|
前几天在 Mac 上安装了 Ollama,并下载了 Qwen2.5-VL 7B 做了一些测试,整个过程还挺有意思,分享给大家。 1 Mac 安装 Ollama进入 Ollama 官网 ,我的电脑是 Mac Studio ,所以选择 MacOS 下载 。  下载完成后,双击安装 ,安装完成后界面如下图:  2 下载 Qwen 2.5 VL 7BQwen 2.5-VL 是阿里巴巴通义千问团队开发的一款开源的旗舰级视觉语言模型。 它能够处理文本、图像和视频,并具备强大的视觉理解和交互能力。该模型有不同参数规模(如 3B、7B 和 72B),适用于从边缘 AI 到高性能计算的多种场景 。 下载 Qwen 2.5 VL 有两种方式 : 1、通过命令行请求 ollama pull qwen2.5vl:7b
 2、通过 Ollama GUI 界面安装 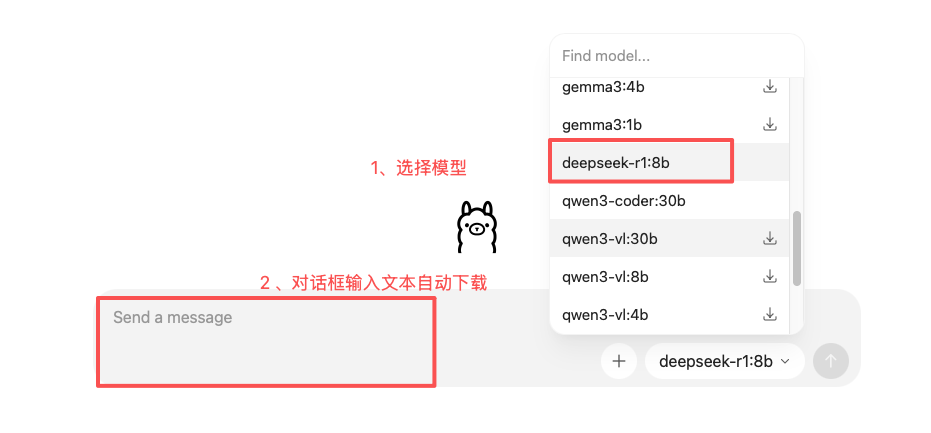 在 GUI 界面选择模型 ,若未下载会显示下载图标,然后在对话框中输入任意文本即可自动下载。 3 文本/图片体验下载完模型后,即可在对话框中进行对话。  当然我们也可以通过 ollama 启动模型后展开对话: ollama run qwen2.5vl:7b
接下来,进行图片检测,图片如下:  检测结果:  我们也可以通过该模型识别图像中的文字、公式或抽取票据、证件、表单中的信息,支持格式化输出文本:  4 程序调用分析图片我们可以编写 python 调用 Ollama 接口,实现模型分析图片:  Ollama 提供兼容 OpenAI 协议的接口 ,实现流式对话。 Ollama 提供兼容 OpenAI 协议的接口 ,实现流式对话。curl http://localhost:11434/api/chat -d '{
"model":"qwen2.5vl:7b",
"messages": [
{"role":"user","content":"写一段代码"}
]
}'
效果见下图 : 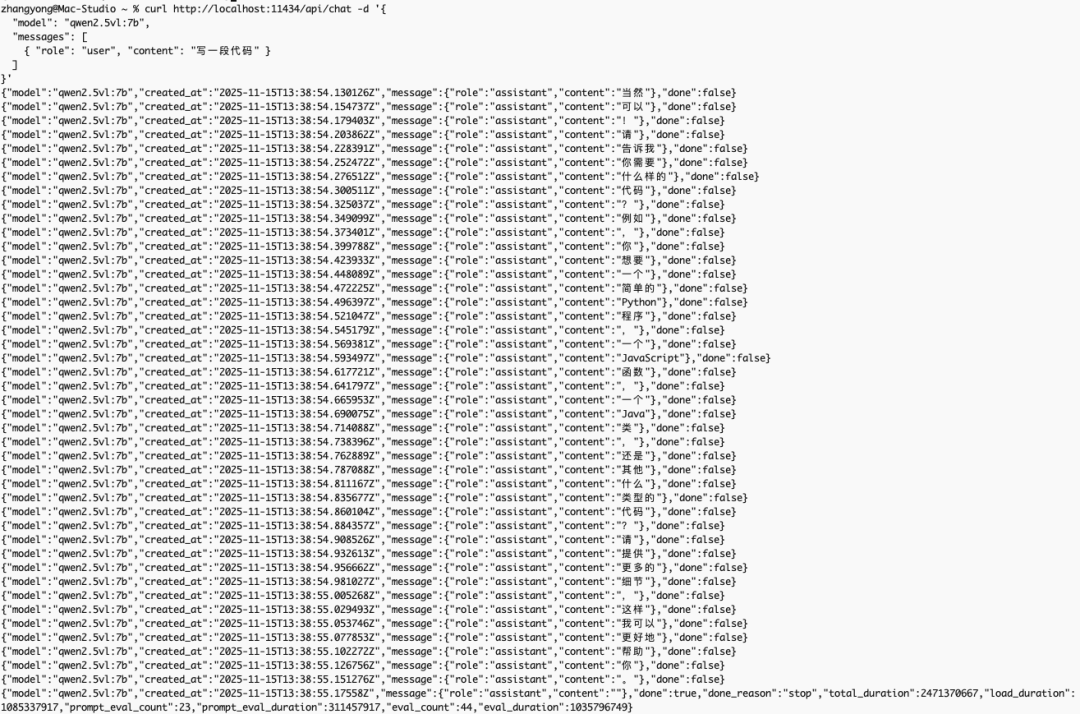 5 总结Qwen 2.5-VL 7B 简直就是“本地视觉小钢炮”。 笔者认为它尤其适合在如下场景中发挥作用: - 文档和票据解析:发票、合同、报表、扫描件,一次推理即可提取文字并生成结构化数据
- 表格与图表解析:财务报表、统计图表,快速提取表头和数据,方便后续分析
- 图片场景理解:仓库、机房、办公室等照片,自动识别物体和整体场景
- 多模态问答:结合图片和文本内容回答问题,支持科研、教育或产品原型
- 内容审核与合规检测:识别敏感文字或违规图像,本地部署保护隐私
| 









