|
一、概述 提示词是指向人工智能大模型提供的输入信息,通常包含关键词、问题或指令,可以引导大模型生成与用户期望相符的回应。我们在豆包,DeepSeek等大模型中输入的问题都可以认为一个简单的提示词,不过为了真正得到我们需要的结果,提示词可以很复杂,比如如果我想从文本中提取摘要信息,就可以用以下的提示词:
你是一个被设计来执行文本摘要任务的助手,你的工作是从原始文本中提取关键信息,并生成一个简短、清晰且保留原文主旨的摘要。接下来,我会在下方提供一串“需要进行文本摘要的文本”。你需要返回给我摘要的结果,我应该能从摘要中快速了解文本的主要内容。需要进行文本摘要的文本: ### 当地时间周一晚间,印度总理莫迪向全国发表了电视讲话,他表示,印度只是“暂停”了对巴基斯坦的军事行动,并将“以自己的方式”报复任何袭击。 莫迪表示,他正在监视巴基斯坦的每一步行动。他还暗示了上周不断升级的紧张局势所笼罩的核威胁,并补充说,在未来与巴基斯坦的任何冲突中,他们都不会容忍“核讹诈”。 印巴这两个拥核国家为结束近年来最严重的一轮暴力冲突而达成的脆弱停火协议在周末得以维持,在两国边境沿线没有发生夜间交火。印度军方表示:“整个晚上,查谟和克什米尔以及边界线其他地区基本保持和平。” 莫迪在讲话中提到了未来可能的谈判,但他指出,“如果我们与巴基斯坦对话,那将只讨论打击恐怖主义……讨论巴控克什米尔”。 他声称,印度政府将毫不犹豫地使用武力来消除巴基斯坦境内的恐怖分子营地,并称这是与邻国巴基斯坦关系的“新常态”。 印巴此次停火结束了由印度控制的克什米尔地区发生的一起武装袭击引爆的持续数日的交火。印度方面指责巴基斯坦应对此事件负责,但巴基斯坦方面否认参与其中。 在电视讲话中,莫迪没有提到美国,也没有把停火协议归功于特朗普。相反,他说,在印度军队袭击巴基斯坦“心脏”后,是巴基斯坦方面首先呼吁缓和紧张局势。上周六美国总统特朗普宣称美方发起外交斡旋,促成了停火协议。 而特朗普周一在白宫发表评论称,美国对印度和巴基斯坦的干预“阻止了一场核冲突”。他说:“我认为这可能是一场糟糕的核战争,数百万人可能会丧生。所以我对此非常自豪。” 莫迪指出:“因此,当巴基斯坦呼吁并表示不会再沉迷于任何形式的恐怖活动或军事冒险时,印度考虑给并给出了回应。” 不过,巴基斯坦三军新闻局局长乔杜里在新闻发布会上表示,巴基斯坦从未主动要求停火,在对印度的袭击做出回应之后,巴方在国际社会斡旋下对印方提出的停火要求做出了回应。 在印度总理发表讲话之前,巴基斯坦军方发表声明称:“任何人都不应该怀疑,无论何时,当巴基斯坦的主权受到威胁,领土完整受到侵犯时,我们都将采取全面而果断的报复措施。” ### DeepSeek返回结果如下:
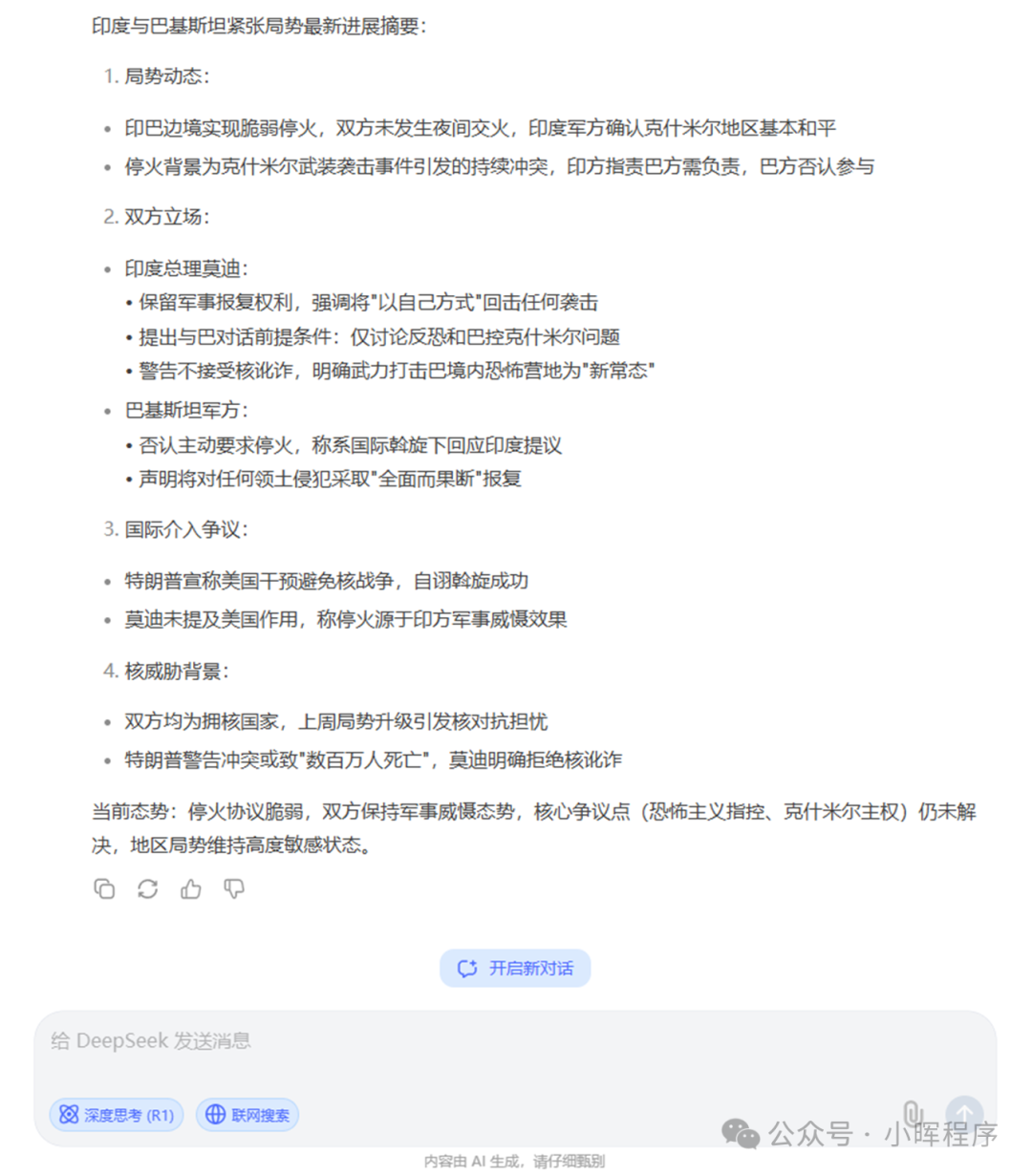
提示工程是通过精心设计、优化输入信息(提示),来引导人工智能生成高质量、准确、有针对性的回应。它是一门高度依赖经验的工程科学,涉及对问题表述、关键词选择、上下文设置及限制条件等方面的细致调整,以提高人工智能回应的有效性、可用性和满足用户需求的程度。 通过提示工程我们可以让大模型更精准的生成我们需要的结果。不过作为程序员,我们可以更进一步,用langchain来访问大模型,结合提示词模板来得到更精确的回答,甚至实现一定程度的自动化。 二、普通聊天 fromlangchain_Ollama.chat_modelsimportChatOllamafromlangchain_core.promptsimportChatPromptTemplatefromlangchain_core.output_parsersimportStrOutputParseroutput_parser=StrOutputParser()#以字符串格式输出#调用本地deepseek-r1:7b大模型llm=ChatOllama(model="deepseek-r1:7b",temperature=0.1)prompt=ChatPromptTemplate.from_messages([("system","你是一位顶级人工智能技术专家,同时具有很高的文字水平"),("user","{input}")])#以链式方式将提示词、大模型和输出格式串联起来chain=prompt|llm|output_parserprint(chain.invoke({"input":"介绍一下大语言模型技术原理"}))返回结果如下: fromlangchain_openaiimportChatOpenAIfromlangchain_core.output_parsersimportStrOutputParserfromlangchain.schema.runnableimportRunnableLambda, RunnablePassthroughfromlangchain.promptsimportPromptTemplatemodel = ChatOpenAI( model='deepseek-chat', openai_api_key=<你的API KEY>, openai_api_base='https://api.deepseek.com', max_tokens=1024)prompt_template2 ="你是一名文档处理专家,精通阅读理解和文字编写,具有很高的审美水平和文字总结能力。有如下的文章{content},请帮我总结摘要。"PROMPT = PromptTemplate( template=prompt_template2, input_variables=["content"])chain = ( {"content": RunnablePassthrough()} | PROMPT | model | StrOutputParser())# 读取文件,从文件中获取文章内容content =""try: # 使用 with 语句打开文件 withopen('example.txt','r', encoding='utf-8')asfile: # 读取文件的全部内容 content = file.read() #print(content)exceptFileNotFoundError: print("文件未找到,请检查文件路径和文件名。")
input_data = { "content": content}# 使用 invoke 方法调用链result = chain.invoke(input_data)print(result)
文件中存储了盗墓笔记七星鲁王宫的第二章的内容,可以看到,调用deepseek大模型的API后,给出了我们比较准确的文字摘要: 三、根据示例进行回答 我们除了可以直接对大模型提问,还可以教授给大模型我们需要的回答风格,给出几个实际示例,让大模型根据我们的实例来进行回答。 fromlangchain_openaiimportChatOpenAIfromlangchain_core.output_parsersimportStrOutputParserfromlangchain.schema.runnableimportRunnableLambda, RunnablePassthroughfromlangchain.promptsimportPromptTemplateexamples = [ { "question":"成年蓝鲸和成年大象哪个更大?", "answer": """ 这里需要跟进问题吗:是的。 跟进:成年蓝鲸有多大? 中间答案:成年蓝鲸有30米长,130吨重。 跟进:成年大象有多大? 中间答案:成年大象有4米长,5吨重。 所以最终答案是:蓝鲸。 """
}, { "question":"阿里巴巴创始人是哪一年出生的?", "answer": """ 这里需要跟进问题吗:是的。 跟进:阿里巴巴的创始人是谁? 中间答案:阿里巴巴的创始人是马云。 跟进:马云的出生年份是多少? 中间答案:马云出生于1964年9月10日。 所以最终答案是:1964年。 """
}]example_prompt = PromptTemplate( input_variables=["question","answer"], template="问题:{question}\n{answer}",)prompt = FewShotPromptTemplate( # 示例 examples=examples, # 示例提示词 example_prompt=example_prompt, # 结束符 suffix="问题:{question}", # 输入变量 input_variables=["question"])model = ChatOpenAI( model='deepseek-chat', openai_api_key=<你的API KEY>, openai_api_base='https://api.deepseek.com', max_tokens=1024)chain = ( {"question": RunnablePassthrough()} | prompt | model | StrOutputParser())question ="腾讯创始人是哪一年出生的?"result = chain.invoke(question)print(result)# 输出问题:腾讯创始人是哪一年出生的?这里需要跟进问题吗:是的。跟进:腾讯的创始人是谁?中间答案:腾讯的创始人是马化腾。跟进:马化腾的出生年份是多少?中间答案:马化腾出生于1971年10月29日。所以最终答案是:1971年。
可以看到,大模型仿照我们例子中的要求给出了我们需要格式的答案。这其实有点类似RAG(检索增强生成)了,后面我会专门写篇文章介绍这个技术。这里的例子如果很多的话,不适合全部传递给大模型,还可以通过example selector方式寻找到最适配我们问题的例子,代码如下: #使用示例选择器fromlangchain.prompts.example_selectorimportSemanticSimilarityExampleSelector#fromlangchain_community.vectorstoresimportChromafromlangchain_community.vectorstoresimportFAISSfromlangchain_openaiimportOpenAIEmbeddingsfromlangchain_ollamaimportOllamaEmbeddings#fromlangchain_chromaimportChroma#使用语义相似性示例选择器example_selector=SemanticSimilarityExampleSelector.from_examples(#示例examples,#嵌入模型OllamaEmbeddings(model="deepseek-r1:32b"),#向量数据库FAISS,#最大示例数k=1,)#选择与输入最相似的示例question="腾讯创始人是哪一年出生的?"selected_examples=example_selector.select_examples({"question":question})print(f"找出最相似的示例:{question}")forexampleinselected_examples:print("\n")fork,vinexample.items():print(f"{k}:{v}")#输出找出最相似的示例:腾讯创始人是哪一年出生的?question:阿里巴巴创始人是哪一年出生的?answer:这里需要跟进问题吗:是的。跟进:阿里巴巴的创始人是谁?中间答案:阿里巴巴的创始人是马云。跟进:马云的出生年份是多少?中间答案:马云出生于1964年9月10日。所以最终答案是:1964年。可以看到,跟问题“腾讯创始人是哪一年出生的?”最接近的答案例子是“阿里巴巴创始人是哪一年出生的?”。 四、根据回答,进一步自动化获得执行的结果 还有一种比较有意思的提示词使用方法是,让大模型返回给我们一段代码,再由系统去自动执行,得到我们需要的结果。这样的话,会突破我们的返回内容界限。普通的大语言模型返回的只是文本,我这里用一个提示词尝试让大模型返回一段代码,并直接执行这段代码,得到想要的结果。 defgenerate_chart(df):#画出统计图表df=df.fillna(value="None")prompt_template2="你是一名顶级数据可视化专家,精通python数据可视化,具有很高的审美水平。使用matplotlib进行数据可视化,有如下的数据{df},请选择合适的图表进行可视化,配色要美观,并把图表保存为chart.png,不需要显示,给我代码,不要其他内容,图表要可以显示中文。" ROMPT=PromptTemplate(template=prompt_template2,input_variables=["df"])chain=({"df":RunnablePassthrough()}|PROMPT|model|StrOutputParser())input_data={"df":df}#使用invoke方法调用链result=chain.invoke(input_data)result=result.replace("```python","")result=result.replace("```","")print(result)exec(result)return'chart.png' ROMPT=PromptTemplate(template=prompt_template2,input_variables=["df"])chain=({"df":RunnablePassthrough()}|PROMPT|model|StrOutputParser())input_data={"df":df}#使用invoke方法调用链result=chain.invoke(input_data)result=result.replace("```python","")result=result.replace("```","")print(result)exec(result)return'chart.png'这里的数据df如下: data={'开发区代码':['S327012','S327011'],'开发区名称':['经济开发区1','经济开发区2'],'地块数量':[320,27],'总面积(公顷)':[438.332284,66.609016]}大模型返回的代码如下: importmatplotlib.pyplotaspltimportpandasaspddata={'开发区代码':['S327012','S327011'],'开发区名称':['经济开发区1','经济开发区2'],'地块数量':[320,27],'总面积(公顷)':[438.332284,66.609016]}df=pd.DataFrame(data)plt.rcParams['font.sans-serif']=['SimHei']#设置中文显示plt.rcParams['axes.unicode_minus']=Falsefig,(ax1,ax2)=plt.subplots(1,2,figsize=(12,6))colors=['#4C72B0','#DD8452']#地块数量柱状图ax1.bar(df['开发区名称'],df['地块数量'],color=colors,width=0.6)ax1.set_title('开发区地块数量对比',pad=20,fontsize=14)ax1.set_ylabel('地块数量',fontsize=12)ax1.grid(axis='y',linestyle='--',alpha=0.7)#总面积柱状图ax2.bar(df['开发区名称'],df['总面积(公顷)'],color=colors,width=0.6)ax2.set_title('开发区总面积对比(公顷)',pad=20,fontsize=14)ax2.set_ylabel('面积(公顷)',fontsize=12)ax2.grid(axis='y',linestyle='--',alpha=0.7)plt.tight_layout()plt.savefig('chart.png',dpi=300,bbox_inches='tight')plt.close()通过python的exec()函数自动执行这段代码,得到可视化结果: 可以看到大模型返回的代码可以直接自动执行,并得到不错的展示结果,这个方法可以用到我们平时开发中,不一定是画图,很多中间过程可以让大模型自动生成,而我们只要调用这个中间结果就可以了。 大模型提示词的玩法层出不穷,好玩的创意也很多,我们可以多去关注,并多去“玩”,肯定可以发现更有意思的玩法。 | 









