|
熟悉搜推的小伙伴可能知道,搜推中也有个叫Rerank的,因为在Rerank前面,一般还有粗排、精排,而RAG中就一个排序模型,怎么就是Rerank了呢。这是因为在RAG中,检索阶段一般只有Embedding一路召回,多的时候也只不过是稀疏+稠密的RRF集成,因此检索结果无论如何都是有顺序的,也就是说已经是排过序的了,所以此处的再次排序,叫Rerank。 既然都是排序,加Rerank的意义在哪?使用Embedding这种检索模型检索时,问题和答案都使用Embedding表示,由于问题和答案本身的表述方式、用词分布等差异比较大,直观的理解是问题首先是个问句,一般比较简短,答案通常是陈述句,一般比较详细,这俩用相同的方式表征,肯定多少是会有“对不齐”的问题的,Rerank就是把这两个放在一起,举个例子大家感受一下: 如果使用Embedding检索,就有可能把“介绍一下故宫?”检索回来了,因为这俩从Embedding的角度看实在太像了,但你如果把“介绍一下北京?<SEP>介绍一下故宫?”放一起,Rerank模型大概不会判断他们是应该在一起的,因此它的相似性得分会比较低,而“介绍一下北京?<SEP>北京市(Beijing),简称“京”,古称燕京、北平,是中华人民共和国首都、直辖市、国家中心城市、超大城市, 国务院批复确定的中国政治中心、文化中心、国际交往中心、科技创新中心,中国历史文化名城和古都之一,世界一线城市。截至2023年10月,北京市下辖16个区,总面积16410.54平方千米。2023年末,北京市常住人口2185.8万人。”类似这种表述,其实在训练集中有可能出现,因此Rerank的相似性得分会高。 下面借用一下来自Cohere官方博客的Rerank流程图: 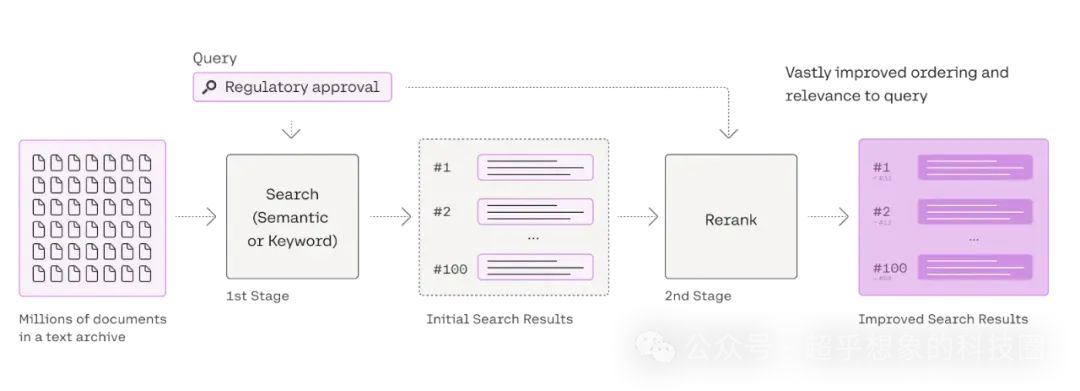
https://cohere.com/blog/rerank Rerank模型比较常见的架构是基于transformers的encoder-only,也就是BERT的衍生模型。BERT论文发布时,介绍了几个典型的NLP任务,其中一个是文本蕴含,它判断的是两个句子,他们之间是蕴含、矛盾、还是中立关系,Rerank模型与之类似,也是输入两个句子,中间用一个分隔符分割开,只不过输出的是这两个句子的相似度。 下表中的“检索优化(5)常用Reranker”,是在“检索优化(4)BM25和混合检索”基础上,增加Reranker的结果。 从下表可以看出,加入Reranker后,检索性能普遍是有提升的,全流程问答也普遍有大幅度提升,不过需要注意的是,在有些项目中,在检索后加未经微调的Reranker,性能反而可能会下降,这个需要大家在实际项目中尝试,下一篇文章会介绍如何对BGE Reranker进行微调。 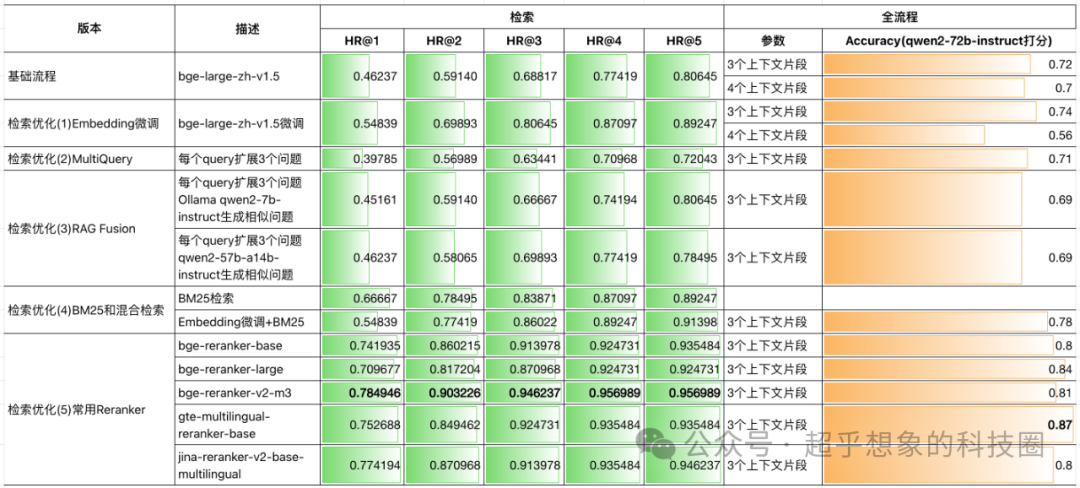
本文对应的完整代码已开源,地址在:https://github.com/Steven-Luo/MasteringRAG/blob/main/retrieval/05_reranker.ipynb 这部分,会首先介绍几种常用的Reranker API,最后会介绍如何与检索结果结合。 这应该是最有名的reranker了,cohere公司主打的就是Reranker模型。 首先访问https://dashboard.cohere.com/api-keys申请一个API Key,然后安装依赖: 注意:下面这两种方式,都需要有代理,否则来自国内的请求会被拒绝,使用时,环境变量设置http_proxy和https_proxy即可,免费用户每个月有1000次调用额度。在写这篇文章之前做实验时,它的检索效果可以与bge-reranker-large打平,但在后续再次运行时,由于超出调用额度,所以代码仓库中没有实际的运行结果,但代码是可以运行的,大家可以自行尝试。
co=cohere.Client()
docs=[
,
,
,
,
,
]
response=co.rerank(
model=,
query=,
documents=docs,
top_n=,
)
(response)
CohereRerank
os.environ[]=
cohere_rerank=CohereRerank(model=)
docs=[
,
,
,
,
,
]
query=
cohere_rerank.rerank(
documents=docs,
query=query,
top_n=
) 这个是智源(BAAI)开源的Reranker,也非常有名,在23年的时候,是为数不多可选的几个Reranker模型。这个模型的权重可以在HuggingFace上下载。常用的有如下三种: BAAI/bge-reranker-base BAAI/bge-reranker-large BAAI/bge-reranker-v2-m3
pipinstall-UFlagEmbedding FlagReranker
reranker=FlagReranker(,use_fp16=)
score=reranker.compute_score([,])
(score)
score=reranker.compute_score([,],normalize=)
(score) 这个是阿里巴巴开源的reranker,HuggingFace中的模型ID为Alibaba-NLP/gte-multilingual-reranker-base,官方示例:
AutoModelForSequenceClassification,AutoTokenizer
model_name_or_path=
tokenizer=AutoTokenizer.from_pretrained(model_name_or_path)
model=AutoModelForSequenceClassification.from_pretrained(
model_name_or_path,trust_remote_code=,
torch_dtype=torch.float16
)
model.eval()
pairs=[[],[,],[,]]
torch.no_grad():
inputs=tokenizer(pairs,padding=,truncation=,return_tensors=,max_length=)
scores=model(**inputs,return_dict=).logits.view(-,).float()
(scores) Jina也是一家很有实力的AI公司,之前在介绍使用Ollama和Langchain动手开发AI搜索问答助手中提到过他们出的Reader API,是需要非常简单的操作,就可以将网页解析成Markdown,大幅提高了后续问答的效果。 此处介绍的Reranker模型,是他们开源的多语言重排模型,HuggingFace中的模型ID为jinaai/jina-reranker-v2-base-multilingual。 AutoModelForSequenceClassification
model=AutoModelForSequenceClassification.from_pretrained(
,
torch_dtype=,
trust_remote_code=,
)
model.to()
model.eval()
query=
documents=[
,
,
,
,
,
,
,
,
,
,
]
sentence_pairs=[[query,doc]docdocuments]
scores=model.compute_score(sentence_pairs,max_length=) Chroma
HuggingFaceBgeEmbeddings
BM25Retriever,EnsembleRetriever
Chroma
device=torch.cuda.is_available()
embeddings=HuggingFaceBgeEmbeddings(
model_name=,
model_kwargs={:device},
encode_kwargs={:},
query_instruction=
)
vector_db=Chroma.from_documents(
splitted_docs,
embedding=embeddings,
persist_directory=persist_directory
)
chz_cut_bm25_retriever=BM25Retriever.from_documents(splitted_docs,preprocess_func=text jieba.cut(text)))
retriever=EnsembleRetriever(
retrievers=[vector_db.as_retriever(search_kwargs={:}),chz_cut_bm25_retriever],weights=[,]
) jieba.cut(text)))
retriever=EnsembleRetriever(
retrievers=[vector_db.as_retriever(search_kwargs={:}),chz_cut_bm25_retriever],weights=[,]
)Reranker准备,此处以BGE Reranker为例,其他几种方式请查看代码仓库: FlagReranker
AutoModelForSequenceClassification,AutoTokenizer
reranker=FlagReranker(,use_fp16=)
(reranker,query,retrieved_docs,top_k=,debug=):
rerank_scores=reranker.compute_score([[query,doc.page_content]docretrieved_docs])
triads=[(query,doc,score)doc,score(retrieved_docs,rerank_scores)]
triads=(triads,key=triad:triad[-],reverse=)
debug:
triads
[triad[]triadtriads][:top_k]
k=
retirever_multiplier=
chunks=retriever.get_relevant_documents(question)[:k*retirever_multiplier]
chunks=rerank(reranker,question,chunks,top_k=k)
|










