概述语音合成(Text-to-Speech, TTS) 是指将输入文字合成为对应语音信号的功能,输出音频文件,最终由相关设备朗读出来。 SamBERT是达摩院语音实验室设计的一种基于Parallel结构的改良版TTS模型,它具有以下优点: - Backbone采用Self-Attention-Mechanism(SAM),提升模型建模能力。
- Encoder部分采用BERT进行初始化,引入更多文本信息,提升合成韵律。
- Variance Adaptor对音素级别的韵律(基频、能量、时长)轮廓进行粗粒度的预测,再通过decoder进行帧级别细粒度的建模;并在时长预测时考虑到其与基频、能量的关联信息,结合自回归结构,进一步提升韵律自然度.
- Decoder部分采用PNCA AR-Decoder,自然支持流式合成。
其架构图如下: 对于SamBERT更详细的技术介绍,可参考:文档[1]。本篇主要讲解模型实际的试用,对于技术原理给出的魔塔文档链接已经比较详细的介绍了。 对于SamBERT更详细的技术介绍,可参考:文档[1]。本篇主要讲解模型实际的试用,对于技术原理给出的魔塔文档链接已经比较详细的介绍了。 ModelScope试用在魔塔社区[2]上,提供了SamBERT的创空间和模型库: 这些创空间与模型库的文档非常详细,按照文档直接试用即可,每个魔塔新用户都有免费GPU服务器试用名额,可以玩转一下这些模型。 这些创空间与模型库的文档非常详细,按照文档直接试用即可,每个魔塔新用户都有免费GPU服务器试用名额,可以玩转一下这些模型。 我选择的场景是个人声音定制,选择创空间,然后录制声音,开始训练: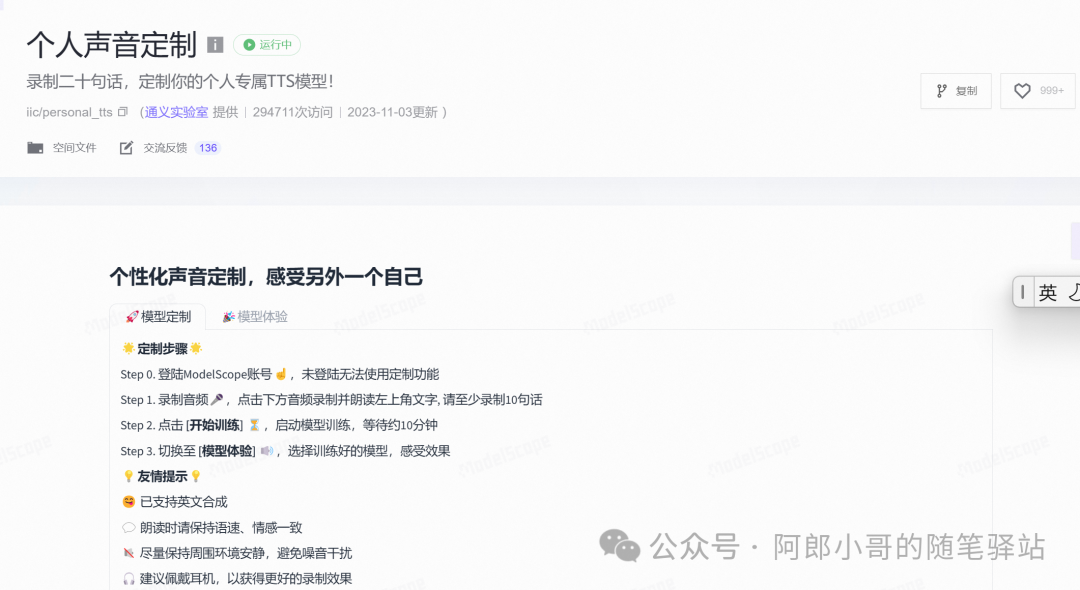  开始体验: 开始体验: 合成后,播放录音,效果不错,还是可以的。当然对于长上下文、方言等场景支持有一定的限制。 合成后,播放录音,效果不错,还是可以的。当然对于长上下文、方言等场景支持有一定的限制。 私有化搭建模型库:SambertHifigan个性化语音合成-中文-预训练-24k[3] 支持私有化部署,对于一些简单业务场景或是个人试玩,可以在服务器上搭建。该模型库介绍很详细,直接按流程就可以部署与微调。 写在结尾对于一些业务场景,如果要求不是很高,不是很复杂;我个人是强烈建议在ModelScope上找找开源模型,然后私有化部署。之前我个人还遇到一些场景也是在ModelScope找模型部署搭建使用。现在机器学习/深度学习/神经网络等人工智能算法应用将会越来越普及,我们也可以考虑将其纳入业务场景应用中,而不是只考虑业务场景的CRUD;闲余时间还可以阅读分析下原理。 | 









