背景
在GPT刚出来时,恰逢家里小娃经常要嚷嚷着听故事,讲一个什么什么的故事,可是苦于想象力的匮乏,要胡编一个带有主题思想的故事还挺难。作为程序员老爸,那时我就打算给它造一个AI爸爸出来。所以,这个文章算是这过程中的副产品吧。
我在写着写着,拖着拖着,GPT-4o演示出来了,那语音对话等能力加上及时响应性,一度我都打算中止相关开发和验证了。可是没想到,OpenAI他们也拖着拖着,一直没对外放出这块能力,居然又熬到了我快赶上了:D
我们基础的框架是实时对话能力,然后为了让这个AI爸爸更像样,就需要基于自己的声音训练一个模型。第一部分是一个比较基础的各种能力的调用,关注点在实时性上。第二点略难,但所幸已经有比较多种的开源实现了,只要整合即可。这篇文章先介绍第一部分。
实时对话的几步
我希望通过语音或文字输入和AI交流,背后的AI可自行选择。显然传统的拿到回答再通过语音合成,再播放的话,这延迟就太大了,我们需要在全程利用实时流式处理,以此提升响应速度,最后基本可以在1-2s内语音回答。整体的效果如下:
以下按执行顺序,分各步骤聊一下。
AI交互过程:语音输入
一般来说,我们通过语音输入的内容不会太长。尽管我们称之为实时,但这一步并非真正实时的。当前的AI也不能将prompt分多次上传呀?所以借助于录音之后,我们进行一次语音识别。当前(24年7月)大模型的多模态还不支持语音输入,故语音识别自然是免不了的。我们先说录制,我是MacOS机器,所以直接调起了sox程序实现内容的录制。我们只需要几句话就封装了一个录音机:
typeRecorderstruct{
bufbytes.Buffer
cmd*exec.Cmd
}
funcNewRecorder()*Recorder{
return&Recorder{}
}
func(r*Recorder)Start(){
r.buf.Reset()
r.cmd=exec.Command("sox","-d","-t","wav","-")
r.cmd.Stdout=&r.buf
err:=r.cmd.Start()
iferr!=nil{
log.Fatal(err)
}
}
//Stoprecording
func(r*Recorder)Stop(){
err:=r.cmd.Process.Signal(os.Interrupt)
iferr!=nil{
log.Fatal(err)
}
//Waitfortherecordingprocesstofinish
err=r.cmd.Wait()
iferr!=nil{
log.Fatal(err)
}
log.Debugf("Recordingstopped.recorded%dbytes",r.buf.Len())
}
func(r*Recorder)Buffer()*bytes.Buffer{
return&r.buf
}
接下来是将它转换为文字。这一步选择有很多,可以用OpenAI的whisper,我正好发现腾讯云有免费送很多的token,就用它的ASR功能了。已经有现成的SDK可调,几行代码即可搞定:
//将音频内容转为文本返回,出错返回err
func(a*ASRClient)ToVoice(fileTypestring,fileContents[]byte)(string,error){
request:=asr.NewSentenceRecognitionRequest()
//设置上传本地音频文件
request.SourceType=common.Uint64Ptr(1)
request.VoiceFormat=common.StringPtr(fileType)
request.EngSerViceType=common.StringPtr("16k_zh")
//将buf的内容base64编码后设置给request.Data
d64:=base64.StdEncoding.EncodeToString(fileContents)
request.Data=common.StringPtr(d64)
request.DataLen=common.Int64Ptr(int64(len(d64)))
response,err:=a.client.SentenceRecognition(request)
iferr!=nil{
return"",fmt.Errorf("fileType:%v,len:%v,err:%w",fileType,len(fileContents),err)
}
return*response.Response.Result,nil
}
AI交互过程:流式输出
我们知道AI的输出有流式和非流式,而我们后面还要将文字内容合成为语音呢,为了更快速的有响应,我们必然需要使用流式输出。然后可以一边将输出传递给另一个线程去做语音合成。
流式输出没啥可讲的,但AI交互这一块,还是要再提一下之前文章介绍过的一站式多模型管理:One API实用指南[1]。最开始我实现了多种模型的支持,后面接触到它后,果断将所有代码都移除了,那是人家做的事情,我这重复劳动就没意义了。
实时语音转换
有了比较实时的结果后,我们一边读出来,一边交给某个地方去合成(当然未来会是在本地模型或自己搭建的服务上,毕竟我是想用自己声音来讲故事的嘛)。我继续使用腾讯云的语音合成能力,非实时的方式也试过,调用后中间等待要花几秒时间,虽然说如果内容比较多时,刚开始的几秒还好,但是,咱发现有实时合成,那必须得上啊。
虽然有实时接口,但是上传并不支持持续数据流,只是下行实时,合成一部分语音就提前下发,于是我们得将要转换的内容拆分一下,我以一句话的句号来分段,这样一段段上传,然后将合成的内容提前播放,正好可以用播放掩盖掉后面合成的用时。核心代码也很简单:
//StreamTTS语音合成
//读取textChan中的数据,将它以。分割,然后合成语音
funcStreamTTS(voiceTypeint64,emotionCategorystring,textChanchanstring,audioChanchan[]byte){
varbufferstrings.Builder
varwgsync.WaitGroup
wg.Add(1)
s:=tts.NewRealTimeSpeechSynthesizer(int64(appId),secretId,secretKey,voiceType,emotionCategory,speed)
sentenceChan:=make(chanstring)
//启动一个goroutine来处理语音转换,这样才能按顺序
gofunc(){
deferwg.Done()
index:=1
forsentence:=rangesentenceChan{
log.Debug("----------------------------------")
log.Debugf("正在转换第[%d]段语音中,文字内容为:%s",index,sentence)
s.Run(sentence,audioChan)
index++
log.Debug("----------------------------------")
}
log.Info("**语音转换全部结束!!**")
}()
index:=1
for{
select{
caseresp,ok:=<-textChan:
if!ok{
log.Debugf("TextChanclosed,buflen:%d",buffer.Len())
//Channel已关闭
ifbuffer.Len()>0{
//发送句子到通道
sentenceChan<-strings.TrimSpace(buffer.String())
}
gotoEND
}
//log.Debugf("Speechrecv[%q]",resp)
buffer.WriteString(resp)
//按句号分割句子
content:=buffer.String()
sentences:=strings.Split(content,"。")
//重置buffer
buffer.Reset()
fori,sentence:=rangesentences{
sentence=strings.TrimSpace(sentence)
ifsentence==""{
continue
}
ifi==len(sentences)-1&&!strings.HasSuffix(content,"。"){
//最后一个句子可能是不完整的,保存到buffer中
buffer.WriteString(sentence)
}else{
sentenceChan<-sentence+"。"
// log.Debugf("发送第[%d]句子到sentenceChan:%s", index, sentence)
index++
}
}
}
}
END:
close(sentenceChan)
log.Debug("sentenceChanclosed")
wg.Wait()
}
起了两个goroutine,一个做分段,一个做合成。发现腾讯云的语音合成音色挺多的,有小女孩的童真声音,也有粤语、四川话等,试用了还蛮有意思。同时还有情感的描述,学习到语音合成也有它的语法,可以通过在文字中做一些标注,使用不同的声音和不同的情感等。想着如果一段话,借助AI帮标注出来,再让它合成或许情感会更丰富一些。
流式语音播放
声音多数都是流媒体传播的,所以不少播放器都是支持流式播放的。我让声音合成返回了mp3,然后借助于ebitengine/oto的库完成播放工作,这个库有点小问题,播放有时会卡住不播,估计是某种并发下的异常情况没处理好,稍微walk around了一下。
func(p*MyPlayer)Play(){
log.Debug("正在调用播放器来播放语音")
gop.readFromStream()
for{
ifp.readFinished||p.buffer.Len()>=minDataSize{
log.Debugf("已经收取足够语音数据,正在初始化解码器,readFinished:%v,buflen:%d",p.readFinished,p.buffer.Len())
//确保播放器在播放前初始化
ifp.player!=nil{
log.Debug("播放器已经存在,关闭现有播放器")
p.player.Close()
}
p.initializePlayer()
ifp.player!=nil&&!p.player.IsPlaying(){
log.Debug("未在播放中,调用播放器来播放语音,Play!")
time.Sleep(500*time.Millisecond)
p.player.Play()
}
ifp.player!=nil&&p.player.IsPlaying(){
log.Debug("播放器已经进入Playing")
break
}
log.Debug("未在播放中,将会重置播放器!")
}
time.Sleep(100*time.Millisecond)
}
}
func(p*MyPlayer)readFromStream(){
for{
select{
casedata,ok:=<-p.audioStream:
if!ok{
//Channelisclosed,stopreading
log.Warnf("audioStreamclosed?将退出播放器")
p.readFinished=true
return
}
p.buffer.Write(data)
log.Debugf("收取语音数据:%d, 剩余长度:%d",len(data),p.buffer.Len())
}
}
}
其中开始播放时,需要收集到一些数据才能开始。初始化后立即播放有时会没有声音,未来可能会找找有没更好用的库:) 暂时通过上面一些补丁算是稳定能用。
TUI装修美化一下
基本功能有了,最开始我是命令行的方式,想着毕竟要写个文章介绍一下,就用个最简单的TUI包装一下吧,临时学习了一下bubbletea库的使用。有小朋友和我说这个库有点复杂,刚开始看是这样的,当把遇到的几个问题和BUG修改完,似乎这个库也就是轻量、没那么复杂了:) 改BUG果然是学习东西的好门路!
基本UI
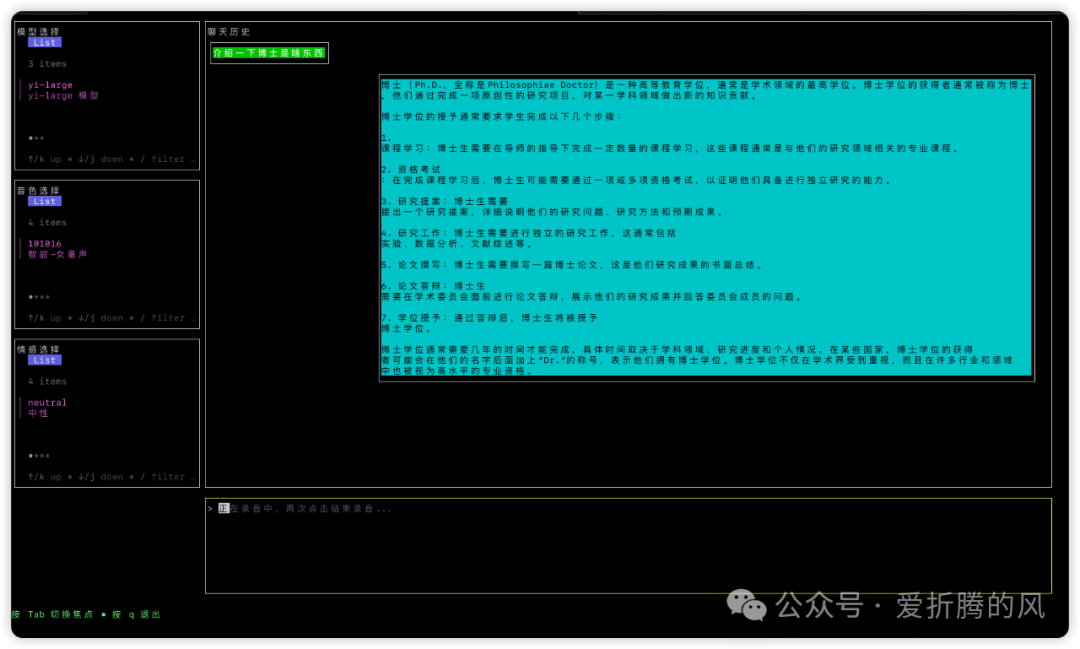
想着有些东西可能会调整着玩的:如模型、音色、情感等,就将它们放在左边的设置里了。当然这个列表还可以不断扩展,我这里仅是做个演示就没塞太多选项。然后是聊天历史,我们虽然是语音交流,文字也要同步展示出来,所以就给了个地方显示一下,也可以顺便看看上下文都是些什么。最后,输入中我们想着有时不方便语音说话,所以文字输入和语音输入同时支持。要再画个UI单独作为录音等,我又不想这么搞。我居然创造性的让这个文本框在点击它时进入录音状态,再次点击取消录音。同时这个文本框聚焦后能输入文字,就这么一石二鸟了,哈哈!想不到吧:)
以下是最后的UI,也是蛮粗糙的,但基本够用就行吧。
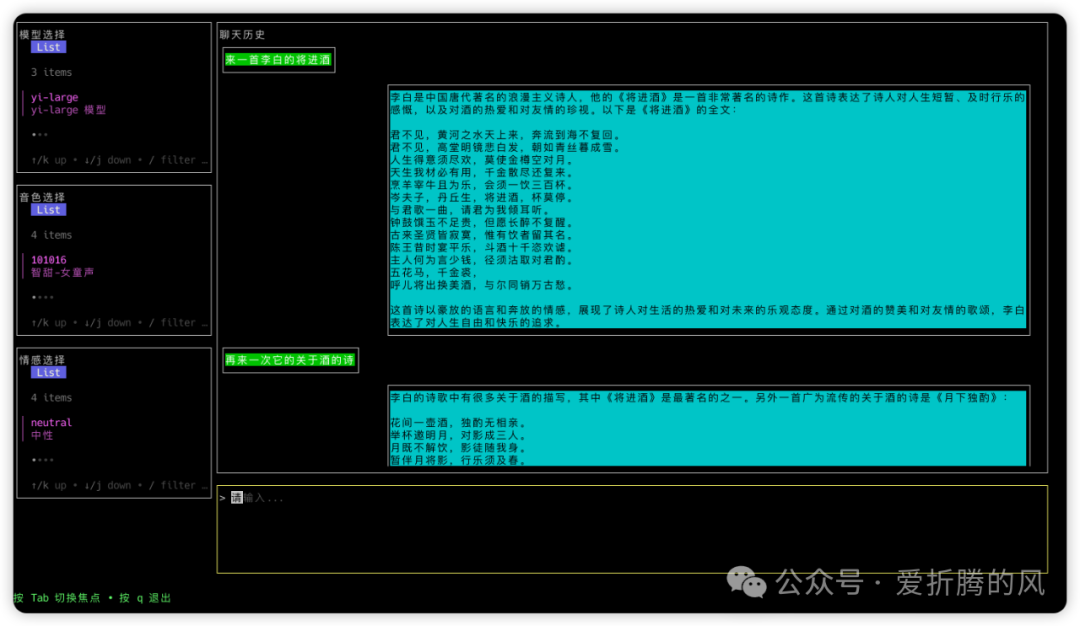
UI和逻辑分离
最开始随便在UI中调起一些逻辑,那真是个灾难,各种让UI无响应等,于是乎,学习到了bubbletea的消息处理机制。我们只需要简单的定义一些消息,将触发的一些动作作为一种行为转发出去即可。有点像我们过往Windows编程中的事件响应。
func(mmodel)Update(msgtea.Msg)(tea.Model,tea.Cmd){
//...省略
case"enter":
switchm.currentFocus{
case0:
selectedModel:=m.modelList.SelectedItem().(item)
m.notificationCh<-fmt.Sprintf("选择了模型:%s",selectedModel.Title())
m.eventChan<-Event{Type:"model",Payload:selectedModel.Title()}
case1:
selectedTone:=m.toneList.SelectedItem().(item)
m.notificationCh<-fmt.Sprintf("选择了音色:%s",selectedTone.Title())
m.eventChan<-Event{Type:"tone",Payload:selectedTone.Title()}
case2:
selectedEmotion:=m.emotionList.SelectedItem().(item)
m.notificationCh<-fmt.Sprintf("选择了情感:%s",selectedEmotion.Title())
m.eventChan<-Event{Type:"emotion",Payload:selectedEmotion.Title()}
case3:
log.Debug("选择了历史记录框")
m.notificationCh<-"选择了历史记录"
case4:
question:=m.questionInput.Value()
log.Debug("问题输入完毕",question)
m.questionInput.SetValue("")
m.notificationCh<-fmt.Sprintf("输入了问题:%s",question)
m.eventChan<-Event{Type:"question",Payload:question}
}
//省略
然后在其它线程中响应它即可。这期间为了处理鼠标的点击事件(对的,要自己封装去判断点到了哪个控件),发现边框等会占用1个字符,发现屏幕的宽度和高度是以字符数量来计算的。在我的Macbook Air屏幕上,它只有178x48大小。所以建议像我一样,手绘一个UI布局好好计算一下。整个UI为了让窗口自适应,需要比较好的响应tea.WindowSizeMsg事件,并且让我们的设置都是一个相对值。
中文字宽问题
在处理历史记录的展示过程中,为了让排版稍好看点,我们需要根据能显示的长度对结果的文字做重排。突然发现这也是个技术活,最开始是有些库只支持英文,对中文或其它文字长度计算有误。后面我基于go-runewidth库封装了下计算逻辑,这样中文+英文等计算宽度稍好一点:
//WrapWords使用mattn/go-runewidth库来精确计算字符宽度
funcWrapWords(sstring,maxWidthint)string{
varbuilderstrings.Builder
currentWidth:=0
for_,r:=ranges{
charWidth:=runewidth.RuneWidth(r)
ifr=='\n'{
currentWidth=0
}
ifcurrentWidth+charWidth>maxWidth{
builder.WriteString("\n")
currentWidth=0
}
builder.WriteRune(r)
currentWidth+=charWidth
}
returnbuilder.String()
}
后记
上述的实现已经在GitHub中开源了,需要请查看talk-with-ai[2],如果对你有用,欢迎Star。接下来的文章,可能会聊一下如何复刻你的声音,然后在这里用上。听听自己声音的回答到底是惊喜还是恐怖,你说呢?
EOF










