|

GOT-OCR2.0 是一个基于 QWen2 0.5B 模型的开源项目,项目核心是开发了一个统一的端到端模型,旨在推动 OCR 技术进入2.0时代。 获取 GOT-OCR2.0在线体验地址、模型下载地址,关注?公众号 ingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;font-size: var(--articleFontsize);letter-spacing: 0.034em;">极客开源 在后台回复OCR2.0关键词。
这个只有 580M 参数的 OCR 模型,拿到了 BLEU 0.972 分数,而且模型大小只有 1G 多,在一般配置的本地机器上运行也不是问题。 从测试效果来看性能也很不错,支持识别普通文档、场景文档、格式化文档等多种多样的文本内容。 
普通文本的训练数据中主要使用中文CASIA-HWDB2 和英文IAM 数据集,所以该模型对中英文内容的识别效果会比较好。 
格式化文档的训练数包括了:数学公式、化学分子式、表格数据、PDF 整页数据,以及更有难度的乐谱、几何形状、图表,得益于多模型大模型的加持,GOT 模型可以处理更多种类的任务。模型架构层面,GOT 由三个模块组成,图像编码器、线性层和输出解码器。线性层充当连接器,在视觉编码器和语言解码器之间映射通道维度。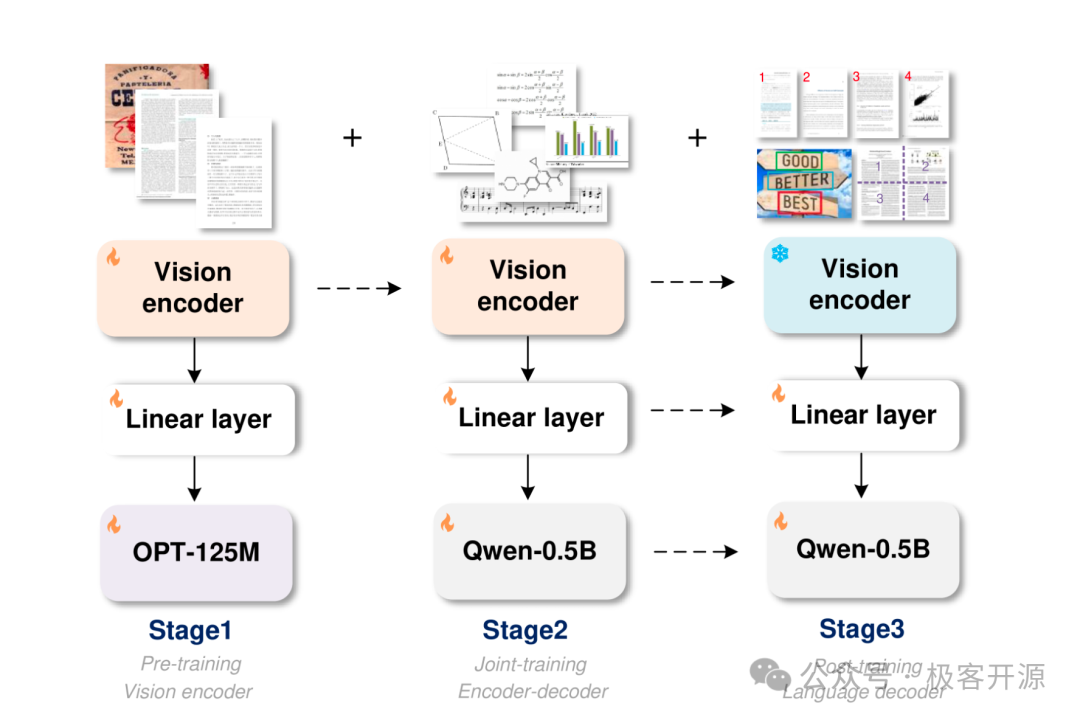
首先,执行纯文本识别任务,对视觉编码器进行预训练。为了提高训练效率并节省 GPU 资源,GOT 选择了一个微型解码器将梯度传递给编码器。在这个阶段,把包含场景文本的图像和包含文档级字符的手动图像馈送到模型中,以允许编码器收集两种最常用的字符的编码能力。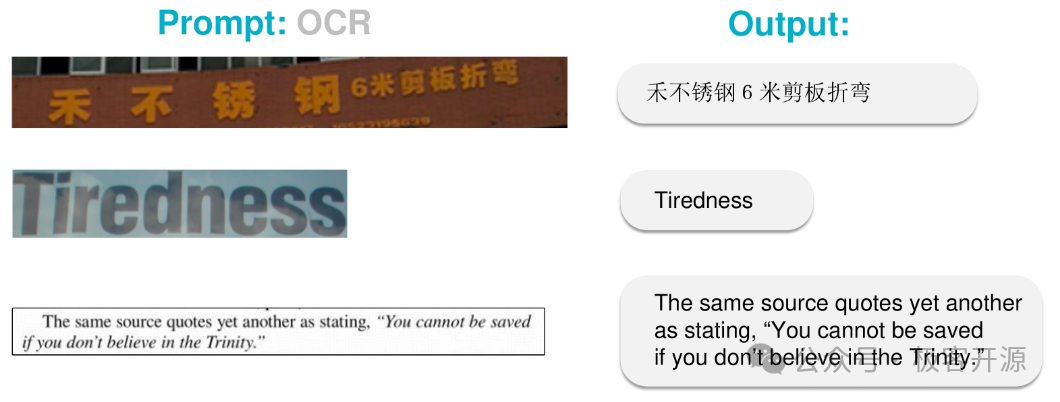
在下一阶段,通过将经过训练的视觉编码器连接到一个新的更大的解码器来形成 GOT 的架构。
在最后阶段将会进一步提高 GOT 的泛化和适用性。具体来说,为 GOT 生成和添加细粒度和多裁剪/页面合成数据,以支持区域提示 OCR、大图像 OCR 和批量 PDF OCR 功能。
OCR-2.0 模型在结构上比 OCR-1.0 的系统要简单,比多模型大语言模型更侧重于纯 OCR 任务,并且具有卓越的性能;并且 OCR-2.0 将各种 Pan-OCR 任务集成到一个模型中,在模型设计、数据工程和应用场景方面具有有价值的研究方向。获取更多生成式 AI 大模型相关开源项目可以关注?公众号 极客开源,获取上文提到的 OCR 在线体验地址、开源仓库和模型下载地址,在后台回复OCR2.0 关键词。 | 









