|
在RAG应用中,一个稍微有点规模的知识库可能包含来自PDF、Word、PPT、网页等各种不同来源的内容,每种内容都有各自的解析器,但想把每种类型的解析都做到比较好是比较繁琐的,直观的例子比如Word中,可能存在页眉、页脚,页面版式可能是左右两栏,PDF中有可能会包含水印等干扰内容,网页就更明显了,这些如果处理不好,都会不同程度地影响后续流程,对每种文档类型分别解析并进行处理的模型,流程如下: 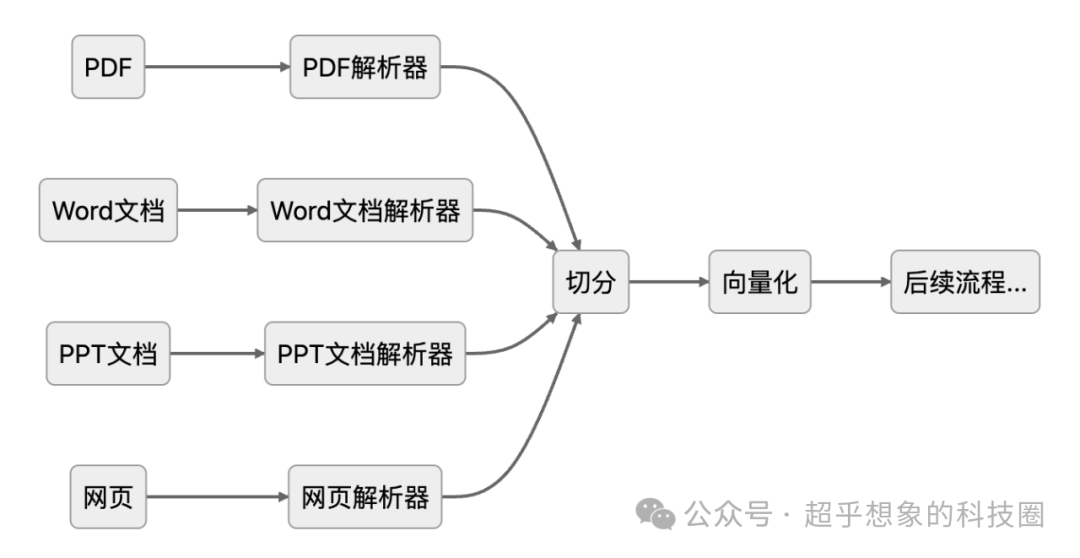
为什么需要这么多的解析器呢?直接把各种文件读取成字节流丢给大语言模型(以下简称LLM)不行吗,以当前的技术发展来说还不行,目前的LLM,无论是什么内容,都得组织成文本,它才能处理,(顺便提一句,现在的多模态大模型,也不能直接处理PDF、Word这种文件),而PDF、Word、网页等其实都是富文本,里面除了文字,通常还包含公式、图片、表格、统计图,排版方式也各不相同,甚至其中的格式也是很重要的内容(标题一般会比正文重要性高),而解析的作用,其实是把各种富文本,转换成纯文本的过程。 Markdown因为其简单明了的语法等特性,得到了广泛的应用,它可以通过纯文本来表达标题、列表、代码块、引用、表格、图片、公式、链接等,因为它本身是纯文本,大语言模型是可以直接处理的。如果大家用过扣子的提示词自动优化就会发现,优化后的提示词,变成了Markdown格式的,而且不少AI助手,它的输出其实也是Markdown格式的。其实使用YAML、JSON、XML来表达也是可以的,但因为使用这些标记语言设计的初衷是为了解决文件传输、保存配置信息等,LLM在训练的时候也没见过多少使用这些格式来表达图文、表格内容的,所以它也不擅长,只能通过Schema的方式来告诉LLM,而这样又会增加许多额外工作,没必要。所以,对于文档格式丰富的知识库,还有一种借助Markdown中转的处理模式,流程如下: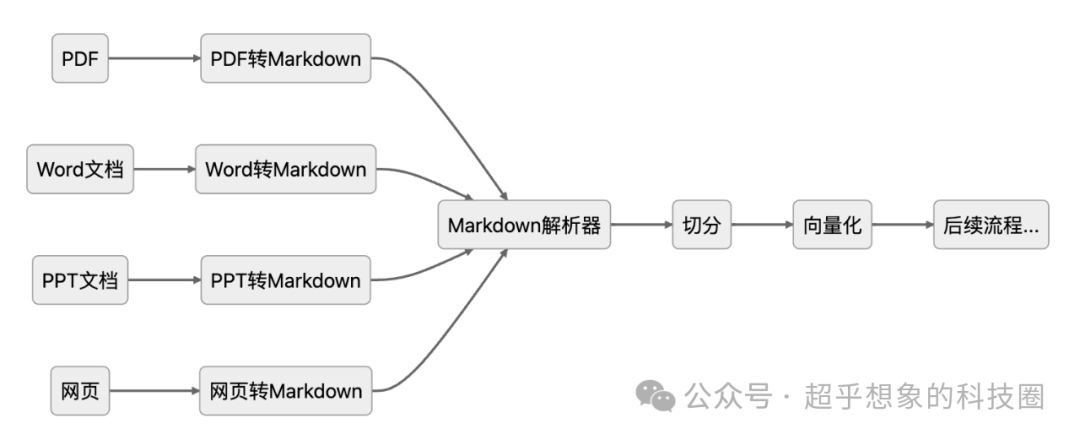 乍一看还比上面的流程复杂了,但其实不然,原因有以下两点: 下面就来介绍一下可借鉴的成熟的工作——MinerU,这个是上海人工智能实验室开源的项目,项目地址如下: https://github.com/opendatalab/MinerU condacreate-nMinerU=.10
condaactivateMinerU
pipinstall-Umagic-pdf[full]--extra-index-urlhttps://wheels.myhloli.com pipinstallhuggingface_hub
wgethttps://github.com/opendatalab/MinerU/raw/master/scripts/download_models_hf.py-Odownload_models_hf.py
pythondownload_models_hf.py 配置文件,对于Windows系统,在C:\Users\username\magic-pdf.json下,Linux系统在/home/username/magic-pdf.json下,macOS系统在/Users/username/magic-pdf.json下,把username换成自己的,如果有GPU,可以将device-mode改为cuda,官方建议需要至少8G显存,本人实测下面的文档处理时,显存消耗不超过6G。 下面的的样例代码,假设处理data目录下的2024全球经济金融展望报告.pdf文件
logger
UNIPipe
DiskReaderWriter
pdf_name=
pdf_path=os.path.join(,)
output_dir=os.path.join(,pdf_name)
os.path.exists(output_dir):
os.makedirs(output_dir,exist_ok=)
local_image_dir=os.path.join(output_dir,)
output_filename=os.path.join(output_dir,pdf_name)
os.path.exists(output_filename+):
logger.info()
:
pdf_bytes=(pdf_path,).read()
jso_useful_key={:,:[]}
image_dir=(os.path.basename(local_image_dir))
image_writer=DiskReaderWriter(local_image_dir)
pipe=UNIPipe(pdf_bytes,jso_useful_key,image_writer)
pipe.pipe_classify()
pipe.pipe_analyze()
pipe.pipe_parse()
md_content=pipe.pipe_mk_markdown(image_dir,drop_mode=)
(,,encoding=)f:
f.write(md_content)
e:
logger.error(e)处理后,会在data目录下的2024全球经济金融展望报告目录下,有一个2024全球经济金融展望报告.md的文件,处理结果如下: 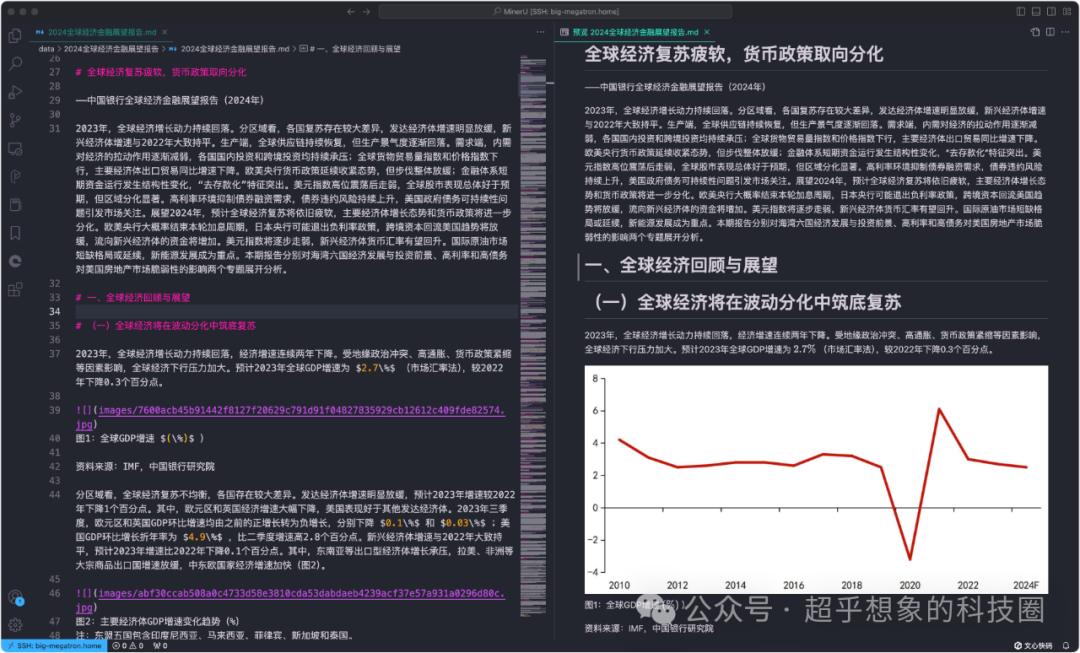
原始文档如下: 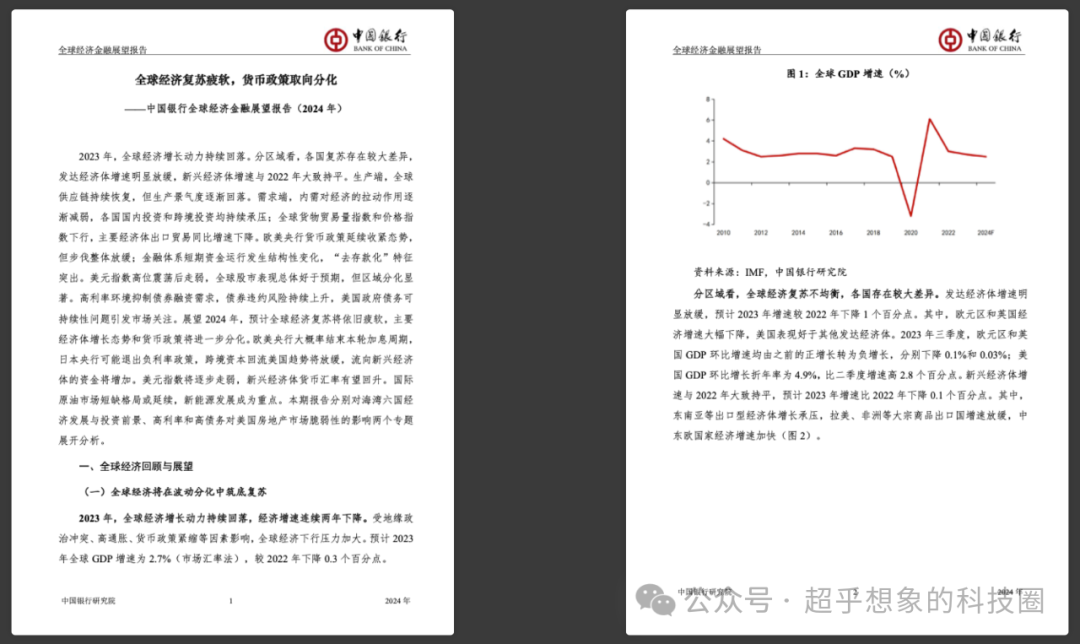
可以看到,页眉页脚统一都去掉了,图片也都正确提取出来了。 处理时间使用NVIDIA GTX 1080Ti处理时间1分43秒,使用Intel i7 9700K大约花费14分钟,供大家参考。
| 









