|
我们将在本文中介绍一种文本增强技术,该技术利用额外的问题生成来改进矢量数据库中的文档检索。通过生成和合并与每个文本片段相关的问题,增强系统标准检索过程,从而增加了找到相关文档的可能性,这些文档可以用作生成式问答的上下文。 ingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;border-left: 4px solid rgb(248, 57, 41);">实现步骤通过用相关问题丰富文本片段,我们的目标是显著提高识别文档中包含用户查询答案的最相关部分的准确性。具体的方案实现一般包含以下步骤:- 文档解析和文本分块:处理PDF文档并将其划分为可管理的文本片段。
- 问题增强:使用语言模型在文档和片段级别生成相关问题。
- 矢量存储创建:使用向量模型计算文档的嵌入,并创建FAISS矢量存储。
- 检索和答案生成:使用FAISS查找最相关的文档,并根据提供的上下文生成答案。
我们可以通过设置,指定在文档级或片段级进行问题增强。class QuestionGeneration(Enum):"""Enum class to specify the level of question generation for document processing.
Attributes:DOCUMENT_LEVEL (int): Represents question generation at the entire document level.FRAGMENT_LEVEL (int): Represents question generation at the individual text fragment level."""DOCUMENT_LEVEL = 1FRAGMENT_LEVEL = 2
ingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;border-left: 4px solid rgb(248, 57, 41);">方案实现
问题生成 def generate_questions(text: str) -> List[str]:"""Generates a list of questions based on the provided text using OpenAI.
Args:text (str): The context data from which questions are generated.
Returns:List[str]: A list of unique, filtered questions."""llm = ChatOpenAI(model="gpt-4o-mini", temperature=0)prompt = PromptTemplate(input_variables=["context", "num_questions"],template="Using the context data: {context}\n\nGenerate a list of at least {num_questions} " "possible questions that can be asked about this context. Ensure the questions are " "directly answerable within the context and do not include any answers or headers. " "Separate the questions with a new line character.")chain = prompt | llm.with_structured_output(QuestionList)input_data = {"context": text, "num_questions": QUESTIONS_PER_DOCUMENT}result = chain.invoke(input_data)# Extract the list of questions from the QuestionList objectquestions = result.question_listfiltered_questions = clean_and_filter_questions(questions)return list(set(filtered_questions))
处理主流程
def process_documents(content: str, embedding_model: OpenAIEmbeddings):"""Process the document content, split it into fragments, generate questions,create a FAISS vector store, and return a retriever.
Args:content (str): The content of the document to process.embedding_model (OpenAIEmbeddings): The embedding model to use for vectorization.
Returns:VectorStoreRetriever: A retriever for the most relevant FAISS document."""# Split the whole text content into text documentstext_documents = split_document(content, DOCUMENT_MAX_TOKENS, DOCUMENT_OVERLAP_TOKENS)print(f'Text content split into: {len(text_documents)} documents')
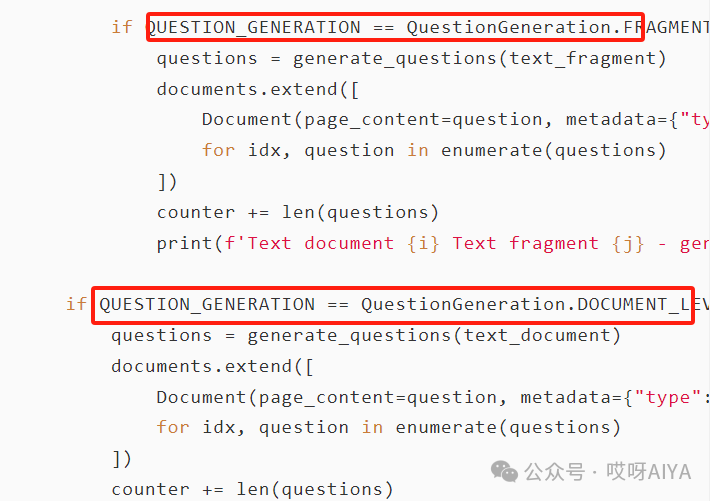
documents = []counter = 0for i, text_document in enumerate(text_documents):text_fragments = split_document(text_document, FRAGMENT_MAX_TOKENS, FRAGMENT_OVERLAP_TOKENS)print(f'Text document {i} - split into: {len(text_fragments)} fragments')for j, text_fragment in enumerate(text_fragments):documents.append(Document(page_content=text_fragment,metadata={"type": "ORIGINAL", "index": counter, "text": text_document}))counter += 1if QUESTION_GENERATION == QuestionGeneration.FRAGMENT_LEVEL:questions = generate_questions(text_fragment)documents.extend([Document(page_content=question, metadata={"type": "AUGMENTED", "index": counter + idx, "text": text_document})for idx, question in enumerate(questions)])counter += len(questions)print(f'Text document {i} Text fragment {j} - generated: {len(questions)} questions')if QUESTION_GENERATION == QuestionGeneration.DOCUMENT_LEVEL:questions = generate_questions(text_document)documents.extend([Document(page_content=question, metadata={"type": "AUGMENTED", "index": counter + idx, "text": text_document})for idx, question in enumerate(questions)])counter += len(questions)print(f'Text document {i} - generated: {len(questions)} questions')
for document in documents:print_document("Dataset", document)
print(f'Creating store, calculating embeddings for {len(documents)} FAISS documents')vectorstore = FAISS.from_documents(documents, embedding_model)
print("Creating retriever returning the most relevant FAISS document")return vectorstore.as_retriever(search_kwargs={"k": 1})
该技术为提高基于向量的文档检索系统的信息检索质量提供了一种方法。此实现使用了大模型的API,这可能会根据使用情况产生成本。 | 









