LlamaParse 简介LlamaParse[1] 是一个专为生成式人工智能(GenAI)设计的文档解析器,能够解析复杂的文档数据,以适应任何下游大型语言模型(LLM)的使用场景,如检索增强生成(RAG)或智能代理。 它能够解析多种复杂的文件类型,包括 PDF、PPTX、DOCX、XLSX 和 HTML,并且支持表格识别、多模态解析和自定义解析。 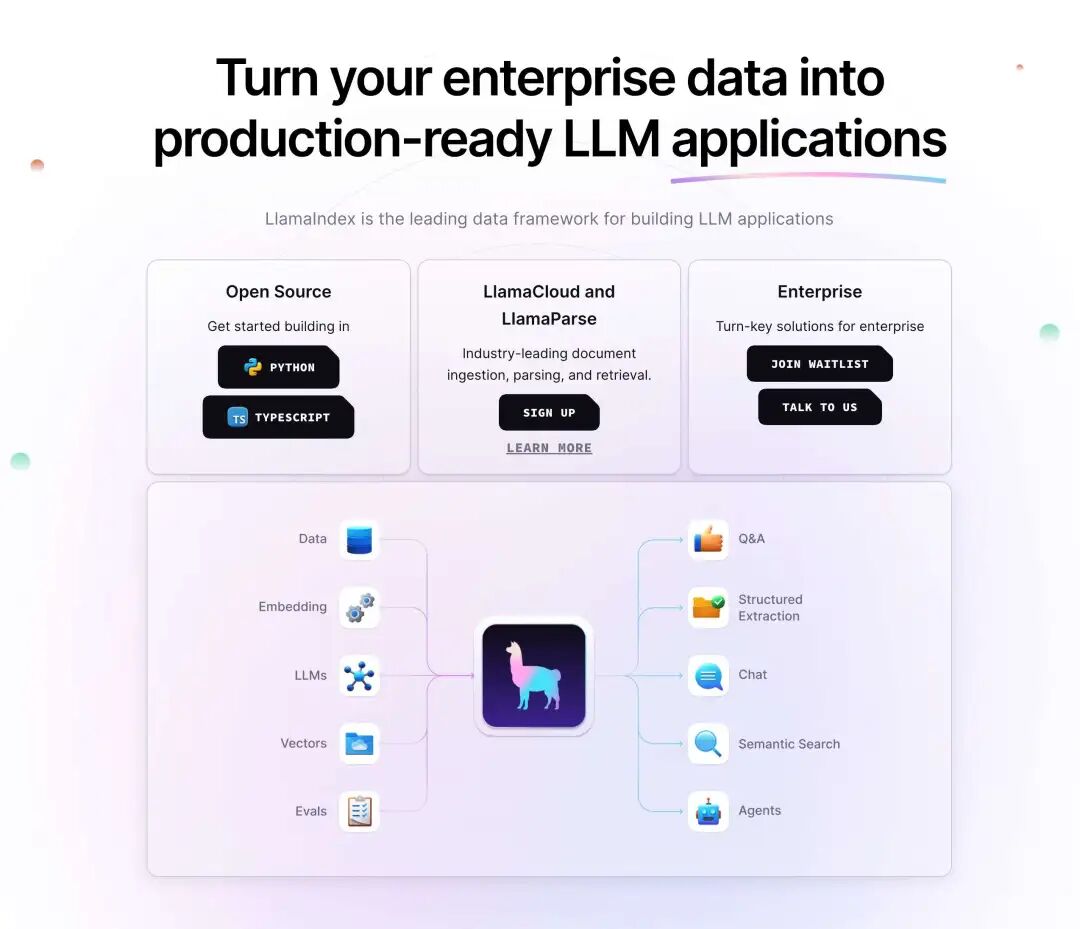 项目特点主要特点- 广泛的文件类型支持:支持解析多种非结构化文件类型,包括 PDF、PPTX、DOCX、XLSX、HTML 等,涵盖文本、表格、视觉元素、复杂布局等。
- 表格识别:能够将嵌入的表格准确解析为文本和半结构化表示。
- 多模态解析和分块:提取视觉元素(图像/图表)并将其转换为结构化格式,使用最新的多模态模型返回图像块。
- 自定义解析:输入自定义提示指令,以自定义输出方式。
使用场景- 企业文档管理:将企业文档转换为结构化数据,便于检索和分析。
- 数据整合:将不同来源的非结构化数据整合为统一格式,以供进一步处理。
- 自动化报告生成:从文档中提取关键信息,自动生成报告或摘要。
项目使用- 获取 API 密钥:访问 LlamaIndex Cloud[2] 获取 API 密钥。
- 安装 LlamaIndex:确保安装了最新版本的 LlamaIndex。
- 安装 LlamaParse:使用
pip install llama-parse 命令安装 LlamaParse 包。 - 解析文档:使用 LlamaParse 提供的接口,上传并解析文档。
示例代码importnest_asyncio
nest_asyncio.apply()
fromllama_parseimportLlamaParse
parser=LlamaParse(
api_key="llx-...",#也可以设置环境变量LLAMA_CLOUD_API_KEY
result_type="markdown",#可选"markdown"和"text"
num_workers=4,#如果上传多个文件,将分成`num_workers`个API调用
verbose=True,
language="en",#可选定义语言,默认为英文
)
#同步解析单个文件
documents=parser.load_data("./my_file.pdf")
#同步批量解析
documents=parser.load_data(["./my_file1.pdf","./my_file2.pdf"])
#异步解析单个文件
documents=awaitparser.aload_data("./my_file.pdf")
#异步批量解析
documents=awaitparser.aload_data(["./my_file1.pdf","./my_file2.pdf"])
参考文档
注:本文内容仅供参考,具体项目特性请参照官方 GitHub 页面的最新说明。
| 









