|
检索增强生成(Retrieval-Augmented Generation,简称RAG)对于将外部知识整合到大型语言模型(Large Language Model,简称LLM)的输出中至关重要。虽然关于RAG的文献正在增长,但主要集中在系统性回顾和将新技术与其前身进行比较上,而在广泛的实验比较方面存在缺口。
为了解决这一缺口,广泛的比较了七种RAG技术在LLM输出中的应用,特别是在提高检索精度和答案相似性的影响:
- 包括句子窗口检索(Sentence-window retrieval)
- 文档摘要索引(Document summary index)
- 假设文档嵌入(Hypothetical Document Embedding, HyDE)
- 最大边际相关性(Maximal Marginal Relevance, MMR)
- Cohere重排序器(Cohere Re-ranker)

检索增强生成(Retrieval-Augmented Generation,简称RAG)系统内部工作流程的高层概述。这个流程图展示了系统如何处理用户查询,从数据库中检索相关文档,以及这些文档如何指导生成响应。

太长不看版本:
- MMR和Cohere重排序器在基准Naive RAG系统上没有表现出明显优势。
- 句子窗口检索在检索精度上表现最有效,尽管其在答案相似性上的表现不稳定。
- 使用了来自AI ArXiv集合的数据集,包含423篇研究论文。
- 采用了不同的数据块策略来创建向量数据库,以适应不同的检索方法。
- 为了减少LLM输出的变异性,每种RAG技术进行了10次运行。
- 使用Tonic Validate包/平台的指标来评估RAG技术的性能。
检索精度(Retrieval Precision)结论:
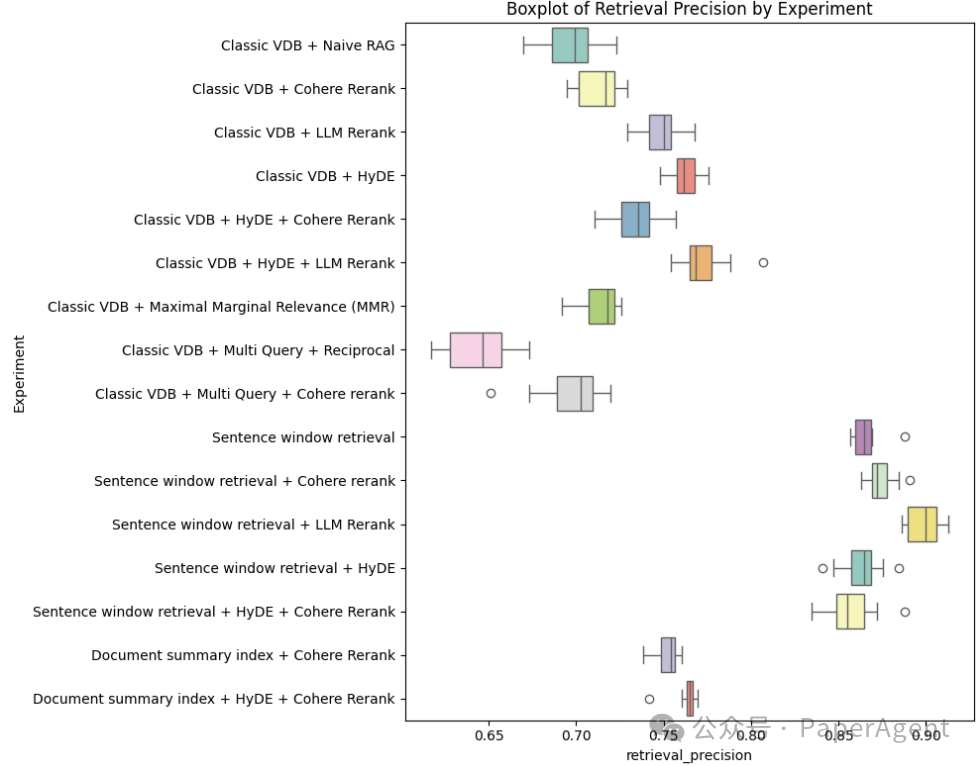
不同的RAG技术表现各异。句子窗口检索(Sentence Window Retrieval)方法表现出较高的中位数精度,但这并不直接与答案相似性的表现相关。 使用LLM重排序(LLM Rerank)和假设文档嵌入(HyDE)的技术显示出提高的精度,显著优于朴素RAG(Naive RAG)基线。相反,最大边际相关性(MMR)和Cohere重排序并没有表现出明显的优势,它们的中位数精度得分与基线相当或更低。 多查询方法相比朴素RAG表现出检索精度的下降,这需要进一步研究其适用性。 文档摘要索引(Document Summary Index)的表现与经典向量数据库(Classic VDB)的最佳设置相似,表明通过进一步增强,文档摘要技术将超过经典VDB。
实验中检索精度的箱形图。每个箱形图展示了不同RAG技术检索精度得分的范围和分布。较高的中位数值和更紧密的四分位数范围表明了更好的性能和一致性。
答案相似性(Answer Similarity)结论:
- 分析揭示了一些与检索精度观察结果一致和不一致的有趣模式。
- 对于经典向量数据库(Classic VDB)技术和文档摘要索引,检索精度和答案相似性之间存在显著的正相关关系,这表明当相关信息被准确检索时,可以导致与参考答案更相似的答案。
- 句子窗口检索在高检索精度和较低答案相似性得分之间显示出差异,这可能表明尽管该技术擅长识别相关段落,但它可能没有将这些信息转化为与参考答案在语义上并行的答案,可能是因为生成阶段没有完全利用检索到的上下文。
实验中检索精度的箱形图,每个箱形图展示了不同RAG技术检索精度得分的范围和分布。较高的中位数值和更紧密的四分位数范围表明了更好的性能和一致性。

ARAGOG: Advanced RAG Output Gradinghttps://arxiv.org/abs/2404.01037
推荐阅读
欢迎关注我的公众号“PaperAgent”,每天一篇大模型(LLM)文章来锻炼我们的思维,简单的例子,不简单的方法,提升自己。
| 









