|
谷歌Gemma 3全家桶来了! 刚刚,在巴黎开发者日上,开源Gemma系模型正式迭代到第三代,原生支持多模态,128k上下文。 此次,Gemma 3一共开源了四种参数,1B、4B、12B和27B。最最最关键的是,一块GPU/TPU就能跑模型。 在LMArena竞技场中,Gemma 3拿下了1339 ELO高分,仅以27B参数击败了o1-preview、o3-mini high、DeepSeek V3,堪称仅次于DeepSeek R1最优开源模型。 Gemma3系1B、4B、12B、27B分别基于2T、4T、12T、14T token数据完成训练。它们可以理解140+语言,支持视觉输入和文本输出,以及结构化输出和函数调用。在多项基准测试中,Gemma 3全家桶相较于上一代实现了全面提升,27B模型在数学性能暴涨33-45分。而且,与闭源Gemini 1.5和2.0相比,Gemma 3-27B基本上略逊色于Flash版本。
论文地址:https://storage.googleapis.com/deepmind-media/gemma/Gemma3Report.pdf 项目地址:https://huggingface.co/collections/google/gemma-3-release-67c6c6f89c4f76621268bb6dGemma系模型诞生一年以来,下载量已超1亿次,超6万个Gemma衍生模型爆发。Gemma 3全新系列到来,成为谷歌在AI开源社区迈出的又一个里程碑。Gemma 3是谷歌迄今最先进、最便携的开源模型,采用与Gemini 2.0模型相同的研究和技术打造。专为在端侧设备上直接运行而设计——从手机和笔记本电脑到工作站,帮助开发者在需要的地方创建AI应用。使用世界最佳单设备加速模型进行开发:Gemma 3在LMArena排行榜的初步人类偏好评估中超越了Llama-405B、DeepSeek-V3和o3-mini,能在单个GPU或TPU主机上运行,开发独特的用户体验。 支持140种语言,走向全球:Gemma 3为超过35种语言提供开箱即用的支持,并为超过140种语言提供预训练支持。 创建具有高级文本和视觉推理能力的AI:轻松开发可以分析图像、文本和短视频的应用程序,为交互式和智能应用开创新的可能性。 通过扩展的上下文窗口处理复杂任务:Gemma 3提供128k token的上下文窗口,让应用程序能够处理和理解海量信息。 使用函数调用创建AI驱动的工作流:Gemma 3支持函数调用和结构化输出,帮助你实现任务自动化并构建智能体验。 使用量化模型更快实现高性能:Gemma 3推出官方量化版本,在保持高精度的同时减少模型大小和计算需求。
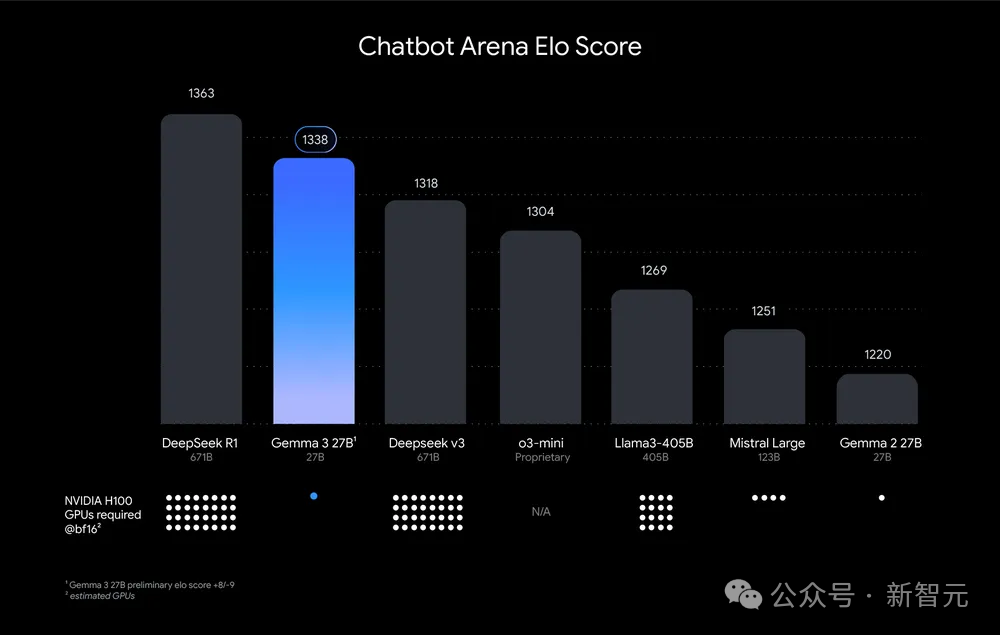
按照Chatbot Arena Elo评分对AI模型进行排名;更高的分数(顶部数字)表示更受用户青睐。点状标记显示了估计所需的H100数量。Gemma 3 27B 获得了很高的排名,注意,其他模型需要多达32个GPU,但它只需要1个如何训出?在预训练和后训练过程中,Gemma 3使用了蒸馏技术,并通过强化学习和模型合并的组合,进行了优化。而且,Gemma 3使用了一个全新的分词器(tokenizer),为140多种语言提供支持,并使用JAX框架在Google TPU对1B的2T token,4B的4T token,12B的12Ttoken和27B的14Ttoken进行了训练。- 从更大的指令模型中提取到Gemma 3预训练检查点
- 基于人类反馈的强化学习(RLHF),使模型预测与人类偏好保持一致。
强化学习执行反馈(RLEF),提高编码能力。
这些更新显著提升了模型数学、编程、指令跟随能力,使Gemma 3能在LMArena拿下1338得分。Gemma 3指令微调版本使用了与Gemma 2相同对话框格式,因此,开发者不需要更新工具,直接可以进行纯文本输入。对于图像输入,Gemma 3可以支持指定与文本交错的图像。多模态Gemma 3集成基于SigLIP集成视觉编码器,在训练过程中,视觉模型保持冻结状态,并在不同规模(4B、12B 和 27B)之间保持一致。借助这一特性,Gemma 3能够处理图像和视频作为输入,使其能够分析图像、回答与图像相关的问题、对比图像、识别物体,甚至读取和解析图像中的文本。尽管该模型最初设计用于处理896×896像素的图像,但通过一种新的自适应窗口算法,该模型可以对输入图像进行分割,使Gemma 3能够处理高分辨率和非正方形图像。比如,上传一张日语空调遥控器图,问如何调高室内温度。Gemma 3根据图像中「暖房」文字,分析出在日语中,「暖房」意为「加热」,这是用于开启空调或气候控制系统的加热功能的按钮。而带有加号(+)的按钮可能用于在选择加热模式后调整温度。下图上传超市购物清单后,Gemma 3准确回答了一片肉需要支付的金额。LLM竞技场LMSYS聊天机器人竞技场是让真人评委一对一匿名地对比IT 27B模型和其他顶尖模型。Gemma 3 27B IT拿到了1338分,挤进了前十名,分数比其他不会「思考」的开源模型要高,比如 DeepSeek-V3(1318 分)、LLaMA 3 405B(1257 分)和Qwen2.5-70B(1257 分),这些模型的规模还比它大不少。最后,Gemma 3的Elo分数比Gemma 2(1220分)高出一大截。需要注意的是,Elo分数不考虑视觉能力,而且上面提到的这些模型都没有这方面的功能。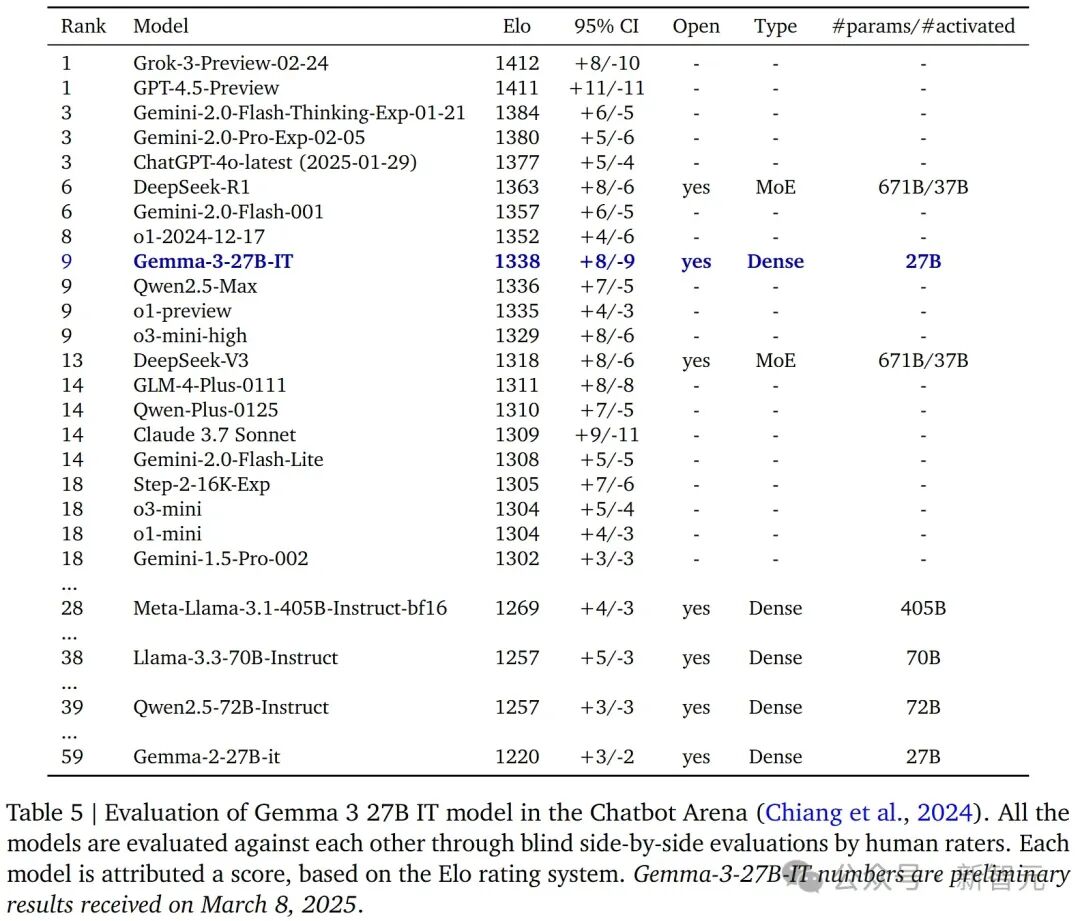
基于Elo评级系统在Chatbot Arena中对Grok-3-Preview-02-24、Gemini系列、Gemma系列等AI模型的排名和性能,其中Grok-3-Preview-02-24以1412分位居榜首,Gemma-3-27B-IT的排名为第9标准基准测试在下表6里,展示了最终模型在各种基准测试上的表现,这里只对比了之前的模型版本和Gemini 1.5。他们没有直接拿外部模型来比,因为各家报的分数是用他们各家自己的测试条件跑出来的,再跑一遍不一定公平。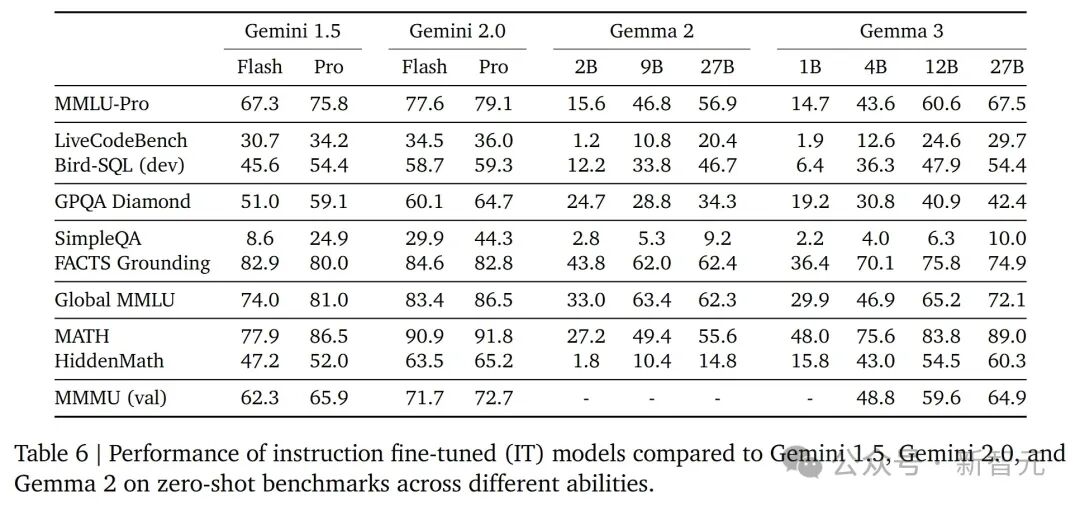
Gemini 1.5、Gemini 2.0以及Gemma 2和Gemma 3不同参数版本在各种零样本基准测试中的性能表现,包括MMLU-Pro、LiveCodeBench、Bird-SQL (dev)、MATH和HiddenMath等任务预训练能力探测团队在预训练过程中使用了几个标准的基准测试作为「探针」,来确保模型能够掌握一般的技能。在下图2中,他们比较了Gemma 2和Gemma 3预训练模型在这些通用能力上的表现,包括科学、代码、事实性、多语言能力、推理和视觉能力。总的来说,尽管增加了视觉能力,新的版本在大多数类别上都有了提升。研究团队特别关注了多语言能力,这直接影响了模型的质量。然而,尽管使用了去污染技术,但这些「探针」始终存在污染风险,这使得更明确的结论变得难以评估。无缝集成,工具生态全面升级Gemma 3带来的不仅仅是模型本身性能提升,还伴随着强大工具无缝集成,ShieldGemma 2可以完美集成到现有的工作流程中。比如Hugging Face Transformers、Ollama、JAX、Keras、PyTorch、Google AI Edge、UnSloth、vLLM和Gemma.cpp。
开发者们可以在Google AI Studio中,立即体验Gemma 3全部功能,或通过Kaggle、Hugging Face下载模型。改进的代码库支持高效微调和推理,无论是Google Colab、Vertex AI,甚至消费级GPU,都能轻松训练和微调模型。Gemma 3还提供多种部署环境,包括Vertex AI、Cloud Run、Google GenAI API、本地环境和其他平台,可以根据应用和基础设施选择最佳方案。值得一提的是,英伟达针对Gemma 3进行了深度优化,从Jetson Nano到最新的Blackwell芯片,都能获得极致性能体验。NVIDIA API中已推出Gemma 3,只需一个API调用即可快速原型开发。除此之外,Gemma 3也针对Google Cloud TPU进行了优化,并通过开源ROCm堆栈与AMD GPU集成。对于CPU执行,Gemma.cpp能够提供直接解决方案。模型架构Gemma 3模型沿用了与前代版本相同的解码器Transformer 结构,其大部分架构元素与前两代Gemma版本类似。研究采用了分组查询注意力(Grouped-Query Attention, GQA),并结合了 RMSNorm的后归一化(post-norm)和前归一化(pre-norm)。受其他团队的启发,他们用QK-norm替换了Gemma 2的软上限(soft-capping)。研究者在自注意力机制中交替使用局部滑动窗口自注意力和全局自注意力,按照5层局部层对应1层全局层的模式排列,模型的第一层为局部层。Gemma 3模型支持最长128K个token的上下文长度,但1B规模的模型例外,仅支持32K token。在全局自注意力层上,研究者将RoPE的基准频率从10K提高到1M,而局部层的频率保持在10K。此外,他们采用了位置插值方法,以扩展全局自注意力层的适用范围。视觉模态研究采用了一种400M规模的SigLIP编码器变体,这是一种基于Vision Transformer的模型,并使用CLIP损失的变体进行训练。Gemma视觉编码器的输入为调整尺寸后的896 × 896像素的方形图像,并在视觉助手任务的数据上进行微调。Gemma视觉编码器的固定分辨率为896 × 896像素,这在处理非方形比例或高分辨率图像时可能会引发问题,例如文本变得不可读,或小物体消失。为了解决这一问题,研究者在推理阶段引入了一种自适应窗口算法将图像划分为大小相等且不重叠的裁剪区域,以覆盖整个图像,并将每个裁剪区域调整至896 × 896像素后再输入编码器。预训练研究者在预训练过程中采用了与Gemma 2相似的知识蒸馏方法。相比Gemma 2,研究者为Gemma 3预训练模型分配了更大的token预算。其中,Gemma 3 27B规模的模型在14万亿个token上进行训练,12B 规模的模型使用12T个token,4B 规模的模型使用4T个token,而1B规模的模型使用 2T个token。在知识蒸馏过程中,研究者为每个token采样256个logit,并按照教师模型的概率分布进行加权。学生模型通过交叉熵损失函数学习教师模型的分布。计算基础设施研究者使用TPUv4、TPUv5e和TPUv5p训练模型,具体配置如表2所示。每种模型配置都经过优化,以最大程度减少训练步骤的执行时间。指令微调预训练模型通过改进的后训练方法转变为指令微调模型,相较于之前的方法有所提升。后训练方法依赖于一种改进版的知识蒸馏技术,该技术来自一个大型的IT教师模型,并结合了基于改进版本的BOND、WARM和WARP算法的强化学习微调阶段。使用多种奖励函数来提升模型在帮助性、数学、编程、推理、遵循指令和多语言能力方面的表现,同时最小化模型的有害性。包括通过人类反馈数据训练的加权平均奖励模型,代码执行反馈,以及解数学问题的真实奖励。研究人员对后训练阶段使用的数据进行了精细优化,以最大化模型的性能。研究中会过滤掉包含特定个人信息、不安全或有害内容、错误的自我识别数据以及重复样本的示例。此外,包含鼓励更准确的上下文归因、谨慎表述(hedging)和适当拒答的数据子集,有助于减少幻觉现象,同时提升事实性指标的表现,而不会影响模型在其他指标上的性能。预训练(PT)和指令微调(IT)模型,文本都以[BOS] token开头。需要注意的是,文本字符串「[BOS]」并不会自动映射到[BOS] token,因此必须显式添加。 | 









