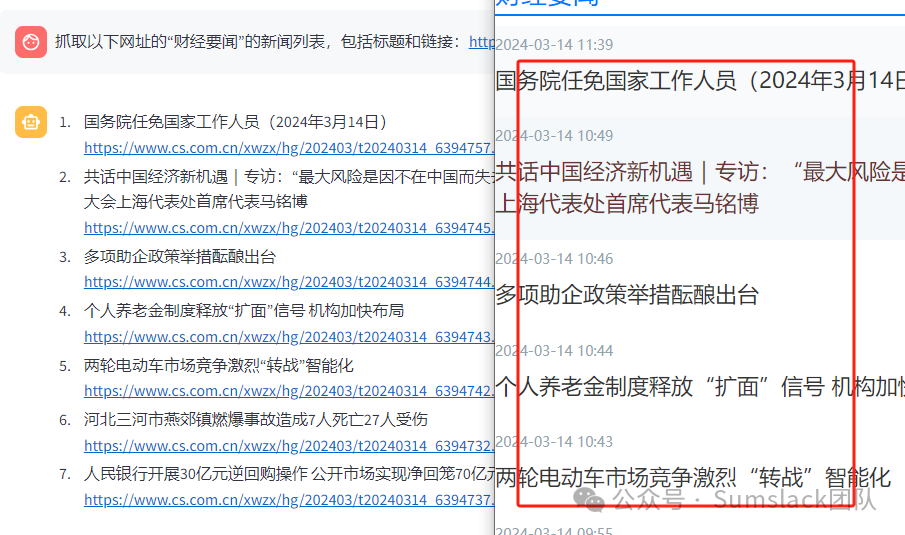
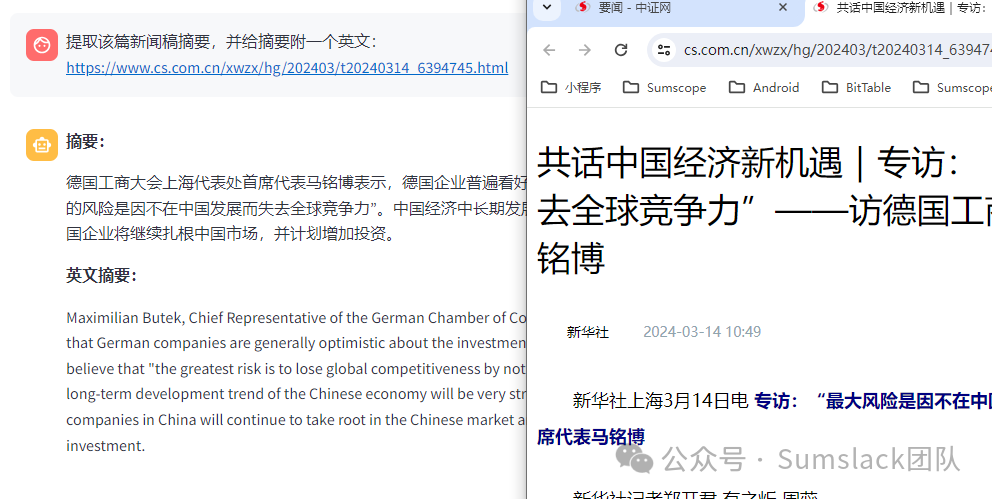
概述目前市面上大多爬虫都需要通过使用xpath规则抓取网页上的内容,不论是八爪鱼,神箭手或是其他,使用这类工具虽然可一定程度上做到可视化,但往往都需要一定门槛,同时,还存在致命缺点:三方网站改版,往往需要重写爬虫,那么,我们能否借助人工智能,实现根据我们需求的描述,抓到我们想要的内容呢?答案是肯定的。体验地址,或点击阅读原文直达:https://spider.sumslack.com 无需编码,直接描述爬虫即可,即可抓取数据。 设计思路思考:同一句话,其实交给语义检索和最后一步的问答是需要有所区分的,所以我们将网页需要抓取的描述部分用引号,引号里的内容就是基于语义的文档片段搜索,切分需要用HTML的分隔符,这里使用['<body', '<div', '<p', '<br', '<li', '<h1', '<h2', '<h3', '……', '<footer', '<nav', '<head', '<style', '<script', '<meta', '<title', ''],最后整句话交给LLM大模型时,只需要去掉所有URL地址即可。 案例展示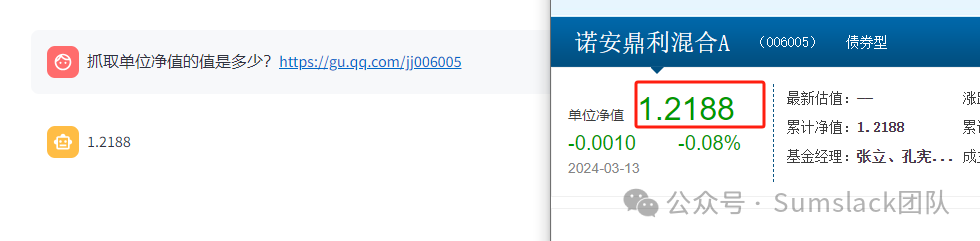


使用智能爬虫,让编写爬虫没有门槛
ingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;list-style: circle;color: rgb(63, 63, 63);">
ingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;letter-spacing: 0.1em;color: rgb(63, 63, 63);">欢迎关注我的公众号“Sumslack团队”,原创技术文章第一时间推送。
|










