在人工智能迅猛发展的时代,每一次技术突破都如同在行业湖面投下巨石,激起千层浪。2025 年 1 月 20 日,DeepSeek-R1 震撼发布,迅速点燃 AI 社区的热情,成为万众瞩目的焦点。DeepSeek-R1 的卓越表现引发广泛热议,相信大家对它充满好奇。那么,这些模型背后有着怎样的诞生逻辑?它们是如何训练而成?不同模型之间又存在哪些区别,各自适用于何种场景?今天,我们将用最简洁易懂的语言,带你快速洞悉 DeepSeek-R1 的强大之处。| 四、在 ZStack AIOS 平台部署 DeepSeek-R1-Distill-Qwen-7B五、模型能力评测:DeepSeek-R1-Distill-Qwen-7B 七、展望:更大参数模型的部署策略 |
(1)什么是推理模型(Reasoning model)
(2)DeepSeek-V3、R1、蒸馏和量化模型的关系
最近,Deepseek 因为 R1 受到了全球瞩目,我们按时间线快速回顾 Deepseek 模型的发展历程:
2024 年 1 月发布 Deepseek-V1(67B),这是 Deepseek 第一个公开的开源模型。
2024 年 6 月发布 Deepseek-V2(236B)。新增了两个新颖的技术特色:多头注意力、MOE 专家混合,显著提升推理速度和性能,为 V3 奠定了基础。
2024 年 12 月发布 Deepseek-V3(671B),其参数量更为庞大,且能更好地在多 GPU 间平衡负载。
2025 年 1 月发布了 R1 系列模型:
Deepseek-R1-zero( 671B),这是一个推理模型(Reasoning Model),使用强化学习(Reinforcement Learning,简称“RL”)训练模型,使其能围绕目标自行探索。
Deepseek-R1( 671B),结合了强化学习和监督微调,推理效果极大提升,表现接近全球领先闭源模型 OpenAI 的 O1,而其运行成本相比O1降低了惊人的96%。
Deepseek-R1-Distill-Qwen/llama 系列,训练参数量有多种,是 Qwen2.5 和 Llama3 模型经过 R1 “调教” 后生成的推理模型,满足了更多企业轻量化需求。
2025 年 2 月,另一个模型研究团队 Unsloth 发布了基于 R1 的量化模型系列:
从 Deepseek 模型的发展可以看出,R1 并非由某一种或两种训练方法堆积而成,而是从 V1 开始,经由多个版本的模型互相构建、融合多种训练方法、逐步进化而来的推理模型。更值得称赞的是,DeepSeek-R1 秉持着开源精神,免费开放给全球开发者使用,让更多的研究人员、企业可以更低门槛使用先进的模型,推动了全球AI技术发展,被图灵奖得主、Facebook 首席人工智能科学家杨立昆称赞为 “开源战胜闭源”。
(3)什么是模型蒸馏
因为Deepseek-R1的参数量非常大,部署要求非常高,为了在小参数模型中引入长思维链推理能力,DeepSeek 团队引入了蒸馏技术。模型蒸馏就像是一场知识的传承,我们以 Deepseek-R1-Distill-Qwen2.5-7B 为例简单阐述蒸馏过程。
选择对象:首先选择一名优秀的学生Qwen,打算对它进行推理增强训练。强大的 R1会作为 “老师模型”,有着丰富的知识储备和卓越的推理能力。
准备工作:在蒸馏过程开启时,需准备大量训练数据,这些数据是模型学习的基础,随后将教师模型 R1 与学生模型 Qwen 同时置于训练环境中。
训练过程:教师模型 R1 对输入数据进行处理并生成输出,其输出包含了模型对数据特征的提取与理解。学生模型 Qwen 在学习原始数据的同时,会通过损失函数计算自身输出与教师模型输出的差异,就像学生模仿老师解题思路一样,不断调整自身参数以最小化这种差异。例如在分类任务中,教师模型输出各类别的概率分布,学生模型则努力模仿该分布,从而学习到教师模型的知识与推理模式。经过多轮迭代训练,学生模型 Qwen 的推理能力得到显著提升,最终生成有推理能力的 Qwen 模型。
模型蒸馏具有多方面优势。从成本与效率角度看,小型模型经蒸馏后可具备接近大型模型的性能,降低企业部署成本,提高推理速度,减少对大规模计算资源的依赖,但它的本质上仍然是 Qwen 或 Llama,因此需要对模型进行仔细的理解和评测,才能满足实际的业务需求。
在追求模型高效运行的道路上,还有一项关键技术同样致力于此,那就是“量化”。
二、量化技术概述:平衡性能与效率
根据前文我们已经知道真正的 DeepSeek-R1 为 671B 参数的版本(网上也被称为“满血版”),很多网上教程的版本教大家通过 ollama run deepseek-r1 下载的其实是一个经过蒸馏加微调训练出来的 Qwen2.5 7B, 所以这个模型的“智力”和我们在 DeepSeek 官网上对话的模型会相差甚大,再仔细观察会发现这个模型只有 4.7GB,也就是说这是一个经过较大力度量化的模型,这对模型的“智力”无疑会进一步雪上加霜。
(2)什么是量化?
量化是指将模型中的权重和激活值从高精度(如 FP32、BF16)转换为低精度(如 INT8 或 INT4 等)表示的方法。通过减少每个参数占用的位宽,可以显著降低模型的存储和计算需求。
量化模型可以大幅减少显存占用和计算量,使得在普通 GPU 甚至 CPU 上部署大型模型成为可能。然而,过度的量化可能导致模型精度的下降,特别是在处理需要精确计算和推理的任务时。
(3)为何推荐 BF16 和 INT8?
对于 Reasoning 模型,由于输出的 Token 序列较长,且对精度要求较高,通常推荐使用 FP16 或 INT8 量化方式。这些量化方法在显著降低计算资源需求的同时,能够较好地保持模型的性能。
(4)量化程度与精度损失的关系

需要注意的是,在新的量化工具(例如 Llama.cpp)中,对于量化做了非常精细的处理, 例如对部分层做不同精度(4 位、6 位、32 位)的量化,因此还会衍生出 Q4_K_M、Q6 等各种量化,但本质上依然是精度、速度、资源占用之间的平衡。
(5)在 DeepSeek 模型中的应用
由于 DeepSeek 原始模型尺寸巨大,即使在 Int4 下,显存需求依然非常高,MoE 架构、推理模型对量化也带来了许多新的挑战。为此,可以尝试使用 1.58、2.51 混合量化、动态量化等更高级的量化方法,具体效果以及上下文的量化我们会在后面的文章中进行阐述。
但在对模型进行量化后,我们有时会发现显存还是不够,或者模型跑起来之后输出内容会被截断,这就涉及到大模型的另一个重要参数——“上下文窗口”。
三、上下文窗口的重要性与显存估算
在上面的视频中,模型还没有思考完成,但是后续就不再继续输出了,这是因为模型回答已经达到了其“最长输出”的上限。对于 DeepSeek 的官方 API 来说,最大思维链长度为 32K,最大输出为 8K,就其原始模型来说,最大可以提供约 164K 的上下文,也就是大约能理解和输出总和差不多 10~16 万字。但在提供超长上下文的背后其实是大量的资源消耗,因此一些 API 可能不会开放最大的输出和上下文能力。对于以往的大部分非推理模型来说,可能 4K 的上下文足以满足单次对话的需求,但是对于推理模型来说,由于“思考”需要占用上下文,因此 4K 上下文可能连单次会话都不够用,对于用户使用产生明显的困扰。
(2)什么是模型的上下文窗口?
上下文窗口指模型在一次推理过程中能够处理的最大 Token 数量,平均一个 Token 能对应多少汉字对于不同的模型略有区别。上下文长度越长,模型能够记忆和理解的文本信息就越多,这对于长文本生成和复杂任务处理尤为重要,特别是较大规模的代码生成、专业内容的理解分析等。
上下文长度对模型效果的影响
(3)显存大小如何估算
模型的显存占用主要由以下部分组成:
2.KV Cache:与上下文长度、批次大小和注意力头数量有关,此外,和推理框架的内存使用方式也有关。
(4)DeepSeek 相关各类模型规模和量化方式下的显存需求概览
上述数据为估算值,且均使用 BF16 精度,如果使用支持 FP8 的 GPU 可能就不同,上下文占用采用 llama.cpp 来估算,vllm 等框架可能会占用更多,此外在并发请求时,需要给每一个会话额外准备 KV Cache
四、在 ZStack AIOS平台
部署 DeepSeek-R1-Distill-Qwen-7B
(1)硬件环境
GPU 类型:NVIDIA GPU,显存 24GB * 2,35.58 TFLOPS@BF16
CPU:采用 VM 部署,CPU 分配 8vCPU
内存:采用 VM 部署,内存分配 32GB RAM
操作系统:采用 ZStack AIOS 内置模板,Helix8.4r 系统
(2)部署步骤
1. 环境准备:安装 ZStack AIOS,确保系统满足运行要求使用 ZStack AIOS 选择模型并进行加载
指定运行该模型的GPU规格和计算规格后即可部署
在体验对话框中可以尝试对话体验或者通过 API 接入到其他应用
(3)性能指标

根据本次的测试数据,在16并发时,模型推理的吞吐量达到最大值,每个用户可以获得约 42 tokens/秒的速度,且首字符延迟在0.2秒以内。
五、模型能力评测:
DeepSeek-R1-Distill-Qwen-7B

(1)MMLU 得分对比
MMLU(Massive Multitask Language Understanding)是衡量模型多任务理解能力的权威基准。我们对比了蒸馏前后的 7B 模型在 MMLU 上的表现。

可以看到,蒸馏后的模型在 MMLU 上得分有下降,推理时间也有显著的延长。
(2)逻辑推理测试
我们选择了一些经典的逻辑推理题目,对模型进行测试。

数字谜题:蒸馏模型能够正确解答复杂的数字规律题,而原始模型表现较为逊色。
考虑以下数列:
2, 3, 5, 9, 17, 33, 65, ...
这个数列遵循一个特定的模式。请回答以下问题:
数列的下一个数是多少?比较大小:在涉及多重条件的大小比较问题上,蒸馏模型给出了正确的推理过程和答案。
在一个班级里,有四个学生:安娜、贝蒂、查理和大卫。已知以下信息:
安娜比贝蒂高。
查理不是最高的,也不是最矮的。
大卫比查理矮。
贝蒂不是最矮的。
请回答以下问题:
谁是最高的?
推理题目:蒸馏模型能够清晰地展示推理步骤,可以检查推理过程是否异常,结果上都符合预期。
前提:
1.有五栋五种颜色的房子
2.每一位房子的主人国籍都不同
3.这五个人每人只喝一种饮料,只抽一种牌子的香烟,只养一种宠物
4.没有人有相同的宠物,抽相同牌子的香烟,喝相同的饮料
提示:
1.英国人住在红房子里
2.瑞典人养了一条狗
3.丹麦人喝茶
4.绿房子在白房子左边5.绿房子主人喝咖啡
6.抽 PALL MALL 烟的人养了一只鸟
7.黄房子主人抽 DUNHILL 烟
8.住在中间那间房子的人喝牛奶
9.挪威人住第一间房子
10.抽混合烟的人住在养猫人的旁边
11.养马人住在抽 DUNHILL 烟的人旁边
12.抽 BLUE MASTER 烟的人喝啤酒
13.德国人抽 PRINCE 烟
14.挪威人住在蓝房子旁边
15.抽混合烟的人的邻居喝矿泉水
问题是:谁养鱼?
(3)代码与 SQL 生成

(4)RAG(Retrieval-Augmented Generation)场景测试
为了测试蒸馏模型和原模型相比在 RAG 知识库场景上是否会有提高,我们尝试了将 DeepSeek V3、DeepSeek R1 两篇技术报告(分别为22页 8802 词、53页 22330 词)导入到 AIOS 平台的 Dify 知识库中,之所以选这两篇文章是因为这两篇文章是没有被收入到模型的预训练参数中的,模型需要通过对文章进行理解来回答,无法凭借自身知识进行回答,此外为了模拟用户直接体验的效果,没有对 Dify 的默认 system prompt 进行优化,所有模型上下文设置为 8K,没有额外设置温度、Top K 等参数。每次用户问题提问数次,人工评价答案取平均值。

得益于 ZStack AIOS 智塔的专有环境和性能调优,文档的向量化、模型回答都会非常快。以下是知识库处理的效果:

和知识库对话的效果也很迅速:

此时的后台监控记录:

我们从不同维度测试了RAG场景下、7B模型蒸馏前后的回答表现:
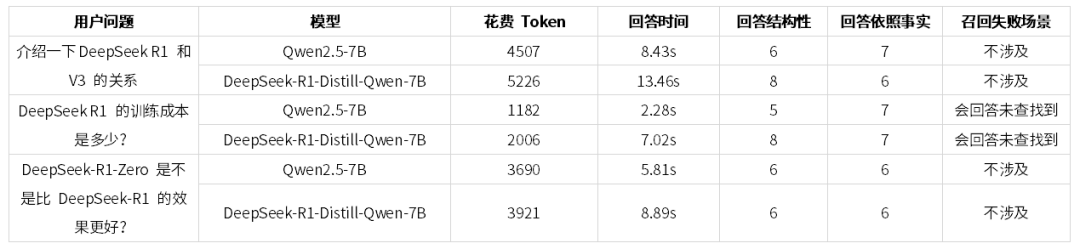
六、蒸馏版 7B 模型的适用场景与优势
资源受限环境:可在普通 GPU,甚至 CPU 上运行,部署成本低。
实时交互应用:推理速度快,响应时间短,适用于聊天机器人等场景。
需要一定推理能力的任务:相比原始模型,蒸馏模型在逻辑推理、代码生成等任务上有明显提升。
(2)优点
成本低:相对全参数版本,部署和运行成本降低。
速度快:推理速度较快,满足实时性要求。
部署灵活:支持量化版本,可在多种硬件平台上运行。
(3)限制
七. 展望:更大参数模型的部署策略
更大参数的蒸馏模型:如 DeepSeek-R1-Distill-Qwen-32B 的部署和应用效果。
DeepSeek 原始模型的量化部署:如何在有限资源下部署如 671B 规模的模型。
全精度部署策略:在高性能计算环境下,如何充分发挥大型模型的能力。
通过对比不同规模和精度的模型,我们希望为企业级应用提供更加全面和细致的部署方案,帮助更多行业快速落地大语言模型技术,实现商业价值。
结语
本文从 DeepSeek 模型的演进出发,探讨了蒸馏和量化在模型部署中的重要作用。通过具体的数据和测试结果,我们看到了蒸馏版 7B 模型在推理能力和部署成本之间取得的良好平衡。希望本篇文章能为您在大语言模型的企业级应用中提供有益的参考。










