|
随着大语言模型的普及,特别是DeepSeek R1的出现,各行各业对大语言模型的私有化部署需求正在持续上涨。 对于大多数企事业单位来说,目前最急迫的并不是训练一个属于自己的模型,而是通过RAG和微调等方法,快速地进行部署与业务落地。 本文将介绍DeepSeek R1的各个版本的差异和GPU的选择,希望对你有所帮助。 1、DeepSeek R1各个版本的应用场景 DeepSeek R1的各个版本如下表所示: DeepSeek R1各个版本的应用场景: 1.5B:适用于对成本敏感,追求效率的简单任务场景。例如,一些基础的文本分类、简单的信息提取等任务。 7B & 8B:面向多场景中等复杂程度任务的通用模型。8B 版本在精度上有所提升,适合对输出质量有更高要求的场景。例如,可以应用于内容创作、翻译、编码问题和作为 AI 助手等。 14B:能够处理更为复杂的任务,尤其在代码生成等领域表现出色。 32B & 70B:这两个大参数版本定位于专业和高质量的任务需求。能够胜任需要极高精度的复杂任务,例如专业领域的文本生成、深度代码分析、以及需要大规模知识和推理的高难度问答等。 Zero (671B):满血版本。能够处理需要深入思考和迭代的复杂问题。此版本模型也更侧重于研究用途,例如探索模型深层思维过程和解决逻辑性难题。
2、英伟达GPU 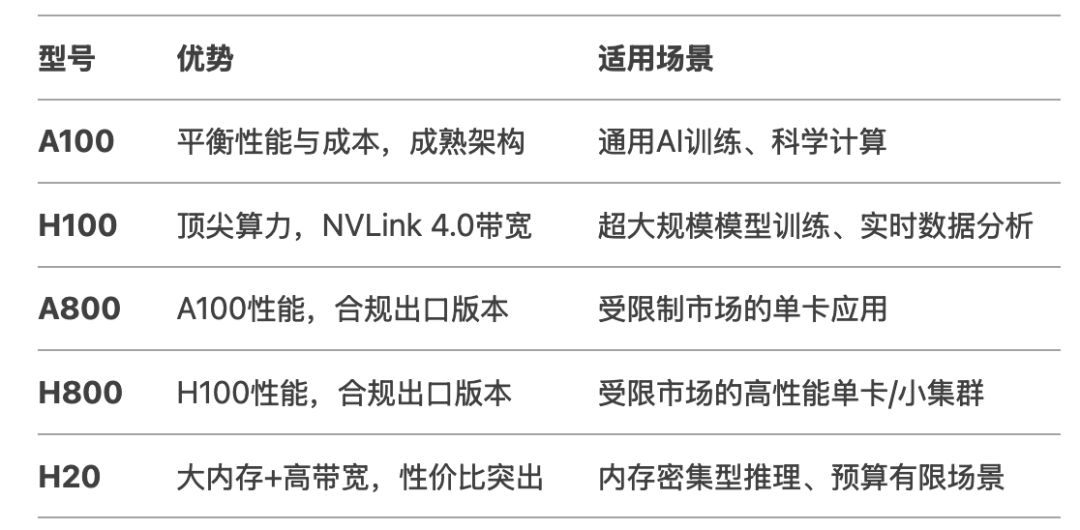
NVIDIA A100 80GB NVIDIA H100 80GB NVIDIA A800 80GB 架构:Ampere(限制版) 内存:80GB HBM2e FP32 性能:19.5 TFLOPS(与A100相同) NVLink:带宽400 GB/s(版本3,受限) 价格:约20,000美元 特点: A100的出口限制版本,NVLink带宽从600 GB/s降至400 GB/s,可能针对特定地区市场(如中国)。性能与A100一致,但多卡互联效率降低,适合单卡或低带宽需求场景。
NVIDIA H800 80GB 架构:Hopper(限制版) 内存:80GB HBM2e FP32 性能:67 TFLOPS(与H100相同) NVLink:带宽400 GB/s(版本4,受限) 价格:30,000–40,000美元 特点: H100的受限版本,NVLink带宽大幅缩减至400 GB/s,可能同样面向受出口限制的市场。计算性能未缩水,但多GPU扩展性受限,适合单卡高性能需求或小规模集群。
NVIDIA H20(未发布) 架构: Hopper(限制版) 内存: 96GB HBM3(首款搭载HBM3的型号) FP32 性能: 44 TFLOPS(低于H100) NVLink: 带宽900 GB/s(版本4,受限) 价格: 预计12,000–15,000美元 特点: 面向性价比市场,虽FP32性能仅为H100的65%,但配备更大的HBM3内存和完整NVLink带宽,适合内存密集型任务(如大语言模型推理)。价格优势明显,可能定位中高端企业级应用。
3、模型内存需求评估 模型的内存需求主要包括权重内存、KV缓存和激活内存三个部分。 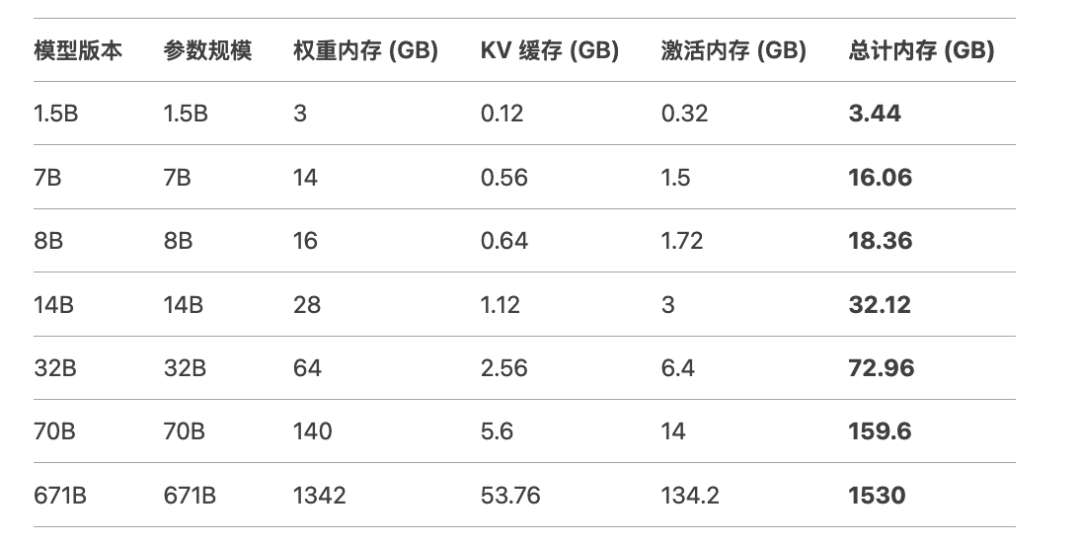

4、模型规模与硬件适配建议
小型模型(1.5B–8B) 中型模型(14B–32B) 大型模型(70B) 超大规模模型(671B)
喜欢本文请帮忙:“关注、按赞、分享、推荐”。感谢您的支持! | 









