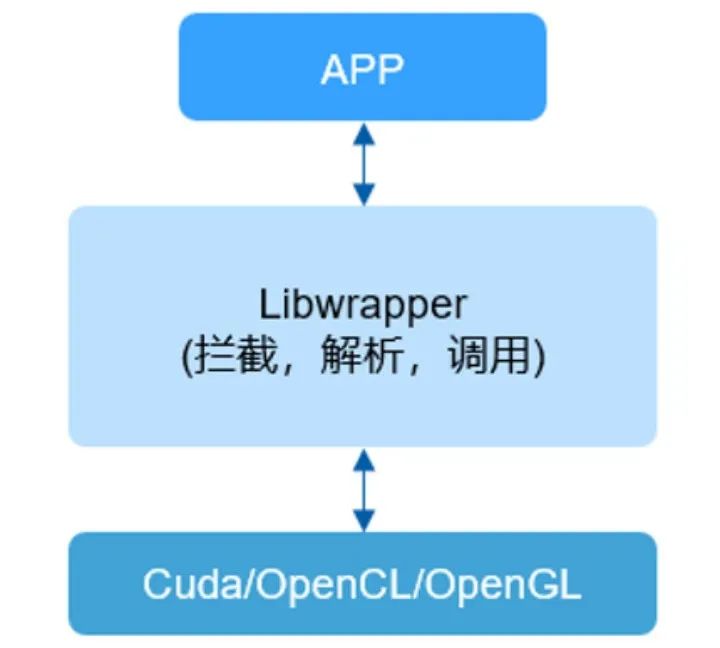
图3:本地 API 拦截和 API forwarding
通过在用户态创建一个中间库,拦截应用程序对底层 GPU 库的调用,并在中间库中处理和转发这些调用,从而实现对 GPU 资源的虚拟化管理。
1.应用调用 libwrapper:应用程序(APP)调用 libwrapper 中的函数。
2.拦截和解析:libwrapper拦截应用的函数调用,解析参数。
3.调用底层库:使用解析后的参数,通过 dlopen 动态打开底层库,调用相同名称的函数。
4.返回结果: 调用完成后,libwrapper 将结果返回给应用程序。
• 静态链接变动态链接:应用程序和底层库的静态链接需要变为动态链接。
• 动态库加载:libwrapper需要使用 dlopen 动态加载底层库。
我们可以通过GPU 用户层的 API 拦截与转发技术实现在用户态对底层库的 API 调用进行控制和管理。
技术2:远程 API forwarding

图4:远程 API forwarding
远程 API 转发技术允许 GPU 资源在不同的物理机器之间共享。通过将 GPU 调用转发到远程机器上的底层库,系统可以实现 GPU 资源池化,从而使不具备 GPU 的机器也能够利用 GPU 进行计算。
1.网络调用底层库:libwrapper 通过网络调用位于不同机器上的底层库。
2.库分为两部分:客户端(client):负责转发请求;服务器端(server):负责接收请求并调用底层库。
3.GPU 池化: 可以将多个 GPU 组成调用池,允许多个客户端调用这些 GPU,从而实现让不具备 GPU 的机器也能使用 GPU 的功能。
• 类似 RPC 的函数调用:调用函数需要进行参数的序列化和反序列化。
• 性能优化:对于本机来说,远程数据传输的性能对函数调用的延迟影响很大。通常可以通过 RDMA(远程直接内存访问)进行网络加速。
该技术可以实现远程 GPU 的 API 转发,优化 GPU 资源的利用,增强系统的计算能力。
技术3:半虚拟化 API forwarding
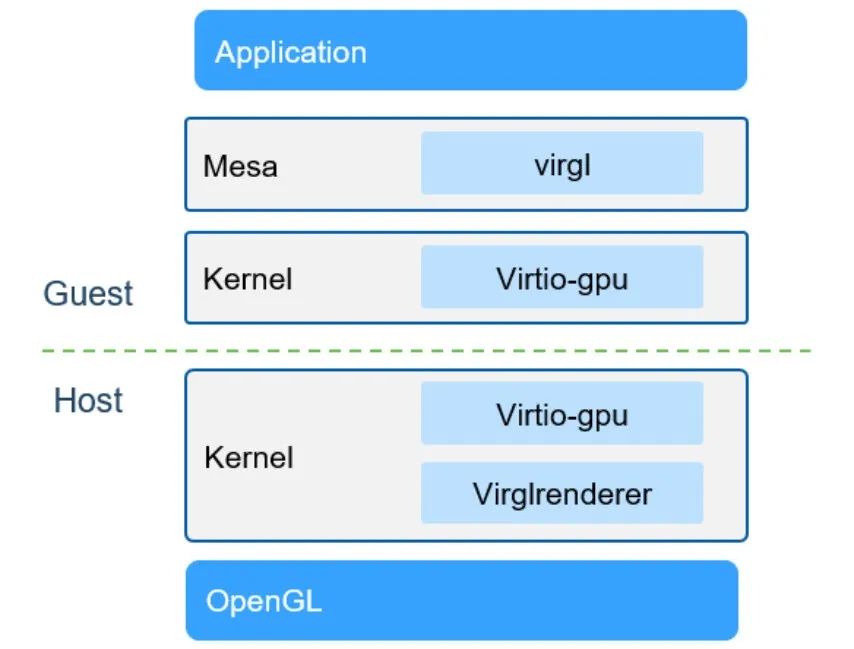
图5:virgl+virtio-gpu实现
半虚拟化API 转发技术通过虚拟化和半虚拟化的方式,实现虚拟机中的应用程序对宿主机GPU资源的调用,从而在虚拟化环境中高效地利用GPU资源。
1. 虚拟机中的运行环境:应用程序(APP)和libwrapper在虚拟机中运行。2. 半虚拟化通讯:libwrapper通过半虚拟化方式(virtio)进行通讯,调用宿主机的底层库。• 虚拟机内核实现virtio frontend。• 宿主机的hypervisor实现virtio backend。
• 共享内存:virtio通过共享内存的方式在虚拟机和宿主机之间共享数据,减少了数据拷贝。
通过半虚拟化API转发技术,可以实现虚拟机环境下的GPU半虚拟化API转发,有效利用宿主机的GPU资源。
(二)GPU内核层虚拟化
内核层虚拟化技术包含内核层GPU驱动拦截和内核层GPU驱动半虚拟化两种。

图6:内核层GPU驱动拦截
内核层GPU驱动拦截技术通过在内核中创建一个模块来拦截对GPU驱动的访问,从而实现对GPU资源的虚拟化管理。此方法适用于容器化应用。
1. 设备文件拦截:底层库通常通过设备文件(如 /dev/realgpu)访问GPU驱动的功能。2. 内核模块创建模拟设备文件:实现一个内核模块,输出模拟的设备文件/dev/fakegpu给用户空间。3. 伪装设备文件:将模拟的设备文件通过bind mount的方式挂载到容器中,伪装成真正的设备文件/dev/realgpu。4. 容器内运行环境:应用程序(APP)和底层库都在容器内运行。底层库访问伪装的设备文件/dev/realgpu,此时所有访问都被内核模块拦截。• 理解系统调用:需要了解底层库调用GPU驱动的系统调用的具体含义。
• 拦截必要调用:内核拦截模块只需要拦截必要的系统调用。这项技术使得GPU资源可以在容器化环境中被有效地虚拟化和管理。用户进程通过系统虚拟化层(hypervisor)提供的虚拟化接口,访问(真实的)虚拟化接口。

图7:GPU驱动半虚拟化
内核层GPU驱动半虚拟化技术通过在虚拟机环境中实现对GPU资源的虚拟化管理,适用于虚拟机应用。
1. 虚拟机内的运行环境:应用程序(APP)和底层库都在虚拟机中运行。2. 半虚拟化接口:虚拟机的GPU驱动实现半虚拟化接口,通过类似hypercall的方式调用宿主机实际的GPU驱动。3. hypercall机制:hypercall切换虚拟机(guest)到虚拟机管理程序(hypervisor),由hypervisor通过内核中的驱动代理来访问实际的GPU驱动。• 适用范围:适用于虚拟机应用。
通过该技术,可以在虚拟机环境中高效地虚拟化和管理GPU资源。
(三)GPU硬件层虚拟化
硬件层虚拟化需要软件和硬件结合才能实现,其中需要硬件的支持的部分包括:• 支持CPU和内存的硬件虚拟化。相关技术包括:Intel VT-X、AMD AMD-V、ARM 8.3 VHE、RISC-V Hypervisor Extension等。• 支持IOMMU。DMA remapping和Interrupt remapping;硬件隔离和页表机制;相关技术包括:IntelVT-D,AMD IOMMU,ARM SMMU等。下面主要介绍全虚拟化/透传GPU技术及NVIDIA显卡相关的4项GPU虚拟化技术。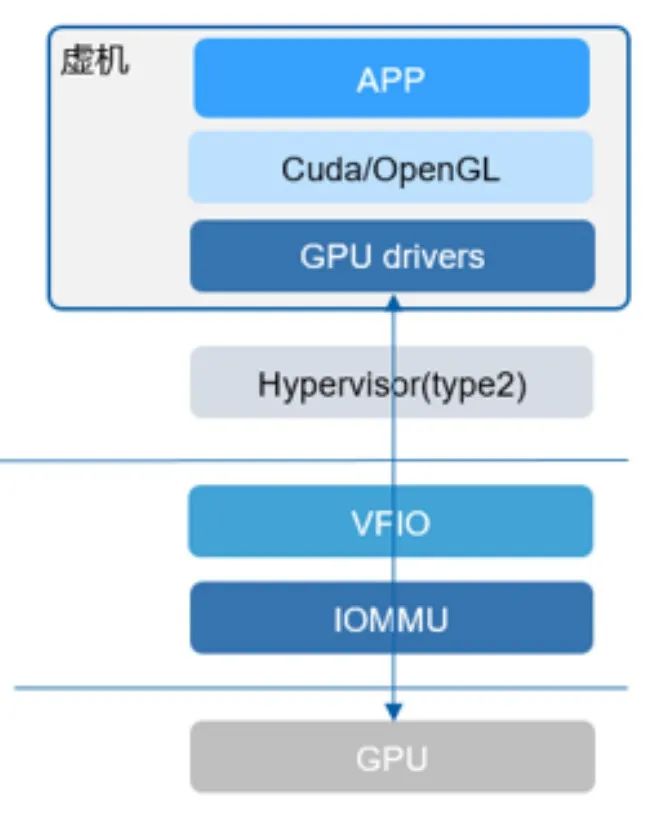
图8:透传GPU
全虚拟化,也称为透传GPU,是一种将GPU直接分配给虚拟机的方法,使虚拟机能够以最小的性能损耗访问真实的硬件资源。1. 虚拟机GPU驱动:虚机的GPU驱动无需做任何修改,能够直接访问真实的硬件资源。
2. GPU透传:整个GPU透传给虚拟机,确保性能损耗最小。
• 适用范围:适用于虚拟机应用和云GPU服务器。
• 资源共享限制:由于无法实现GPU资源共享,一般认为这不属于严格意义上的GPU虚拟化。
这项技术在需要高性能GPU访问的虚拟化环境中非常有效。

图9:NVIDIA vGPU方案
NVIDIA vGPU是 NVIDIA特有的虚拟化技术,旨在支持虚拟机环境中的GPU资源分配和管理。1. 特定驱动安装:虚拟机内核需要安装特定的GPU虚拟化驱动,即GRID驱动,与物理机安装的驱动不同。
2. 显存分配:显存按照固定切分,直接分配给虚拟机。
3. 算力调度:采用时分方案,按时间片将GPU算力分配给虚拟机。
• 适用范围:适合云GPU服务器。
• 收费模式:该软件需要付费使用。
NVIDIA vGPU提供了一种高效的方式来管理虚拟机中的GPU资源,适用于需要高性能图形和计算能力的场景。
NVIDIA多实例GPU(Multi-Instance GPU,简称 MIG)是 NVIDIA 在 H100,A100,A30 系列 GPU 卡上推出的一项新特性, 旨在将一块物理 GPU 分割为多个 GPU 实例,以提供更细粒度的资源共享和隔离。MIG 最多可将一块 GPU 划分成七个 GPU 实例, 使得一个 物理 GPU 卡可为多个用户提供单独的 GPU 资源,以实现最佳 GPU 利用率。这个功能使得多个应用程序或用户可以同时共享GPU资源,提高了计算资源的利用率,并增加了系统的可扩展性。通过 MIG,每个 GPU 实例的处理器在整个内存系统中具有独立且隔离的路径——芯片上的交叉开关端口、L2 高速缓存组、内存控制器和 DRAM 地址总线都唯一分配给单个实例。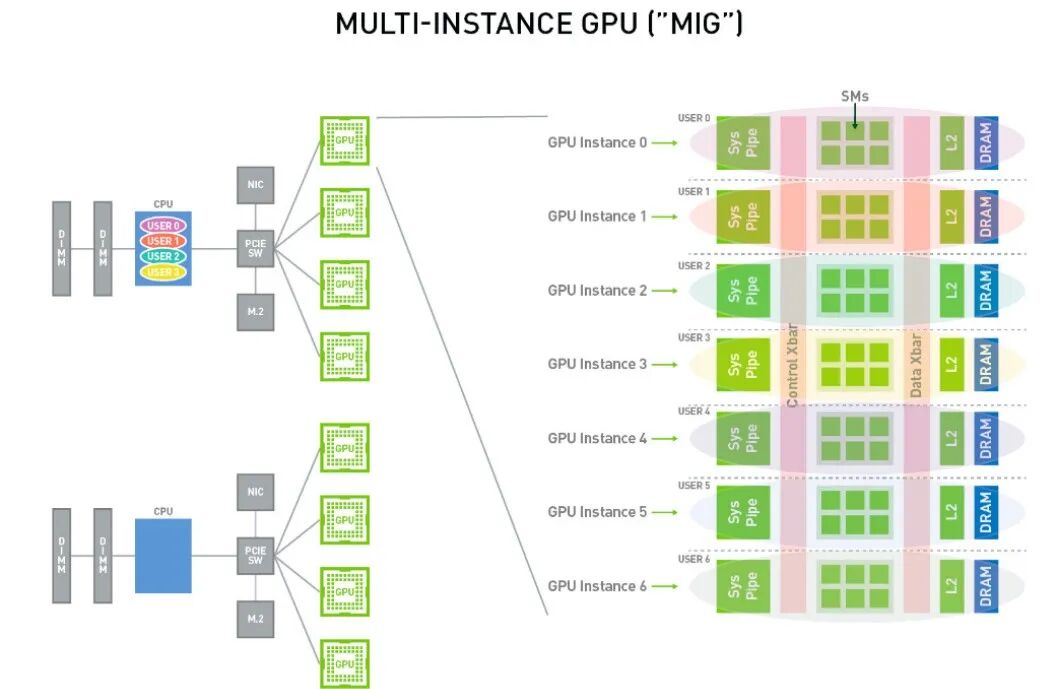
NVIDIA MIG方案适合容器化部署,云原生场景。
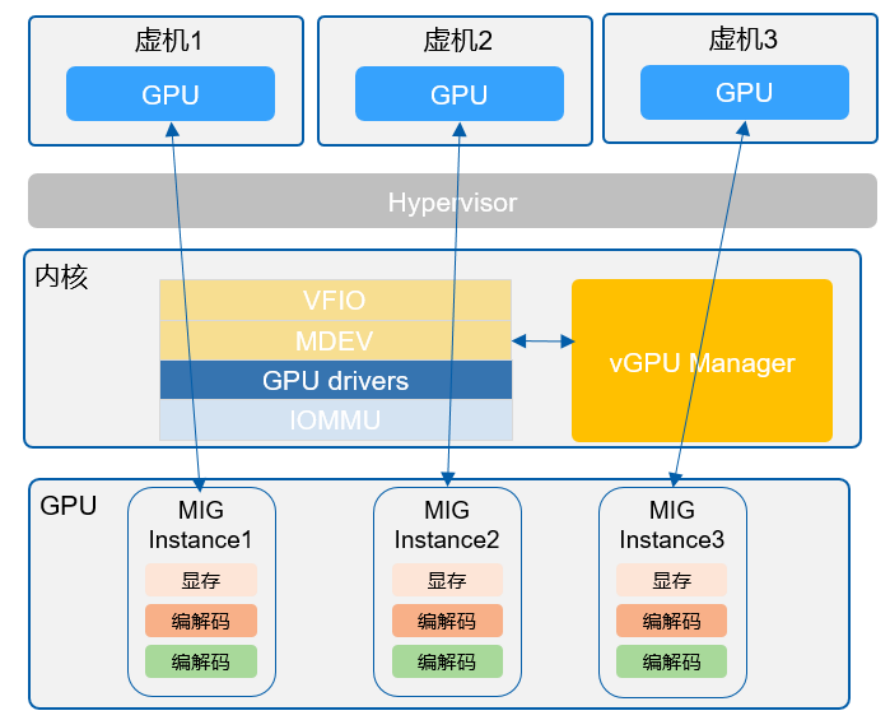
图11:NVIDIA MIG vGPU
NVIDIA MIG vGPU 是将多实例 GPU(MIG)和虚拟 GPU(vGPU)相结合的一种技术,旨在优化虚拟机中的 GPU 资源分配。1. 资源切分: 显存和算力按照 MIG 硬件的切分方式,直接分配给虚拟机。
2. 性能优势: 相较于传统的 vGPU,MIG vGPU 在算力损耗方面更小。
• 适用范围:适合虚拟机应用和云 GPU 服务器。
通过 MIG vGPU,用户可以更高效地利用 GPU 资源,提升虚拟化环境中的性能表现。
(四)GPU虚拟化技术对比
在用户层、内核层、硬件层的GPU虚拟化技术对比如下:表1:GPU虚拟化技术对比

(五)业界GPU虚拟化方案对比
表2:业界GPU虚拟化方案对比











