|
什么是具象的高维向量空间?也许这是一个,在不同的平行空间里面,对不同的物体有各自的表示...

一、概述
大家都比较关心大语言模型的能力,但往往容易忽略其向量化(Embedding)的能力。在RAG应用中,对文本进行向量化后再计算向量相似度,如余弦相似度,是文本检索生成的基础和前置环节。如果向量不准确,必定会影响相似度计算,进一步影响招回和重排,甚至知识抽取等下游任务,影响甚大。因而我们需要认真来对待其结果,并且对其正确性和合理性进行评价。
本中对一些简单的文本对,使用不同的开源7B大语言模型来进行向量化,最终以其余弦相似度作为输出作为测试结果。语义的相似度如何进行评价很难达成一致意见,就下面的输出结果而言,可能人很难来评价其合理性。但我们可以通过比较不同大语言模型输出之间的差异,对比分析其文本向量化的能力、跨模型一致性和偏差。
先直接贴结果:
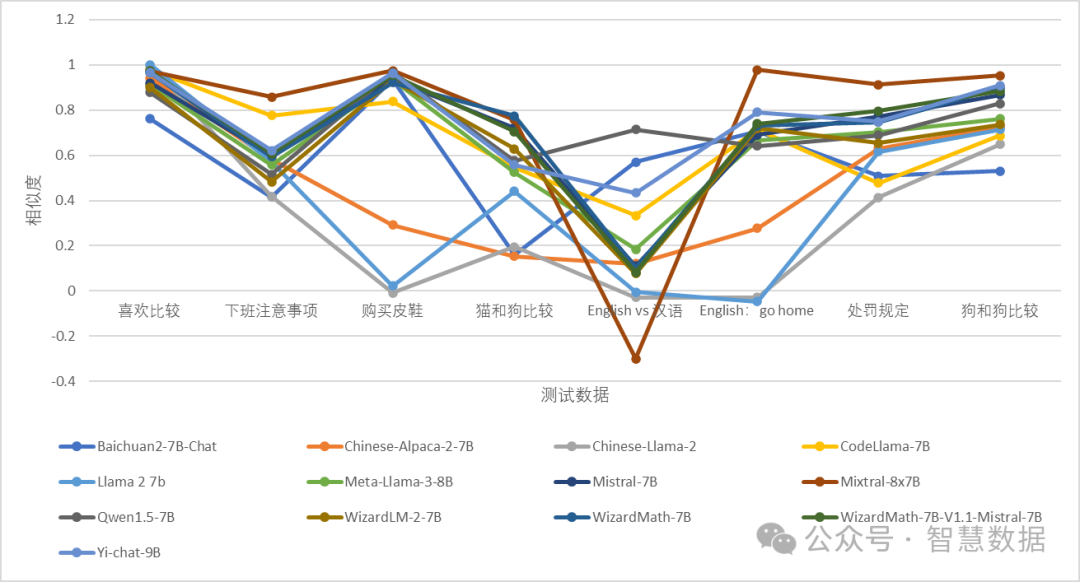
图:不同大语言模型对字符串对向量相似度比较
可以看出,不同的大语言模型,对同一对字符串向量相似度的理解存在较大的差异。我第一次看到结果时感觉有点惊讶。 我现在还没有理出头绪,但显然其中部分大语言模型的输出是不合理的,并且有的输出和其他大语言模型的输出存在较大的偏离,很显然,如果其中一个是正确的情况,那其他就是偏离甚至错误的情况。比如同一组词的相似度,不同大语言模型的输出范围包括从负值到0.7以上。
二、评测对象
三、测试方法
用LlamaSharp用,以Embedding模式加载大语言模型,实现文本向量化:
// Load weights into memoryvar parameters = new ModelParams(RootPath){ Seed = 1337u, EmbeddingMode = true};
var weight = LLamaWeights.LoadFromFile(parameters);var embedding = new LLamaEmbedder(weight, parameters);
四、评测结果
1、爱好比较
我喜欢看电视,不喜欢看电影。 我不喜欢看电视,也不喜欢看电影。
序号 |
大语言模型 |
余弦相似度 |
1 |
Mistral-7B |
0.9194595217704773 |
2 |
WizardMath-7B-V1.1-Mistral-7B |
0.9722315669059753 |
3 |
WizardMath-7B |
0.9659444093704224 |
4 |
WizardLM-2-7B |
0.9000769257545471 |
5 |
Meta-Llama-3-8B |
0.9120883941650391 |
6 |
Chinese-Llama-2 |
0.9997099041938782 |
7 |
Qwen1.5-7B |
0.8777709603309631 |
8 |
Llama 2 7b |
0.9997739791870117 |
9 |
Yi-chat-9B |
0.9656155109405518 |
10 |
Chinese-Alpaca-2-7B |
0.9418708682060242 |
11 |
Baichuan2-7B-Chat |
0.7609831690788269 |
12 |
CodeLlama-7B |
0.9805717468261719 |
13 |
Mixtral-8x7B |
0.9723657369613647 |

2、下班注意事项
序号 |
大语言模型 |
余弦相似度 |
1 |
Mistral-7B |
0.6006873250007629 |
2 |
Chinese-Alpaca-2-7B |
0.5809993743896484 |
3 |
Mixtral-8x7B |
0.8583651185035706 |
4 |
WizardMath-7B |
0.5944302678108215 |
5 |
Qwen1.5-7B |
0.5158098340034485 |
6 |
Meta-Llama-3-8B |
0.5567445755004883 |
7 |
WizardMath-7B-V1.1-Mistral-7B |
0.606997549533844 |
8 |
Llama 2 7b |
0.5725998282432556 |
9 |
Yi-chat-9B |
0.6222318410873413 |
10 |
CodeLlama-7B |
0.7767068147659302 |
11 |
Baichuan2-7B-Chat |
0.4148940443992615 |
12 |
Chinese-Llama-2 |
0.4173697233200073 |
13 |
WizardLM-2-7B |
0.4826260805130005 |

3、购买皮鞋
这只皮靴号码大了。那只号码合适。 这只皮靴号码不小,那只更合适。
序号 |
大语言模型 |
余弦相似度 |
1 |
WizardMath-7B-V1.1-Mistral-7B |
0.9549105763435364 |
2 |
Mixtral-8x7B |
0.9740864038467407 |
3 |
Qwen1.5-7B |
0.9682160019874573 |
4 |
CodeLlama-7B |
0.8389745354652405 |
5 |
Mistral-7B |
0.9343295693397522 |
6 |
Chinese-Alpaca-2-7B |
0.2915574610233307 |
7 |
Yi-chat-9B |
0.9639067053794861 |
8 |
WizardLM-2-7B |
0.9335297346115112 |
9 |
WizardMath-7B |
0.9227038621902466 |
10 |
Chinese-Llama-2 |
-0.008517207577824593 |
11 |
Baichuan2-7B-Chat |
0.9351896047592163 |
12 |
Meta-Llama-3-8B |
0.9342775344848633 |
13 |
Llama 2 7b |
0.021673066541552544 |

4、猫和狗比较
序号 |
大语言模型 |
余弦相似度 |
1 |
WizardLM-2-7B |
0.6294927000999451 |
2 |
Meta-Llama-3-8B |
0.5248777866363525 |
3 |
Baichuan2-7B-Chat |
0.16035179793834686 |
4 |
WizardMath-7B |
0.7749522924423218 |
5 |
WizardMath-7B-V1.1-Mistral-7B |
0.7058834433555603 |
6 |
Mistral-7B |
0.7224012017250061 |
7 |
Chinese-Alpaca-2-7B |
0.15339423716068268 |
8 |
CodeLlama-7B |
0.5445933938026428 |
9 |
Chinese-Llama-2 |
0.194538414478302 |
10 |
Qwen1.5-7B |
0.5761963129043579 |
11 |
Mixtral-8x7B |
0.7579318881034851 |
12 |
Yi-chat-9B |
0.5578252673149109 |
13 |
Llama 2 7b |
0.44038861989974976 |

5、Englishvs 汉语
序号 |
大语言模型 |
余弦相似度 |
1 |
CodeLlama-7B |
0.33356600999832153 |
2 |
Baichuan2-7B-Chat |
0.57098788022995 |
3 |
Chinese-Alpaca-2-7B |
0.11986920237541199 |
4 |
Mixtral-8x7B |
-0.30094829201698303 |
5 |
Llama 2 7b |
-0.005667471326887608 |
6 |
Mistral-7B |
0.10879462957382202 |
7 |
Meta-Llama-3-8B |
0.18513920903205872 |
8 |
WizardLM-2-7B |
0.0768003985285759 |
9 |
Qwen1.5-7B |
0.713830292224884 |
10 |
WizardMath-7B-V1.1-Mistral-7B |
0.08147571235895157 |
11 |
WizardMath-7B |
0.09978950768709183 |
12 |
Chinese-Llama-2 |
-0.029241781681776047 |
13 |
Yi-chat-9B |
0.43288084864616394 |

6、English:go home
序号 |
大语言模型 |
余弦相似度 |
1 |
Qwen1.5-7B |
0.6420629024505615 |
2 |
WizardLM-2-7B |
0.7205202579498291 |
3 |
Meta-Llama-3-8B |
0.6660025715827942 |
4 |
Chinese-Alpaca-2-7B |
0.27626731991767883 |
5 |
CodeLlama-7B |
0.7119967937469482 |
6 |
Yi-chat-9B |
0.791547954082489 |
7 |
WizardMath-7B |
0.7313649654388428 |
8 |
Llama 2 7b |
-0.04700035974383354 |
9 |
Mistral-7B |
0.6904579401016235 |
10 |
Baichuan2-7B-Chat |
0.7068948745727539 |
11 |
Mixtral-8x7B |
0.9776806831359863 |
12 |
Chinese-Llama-2 |
-0.027995778247714043 |
13 |
WizardMath-7B-V1.1-Mistral-7B |
0.740699052810669 |

7、处罚规定
序号 |
大语言模型 |
余弦相似度 |
1 |
Mixtral-8x7B |
0.9126697182655334 |
2 |
Mistral-7B |
0.7717455625534058 |
3 |
Baichuan2-7B-Chat |
0.5083956718444824 |
4 |
Yi-chat-9B |
0.7497902512550354 |
5 |
Qwen1.5-7B |
0.6885314583778381 |
6 |
CodeLlama-7B |
0.47839587926864624 |
7 |
Chinese-Alpaca-2-7B |
0.6295954585075378 |
8 |
WizardMath-7B |
0.746604323387146 |
9 |
Meta-Llama-3-8B |
0.7041338682174683 |
10 |
WizardMath-7B-V1.1-Mistral-7B |
0.7953561544418335 |
11 |
Chinese-Llama-2 |
0.414549857378006 |
12 |
WizardLM-2-7B |
0.6535733342170715 |
13 |
Llama 2 7b |
0.6160202026367188 |

8、狗和狗比较
序号 |
大语言模型 |
余弦相似度 |
1 |
Baichuan2-7B-Chat |
0.5302562713623047 |
2 |
WizardMath-7B-V1.1-Mistral-7B |
0.8843305110931396 |
3 |
Meta-Llama-3-8B |
0.7624377012252808 |
4 |
Yi-chat-9B |
0.9097429513931274 |
5 |
WizardLM-2-7B |
0.7355867624282837 |
6 |
CodeLlama-7B |
0.68620365858078 |
7 |
WizardMath-7B |
0.8989375829696655 |
8 |
Llama 2 7b |
0.7147634029388428 |
9 |
Mixtral-8x7B |
0.9531522989273071 |
10 |
Qwen1.5-7B |
0.8283199667930603 |
11 |
Mistral-7B |
0.8669305443763733 |
12 |
Chinese-Alpaca-2-7B |
0.7255567908287048 |
13 |
Chinese-Llama-2 |
0.6491625905036926 |

五、评测结果初步分析
不考虑文本内容,相似度数据汇总对比如下?
|
爱好比较 |
下班注意事项 |
购买皮鞋 |
猫和狗比较 |
English
vs 汉语 |
English:go
home |
处罚规定 |
狗和狗比较 |
| Baichuan2-7B-Chat |
0.760983169 |
0.414894044 |
0.935189605 |
0.160351798 |
0.57098788 |
0.706894875 |
0.508395672 |
0.530256271 |
| Chinese-Alpaca-2-7B |
0.941870868 |
0.580999374 |
0.291557461 |
0.153394237 |
0.119869202 |
0.27626732 |
0.629595459 |
0.725556791 |
| Chinese-Llama-2 |
0.999709904 |
0.417369723 |
-0.00851721 |
0.194538414 |
-0.02924178 |
-0.02799578 |
0.414549857 |
0.649162591 |
| CodeLlama-7B |
0.980571747 |
0.776706815 |
0.838974535 |
0.544593394 |
0.33356601 |
0.711996794 |
0.478395879 |
0.686203659 |
| Llama 2 7b |
0.999773979 |
0.572599828 |
0.021673067 |
0.44038862 |
-0.00566747 |
-0.04700036 |
0.616020203 |
0.714763403 |
| Meta-Llama-3-8B |
0.912088394 |
0.556744576 |
0.934277534 |
0.524877787 |
0.185139209 |
0.666002572 |
0.704133868 |
0.762437701 |
| Mistral-7B |
0.919459522 |
0.600687325 |
0.934329569 |
0.722401202 |
0.10879463 |
0.69045794 |
0.771745563 |
0.866930544 |
| Mixtral-8x7B |
0.972365737 |
0.858365119 |
0.974086404 |
0.757931888 |
-0.30094829 |
0.977680683 |
0.912669718 |
0.953152299 |
| Qwen1.5-7B |
0.87777096 |
0.515809834 |
0.968216002 |
0.576196313 |
0.713830292 |
0.642062902 |
0.688531458 |
0.828319967 |
| WizardLM-2-7B |
0.900076926 |
0.482626081 |
0.933529735 |
0.6294927 |
0.076800399 |
0.720520258 |
0.653573334 |
0.735586762 |
| WizardMath-7B |
0.965944409 |
0.594430268 |
0.922703862 |
0.774952292 |
0.099789508 |
0.731364965 |
0.746604323 |
0.898937583 |
| WizardMath-7B-V1.1-Mistral-7B |
0.972231567 |
0.60699755 |
0.954910576 |
0.705883443 |
0.081475712 |
0.740699053 |
0.795356154 |
0.884330511 |
| Yi-chat-9B |
0.965615511 |
0.622231841 |
0.963906705 |
0.557825267 |
0.432880849 |
0.791547954 |
0.749790251 |
0.909742951 |
初步分析,可以发现几个情况:
对于同一个字符串对,不同大语言模型的向量化后结果的余弦相似度存在较大的差异,个别模型明显不稳定,不合群; 在将中文和英文进行余弦相似度比较时,结果差异更大,并且在值空间中基本呈均匀分布,是否表现出其跨语言能力存在巨大差异?是否需要翻译后再进行向量相似度计算? 如果波动很大的不同值都具有合理性,那在实战中我们应该采取多个大语言模型并行进行向量化和向量招回的策略吗?将词的向量加到一起得到句子的向量,这种方法合理吗(比如对否定词如何进行准确的向量化语义表达)? 大语言模型为什么在向量化的能力有如此大的差距?是因为其中文能力不够强,或者对一些特殊的词组没有识别能力,从而影响到其准确对文本进行向量化的能力吗? Llama 2在添加中文语料后,Chinese-Llama-2对相同字符串对的向量相似度的理解上也存在较大差异。这种差异可否作为模型退化的指标? 向量相似度和语义相似度应该存在比较大的差异,应该如何减少这种差异?还是完全利用大语言模型的语义理解能力来生成内容? 如果不同的文本存在确定的语义,是否经过不同的大语言模型向量化后应该有相似的表示?差异的来源在哪? 对不同大语言模型的输出结果,可以画出一个重叠度比较高的区域,见下图红色半透明区域。在这个区域内有大约5个模型相对稳定,各个字符串对的输出比较接近。为什么会出现这种情况?是因为这些大语言模型的能力比较高,已经进化到了一定的程度,还是因为他们在训练的语料上相似?

希望能给你启发。
你是什么观点?你觉得这些测试数据中还隐含哪些信息?欢迎分享。
| 









