|
当产品经理突然要求"图片转结构化数据",这个春节我经历了从百度飞桨到阿里OCR,最终被国产黑马DeepSeek惊艳的技术选型之旅...
一、需求暴击:3套方案生死时速年前接到的需求看似简单——将用户上传的图片转成结构化JSON数据。但当我们从CPU解析8秒/张的百度飞桨方案,转向需要精准结构化时,技术方案经历了三次迭代: 1️⃣理想派方案:直接调用视觉大模型
(ChatGPT/通义/百炼)
❌ 致命伤:API调用时格式混乱,百炼模型存在固定提示词限制 2️⃣保守派方案:阿里OCR+大模型双剑合璧
✅ 速度:OCR 2秒+模型11秒
? 成本:单次0.084元
⚠️ 痛点:Qwen-Turbo理解力跳水,提示词需精密调校,在控制台怎么调试都没问题,一旦到了api调用,就各种问题。 3️⃣创新方案:百炼OCR+Qwen-Turbo组合拳
? 突破:成本直降10倍至0.01元/次
二、DeepSeek惊艳四座的三板斧当我在验证技术demo的时候,DeepSeek这个国产模型用三大绝技征服了我: - 闪电响应:API速度碾压Qwen-Turbo 30%,平均耗时只有几秒
- 提示词炼金术:模糊指令或仅需1/3指令即可精准输出
比如当我想计算调用成本时... 看下DeepSeek是怎么回答的。 DeepSeek不仅给出详细公式,还主动提示「阶梯计价策略」和「流量预估方法」——这是其他模型从未展现的预见性! 然后我又开始用DeepSeek做程序设计,通过深度思考会深入推导我的需求以及实现,非常的强大 ”
然后我就向大家安利DeepSeek
三、蝴蝶效应随着DeepSeek春节爆火,AI江湖风云突变: - DeepSeek响应时间从10s→30s,体验感急剧下降
本地化:当我试图部署67B大模型时...
(看着自己显卡流下了贫穷的泪水) 只能下载了一个8b和一个14b,其他的模型都卸载了,就保留了一个llama的视觉模型。需要注意的是8b是使用llma蒸馏出来的,14b是qwen蒸馏出来的。
四、开发者启示录- 成本敏感型:百炼OCR+Qwen-Turbo仍是性价比首选
- 精度优先型:DeepSeek 由于爆火导致响应延迟,建议使用百炼上部署的DeepSeek.
五、福利阿里百炼上线了DeepSeek,免费送1000万token,一次图片解析+格式化整理,大概需要3~4千token,有需要的可以关注下。可以用这个免费模型搭建自己的智能体玩玩。 https://dashi.aliyun.com/activity/aigc?userCode=v8bqy354 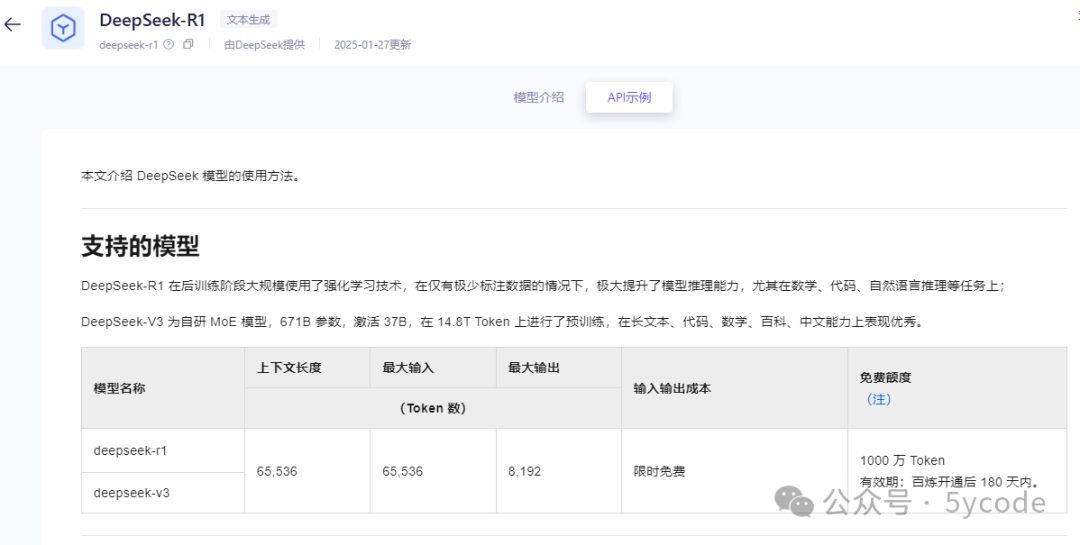
| 









