|
Jina AI是一家成立于2020年的人工智能公司,专注于开发用于搜索和智能分析的开源软件。提供了非常多好用的API,例如Jina Reader可以将网页解析为Markdown文档、Reranker可以对RAG的向量模型检索到的文档进行重排序等,除了在线API,在HuggingFace上也开源了若干模型。 今天我们要使用的,是Jina提供的文本切分工具,它是以REST API形式提供服务的,主页为: https://jina.ai/segmenter/ Jina Segment API提供语义切分能力,更重要的是,它是免费的,不过国内用户需要注意自己的网络是否能够访问。 下图是官方网站提供的对《汉书》的切分效果,可以看出,对于文言文,也可以有比较好的切分结果。 
API有一些参数,可以在官方页面上通过交互式的方式进行探索,找到一个最优参数后,就可以固定到自己的工作流中了。 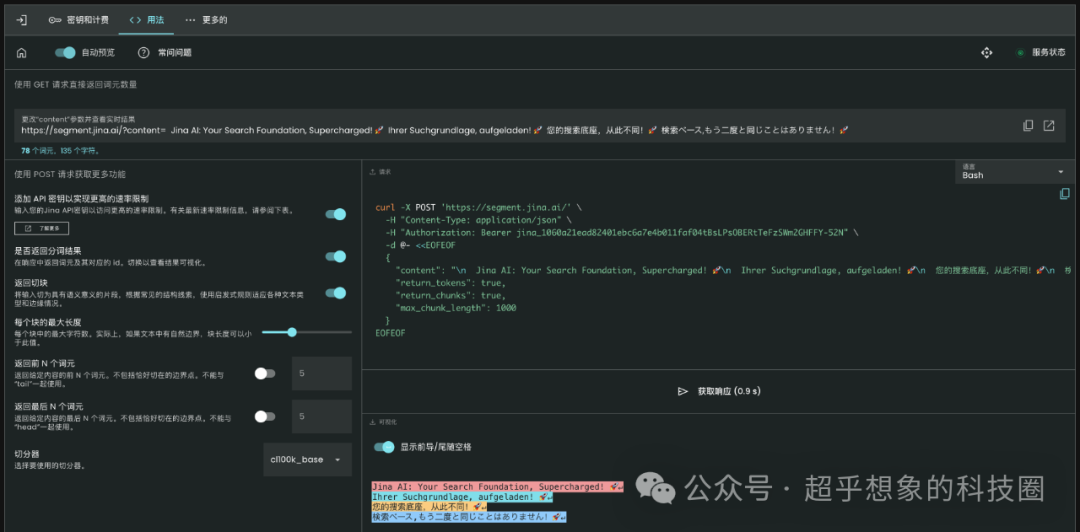
效果 从下图可以看出,使用Jina Segment API,最终的问答结果,相比Baseline还是有一定差距的,从概述中《汉书》的切分效果也可以看出,Jina会把标题和正文切割开,而在RAG场景中,标题的作用一般是非常大的,我们在使用RAG技术构建企业级文档问答系统:切分(1)Markdown文档切分的实验中也验证了这一点。 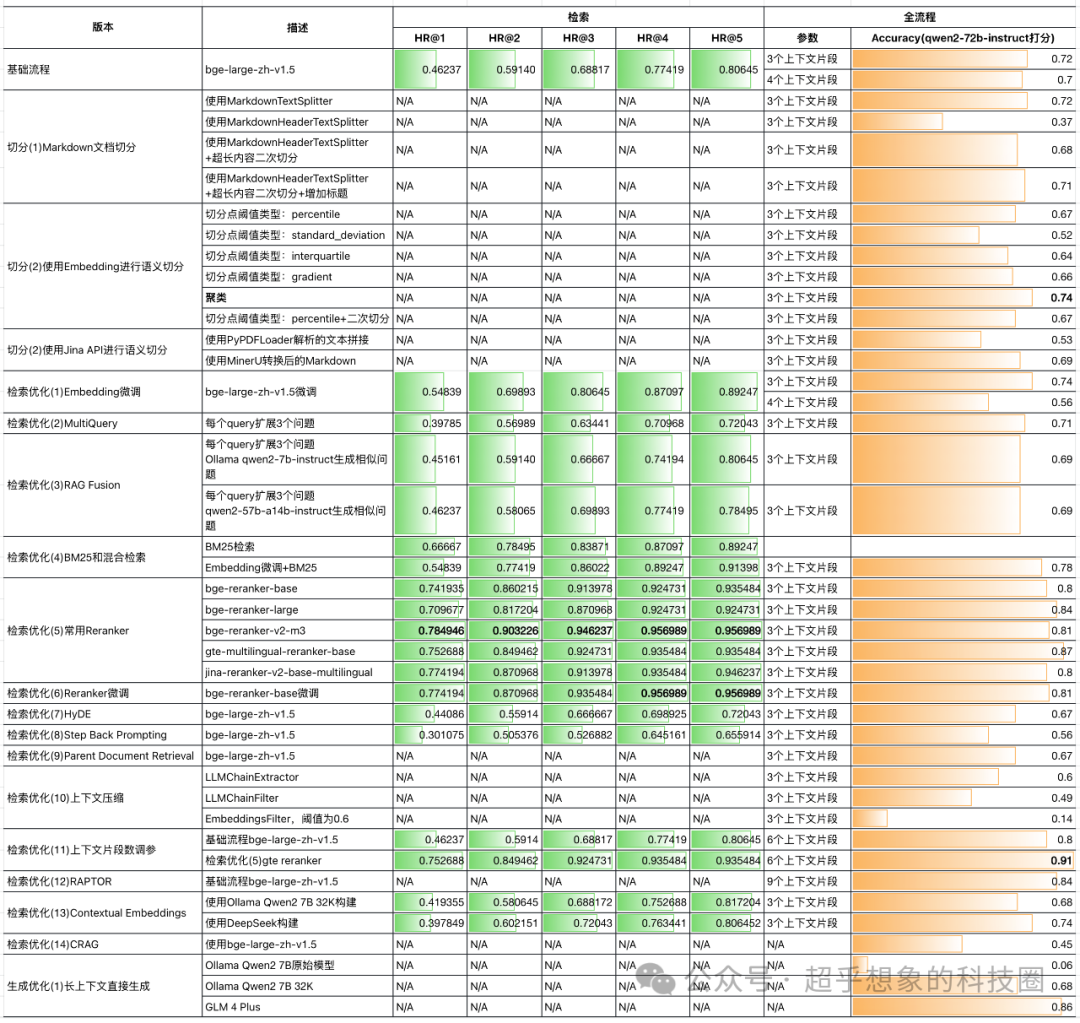
代码 本文对应完整代码已开源,地址在:https://github.com/Steven-Luo/MasteringRAG/blob/main/split/03_jina_segment_api.ipynb 由于是调用Jina API,切分的核心代码非常简单,使用POST请求将全文放到content中即可,其他参数可以直接从官方网站拷贝。
Document
(text,max_len=):
url=
headers={
:,
:
}
data={
:text,
:,
:,
:max_len
}
response=requests.post(url,headers=headers,json=data)
resp_json=response.json()
chunks=resp_json[]
[Document(page_content=chunk.strip())chunkchunkschunk.strip()!=] |










