|
多Agent系统(Multi-Agent System,MAS)近年来在复杂推理任务中表现出色,但代价是巨大的计算开销。一个自然的问题是:能否用单个agent配合技能库来替代多agent协作,同时保持性能?论文通过实验发现,这种"编译"策略确实可行——在保持准确率的同时,token消耗降低54%,延迟降低50%。然而,更深层的问题随之浮现:当技能库规模扩大时,AI的技能选择能力会如何变化? 论文揭示了一个惊人的现象:技能选择准确率并非逐渐下降,而是在达到某个临界规模后急剧崩溃,呈现出类似人类认知容量极限的"相变"特征。 从多agent到单agent:一种"编译"视角 论文提出将MAS(Multi-Agent System,多智能体系统)"编译"为SAS(Single-Agent with Skills,单agent技能系统)的框架。在MAS中,专门化的agent通过自然语言进行显式通信协作;而在SAS中,这些角色被内化为可选择的"技能",在统一的上下文中执行。 技能被定义为一个三元组:语义描述符(用于技能选择)、执行策略(指定如何执行)、以及执行后端(外部工具或内部执行)。与工具不同,技能不仅封装了"做什么",还封装了"如何推理"。 
[Figure 1: 基于技能的agent:效率提升与扩展限制]图(a)展示了将多agent系统编译为单agent技能库可减少通信开销,降低延迟和token使用;图(b)展示了技能选择准确率随库规模增长呈非线性下降,在容量阈值处出现相变,层级路由可通过将技能组织成结构化类别来恢复可靠选择。 哪些多agent系统可以被编译? 论文明确了可编译的条件:(1)通信可序列化——agent交互可以按顺序排列而不丢失信息;(2)共享历史——agent输出仅依赖共享历史,无私有状态;(3)同质骨干——所有agent使用相同的底层模型。 
[Table 1: 常见多agent架构的可编译性]流水线架构、路由-工作者架构、迭代优化架构可编译;辩论/对抗架构、并行采样、私有信息架构不可编译。 编译效率:token减少54%,延迟减少50% 论文在三个基准任务上验证了编译效率:GSM8K(数学推理)、HumanEval(代码生成)、HotpotQA(多跳问答)。 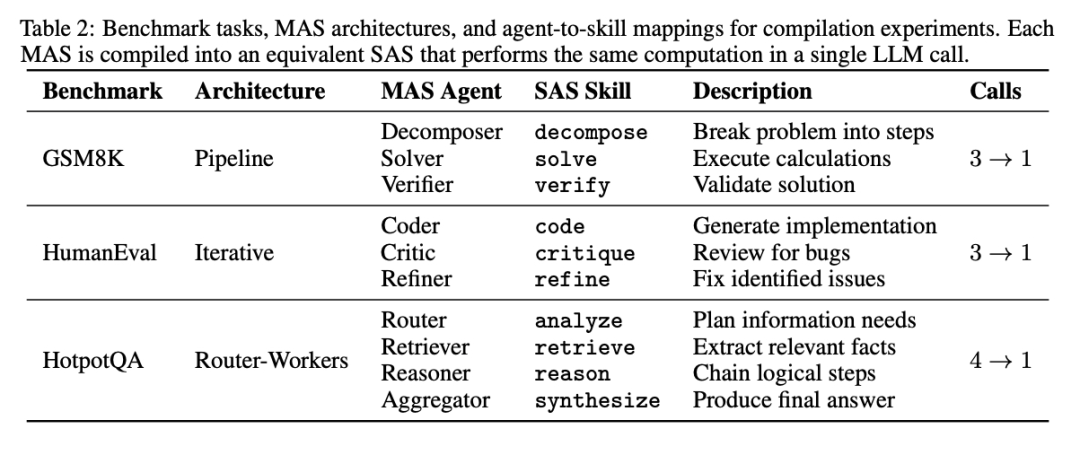
[Table 2: 基准任务、MAS架构和agent到技能的映射]每个MAS被编译为等效的SAS,在单次LLM调用中执行相同计算。GSM8K使用分解器、求解器、验证器三个agent;HumanEval使用编码器、评论器、优化器;HotpotQA使用路由器、检索器、推理器、聚合器。 
[Table 3: MAS与SAS编译后的性能和效率对比]编译后的SAS在所有基准上准确率变化在-2.0%到+4.0%之间,平均提升+0.7%;token消耗平均减少53.7%,延迟平均减少49.5%,API调用从3-4次减少到1次。 在HotpotQA上,SAS甚至比MAS准确率高出4.0%,可能是因为统一上下文使检索和推理步骤之间的信息整合更好。 认知科学视角:技能选择的容量极限 论文的核心贡献在于揭示了技能选择的扩展规律。借鉴认知科学的四个基础理论: (1)希克定律:人类选择反应时间随选项数量对数增长,但在约8个选项后关系崩溃。 (2)认知负荷理论:米勒的"神奇数字7"揭示了工作记忆的基本限制,当认知负荷超过容量时,性能急剧下降。 (3)基于相似性的干扰:谢泼德的泛化普遍定律表明,混淆概率随心理距离指数衰减;语义相似的技能会在选择过程中相互干扰。 (4)层级处理与分块:专家通过层级组织管理复杂性,每层4-8个项目与工作记忆容量匹配。 扩展定律:相变而非渐进衰退 论文提出技能选择准确率遵循复合衰减定律,由容量阈值κ和语义干扰共同控制。 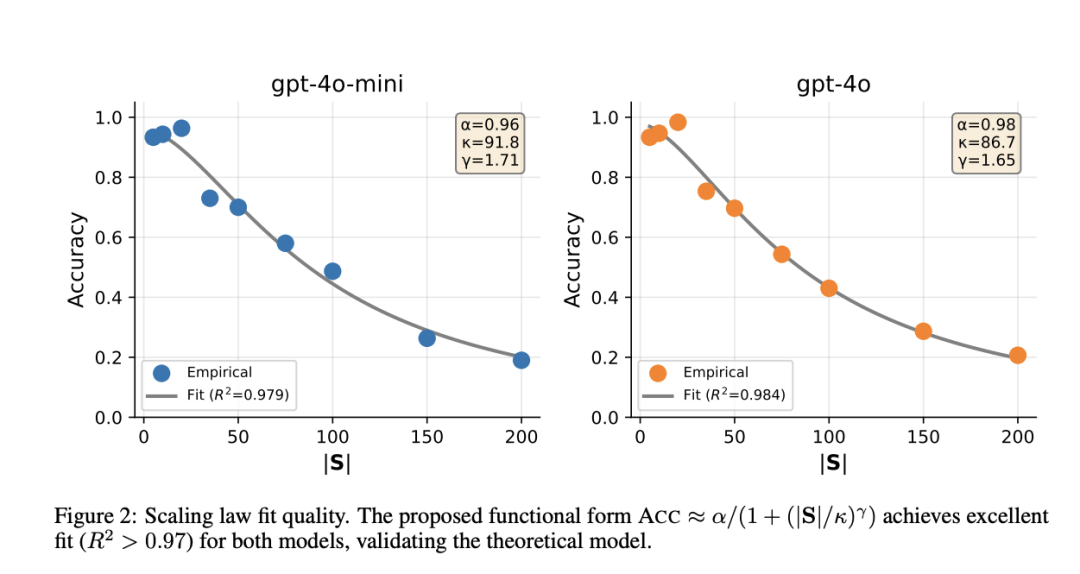
[Figure 2: 扩展定律拟合质量]在GPT-4o-mini和GPT-4o上,提出的函数形式ACC ≈ α/(1+(|S|/κ)^γ)实现了优异拟合(R²>0.97)。GPT-4o-mini的拟合参数为α=0.96、κ=91.8、γ=1.71;GPT-4o为α=0.98、κ=86.7、γ=1.65。 实验结果显示:在小规模(|S|≤20)时,准确率保持在95%以上;但在|S|=50-100附近急剧下降,到|S|=200时降至约20%。衰减率γ>1表明超过容量阈值后的衰退速度快于线性。 语义混淆才是罪魁祸首 论文设计了控制实验,为每个基础技能生成0、1或2个"竞争者"技能——描述相似但操作不同。 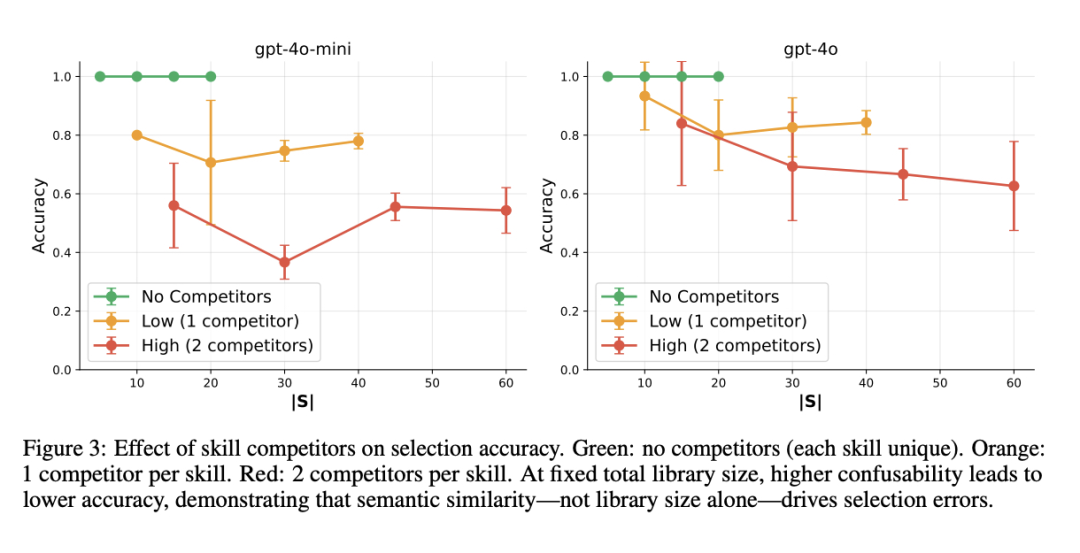
[Figure 3: 技能竞争者对选择准确率的影响]无竞争者时(绿色),即使|S|=20准确率仍为100%;1个竞争者(橙色)导致准确率下降7-30%;2个竞争者(红色)导致下降17-63%。 这证明了语义结构决定选择难度,而非单纯的库规模。在相同|S|=20时,用基础-竞争者对替换独特技能会导致18-30%的准确率下降。 指令复杂度的影响出乎意料 论文测试了三种执行策略复杂度(简单约30 token、中等约100 token、复杂约300 token)对选择准确率的影响。 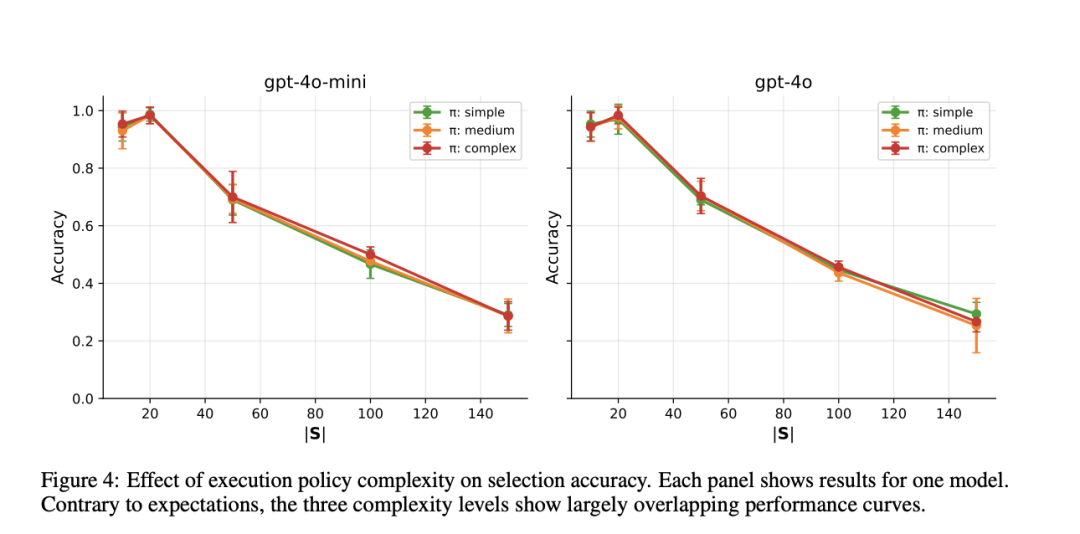
[Figure 4: 执行策略复杂度对选择准确率的影响]与预期相反,三种复杂度水平在两个模型上都显示出基本重叠的性能曲线,差异在标准误差范围内。 这一"零结果"表明,现代transformer架构可能能够有效过滤长上下文中的相关信息,减轻了复杂策略带来的预期认知负荷。 层级路由:突破容量限制的解决方案 当平面选择失败时,层级路由可以恢复可靠的扩展。通过将技能选择分解为从粗到细的决策,确保每个决策点涉及的选项数量低于容量阈值。 
[Figure 5: 层级路由对选择准确率的影响]蓝色为平面选择,红色为朴素领域层级。层级路由在技能库规模扩大时有效缓解了选择准确率的下降。 这与认知科学中关于分块和菜单设计的发现一致:将压倒性的选择集转化为可管理的决策序列。 论文的三个主要贡献值得关注:(1)证明了基于技能的系统可以在显著降低token使用和延迟的同时近似多agent性能;(2)刻画了技能选择的非线性扩展限制,确定了容量阈值,并证明语义混淆而非库规模本身驱动了性能下降;(3)展示了层级路由可以缓解扩展限制。 这项工作为设计可扩展的基于技能的agent系统提供了认知科学基础的设计原则:技能描述符应强调独特特征,避免可能适用于多个技能的通用描述。 | 









