|
笔者在往期文章中分享了很多文档智能解析相关技术,传统的pipline的解析技术基本上如下图: 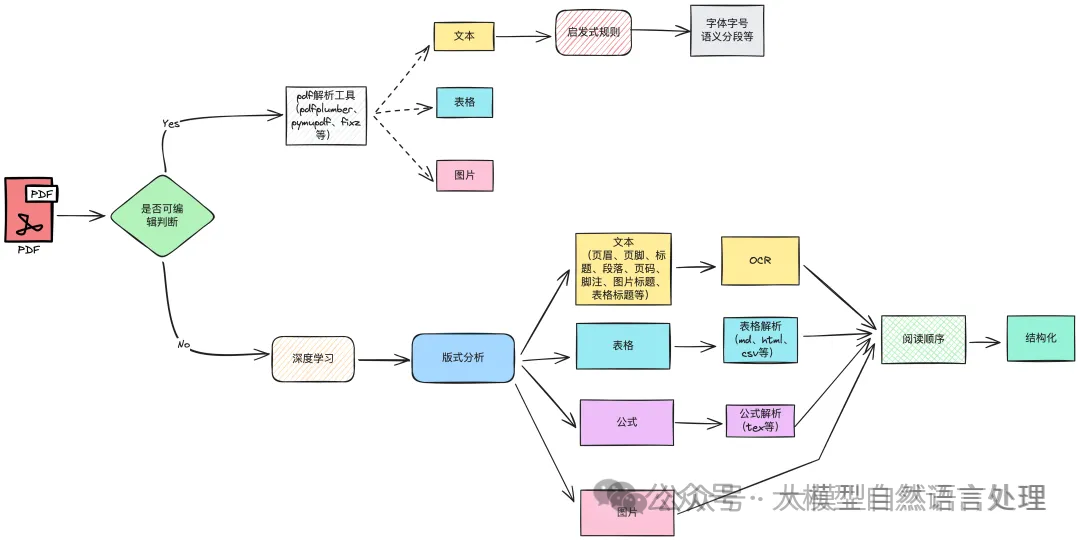 下面再来通过一篇综述文章回顾下相关技术,文章介绍了传统pipline的文档解析技术、端到端的多模态文档解析技术和相关数据集。  技术方法 基于版式分析的pipline解析技术布局分析  布局检测识别文档的结构元素,如文本块、段落、标题、图像、表格和数学表达式,以及它们的空间坐标和阅读顺序。其中,数学表达式的检测,特别是内联数学表达式,通常单独设置一个检测模型进行处理。 相关数据集: 
文本提取:这一过程利用光学字符识别(OCR)技术进行提取。  相关数据集:  数学表达式提取:检测文档区域内的数学符号和结构,并将其转换为标准格式,如LaTeX或MathML。  相关数据集: 表格数据与结构提取:表格识别涉及通过识别单元格的布局以及文档图像中行与列之间的关系来检测和解释表格结构。提取的表格数据通常与OCR结果结合,并转换为LaTeX等格式以供进一步使用。  相关数据集: 图表识别:此步骤专注于识别不同类型的图表,并提取底层数据及其结构关系。图表中的视觉信息被转换为原始数据表格或结构化格式,如JSON。  相关数据集: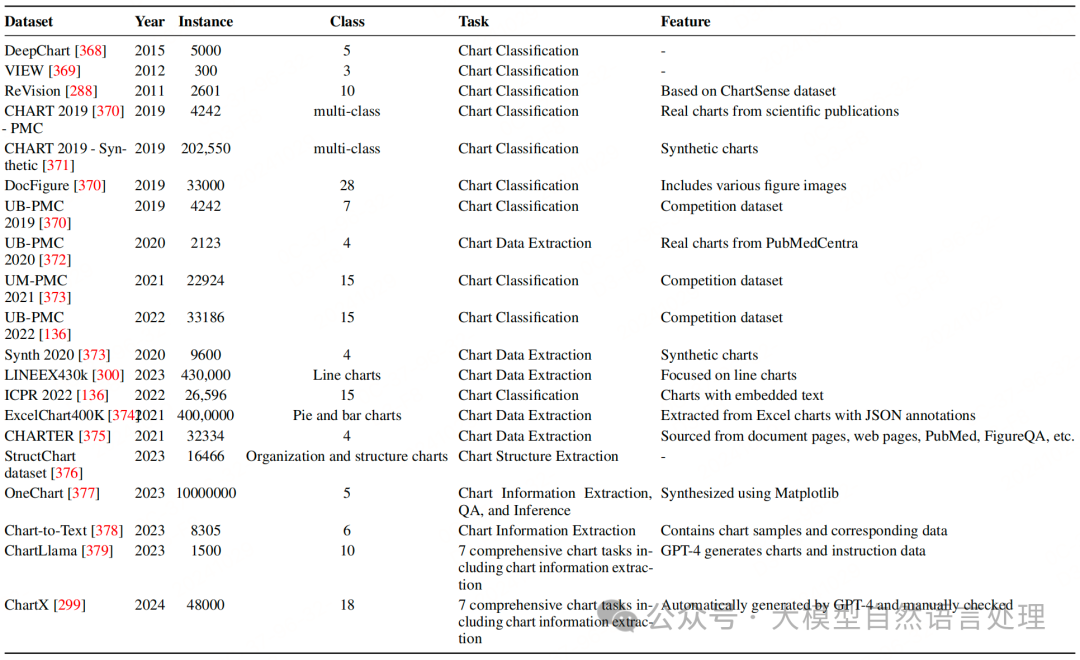
这一步基于前面两步骤的结果(坐标,bbox)等,通常是基于规则的系统或专门的阅读顺序模型《【文档智能】符合人类阅读顺序的文档模型-LayoutReader及非官方权重开源》通常被用来维持内容的逻辑关系。  笔者在半年前开源了一个阅读顺序模型(供参考): modelscrope地址:https://modelscope.cn/models/yujunhuinlp/LayoutReader-only-layout-large 端到端的多模态文档解析技术传统的模块化文档解析系统在特定领域内表现出色,但其架构通常导致联合优化不足,限制了在不同文档类型间的泛化能力。近年来,视觉语言模型(VLMs)的进步为这一领域提供了有前景的替代方案。这些模型,如GPT-4、Qwen、LLaMA和InternVL,能够同时处理视觉和文本数据,促进文档图像到结构化输出的端到端转换。 针对文档图像中的特定挑战——如密集文本、复杂布局以及视觉元素的高度变异性,出现了一些专门设计的大型模型,如Nougat、Fox和GOT。这些模型在处理复杂文档结构时,表现出更强的适应性和准确性。 总结文档智能解析目前落地的方案还是基于pipline的形式,端到端的方案目前受限资源速度等因素落地还有些距离。
| 









