ingFang SC", "Microsoft YaHei", "Source Han Sans SC", "Noto Sans CJK SC", "WenQuanYi Micro Hei", sans-serif;margin-bottom: calc(1.16667em);clear: left;font-synthesis: style;color: rgb(18, 18, 18);text-align: start;white-space: normal;background-color: rgb(255, 255, 255);">1、前言ingFang SC", "Microsoft YaHei", "Source Han Sans SC", "Noto Sans CJK SC", "WenQuanYi Micro Hei", sans-serif;font-size: medium;text-align: start;white-space: normal;background-color: rgb(255, 255, 255);">本次分享一篇关于三元组关系抽取的paper,论文来自2022年EMNLP会议,论文题目为:<UniRel: Unified Representation and Interaction for Joint Relational Triple Extraction >。论文核心想法是:在抽取三元组(s,r,o)任务中,将实体和关系一起进行表征和交互,抽取方式是仍是采用目前主流的基于table filling的方式,只是在预测时,将三元组学习目标拆分三种交互关系预测,分别为实体之间的关系(s,o),实体跟关系类型的关系(s|o,r),关系类型跟实体的关系(r,s|o),如下图所示。ingFang SC", "Microsoft YaHei", "Source Han Sans SC", "Noto Sans CJK SC", "WenQuanYi Micro Hei", sans-serif;font-size: medium;text-align: center;white-space: normal;background-color: rgb(255, 255, 255);"> ingFang SC", "Microsoft YaHei", "Source Han Sans SC", "Noto Sans CJK SC", "WenQuanYi Micro Hei", sans-serif;margin-top: calc(2.33333em);margin-bottom: calc(1.16667em);clear: left;font-synthesis: style;color: rgb(18, 18, 18);text-align: start;white-space: normal;background-color: rgb(255, 255, 255);">2、模型 ingFang SC", "Microsoft YaHei", "Source Han Sans SC", "Noto Sans CJK SC", "WenQuanYi Micro Hei", sans-serif;margin-top: calc(2.33333em);margin-bottom: calc(1.16667em);clear: left;font-synthesis: style;color: rgb(18, 18, 18);text-align: start;white-space: normal;background-color: rgb(255, 255, 255);">2、模型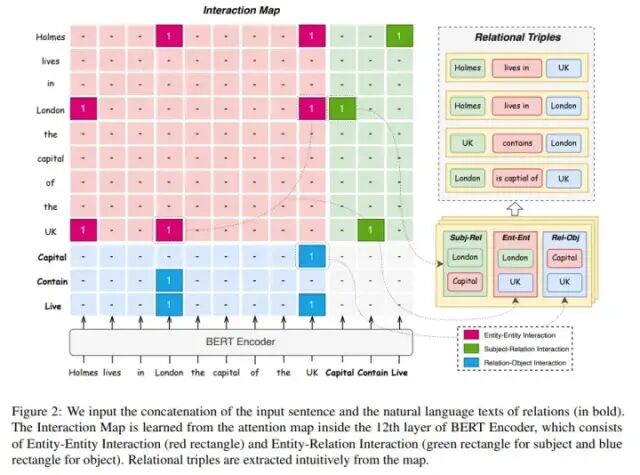
上图为模型图,其大致意思为将文本和关系类别拼接一起作为输入序列,然后形成一个表征table矩阵,table矩阵中每个位置(单元格)可以表示是否有定义的关系(论文中成为Interaction Map),若有为1,没有为0;这样预测任务变成一个表格填充的2分类任务,然后解码时根据表格预测的结果+规则即可解析出三元组。 ingFang SC", "Microsoft YaHei", "Source Han Sans SC", "Noto Sans CJK SC", "WenQuanYi Micro Hei", sans-serif;margin-top: calc(2.33333em);margin-bottom: calc(1.16667em);clear: left;font-synthesis: style;color: rgb(18, 18, 18);text-align: start;white-space: normal;background-color: rgb(255, 255, 255);">2.1 三元组关系抽取任务定义给定一个输入文本 为序列长度,抽取任务即是从文本中识别所有的关系三元组 为序列长度,抽取任务即是从文本中识别所有的关系三元组 其中 其中 为三元组数量, 为三元组数量, 分别为第 分别为第 组对应的主实体,关系,客实体。由主实体和客实体组成一个实体集合 组对应的主实体,关系,客实体。由主实体和客实体组成一个实体集合 ,关系集合为 ,关系集合为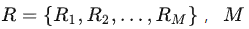 为关系类型数量。 为关系类型数量。 ingFang SC", "Microsoft YaHei", "Source Han Sans SC", "Noto Sans CJK SC", "WenQuanYi Micro Hei", sans-serif;margin-top: calc(1.90909em);margin-bottom: calc(1.27273em);clear: left;font-synthesis: style;color: rgb(18, 18, 18);text-align: start;white-space: normal;background-color: rgb(255, 255, 255);">2.2 表征学习ingFang SC", "Microsoft YaHei", "Source Han Sans SC", "Noto Sans CJK SC", "WenQuanYi Micro Hei", sans-serif;font-size: medium;text-align: start;white-space: normal;background-color: rgb(255, 255, 255);">首先,所有关系类型的名称的都用一个核心词来代表,如关系“/business/company/founders”用“founders”来表示,“is captial of”用“captial”来表示;接着将预测文本跟所有关系类别的核心词进行拼接,形成新的序列,输入到表征模型,如bert,进行表征学习:ingFang SC", "Microsoft YaHei", "Source Han Sans SC", "Noto Sans CJK SC", "WenQuanYi Micro Hei", sans-serif;font-size: medium;text-align: center;white-space: normal;background-color: rgb(255, 255, 255);"> ingFang SC", "Microsoft YaHei", "Source Han Sans SC", "Noto Sans CJK SC", "WenQuanYi Micro Hei", sans-serif;margin-top: calc(1.90909em);margin-bottom: calc(1.27273em);clear: left;font-synthesis: style;color: rgb(18, 18, 18);text-align: start;white-space: normal;background-color: rgb(255, 255, 255);">2.3 交互关系定义ingFang SC", "Microsoft YaHei", "Source Han Sans SC", "Noto Sans CJK SC", "WenQuanYi Micro Hei", sans-serif;font-size: medium;text-align: start;white-space: normal;background-color: rgb(255, 255, 255);">文中是将三元组关系(s,r,o)拆成三种子关系来表示和预测学习,首先是实体之间关系定义: ingFang SC", "Microsoft YaHei", "Source Han Sans SC", "Noto Sans CJK SC", "WenQuanYi Micro Hei", sans-serif;margin-top: calc(1.90909em);margin-bottom: calc(1.27273em);clear: left;font-synthesis: style;color: rgb(18, 18, 18);text-align: start;white-space: normal;background-color: rgb(255, 255, 255);">2.3 交互关系定义ingFang SC", "Microsoft YaHei", "Source Han Sans SC", "Noto Sans CJK SC", "WenQuanYi Micro Hei", sans-serif;font-size: medium;text-align: start;white-space: normal;background-color: rgb(255, 255, 255);">文中是将三元组关系(s,r,o)拆成三种子关系来表示和预测学习,首先是实体之间关系定义: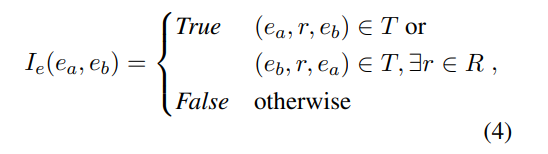
用指示函数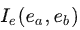 来表示两个实体是否存在关系,若存在就是为1,否则为0;考虑到实体关系对称性, 来表示两个实体是否存在关系,若存在就是为1,否则为0;考虑到实体关系对称性,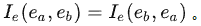 其次是实体与关系的定义,文中定义两种类型: 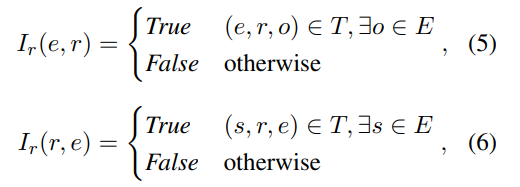
用 表示主实体e与关系类型r是否存在关系,用 表示主实体e与关系类型r是否存在关系,用 表示客实体e与关系类型r是否存在关系。 表示客实体e与关系类型r是否存在关系。 上述就是文中定义的三种交互关系,结合模型图示例,很好理解。对比其他表格填充方法来说,论文的不同点在于:1)让关系label参与了表征;2)预测认为转变三个子类型,但本质还是单元格二分类。 2.3 交互关系预测上述定义的交互关系可以看着是优化目标的真实值,那对应的预测值是怎样。文中是取bert表征最后一层多头注意力机制中的Q、K矩阵来求和得到交互表(Interaction Map),再加一个sigmoid函数即可: 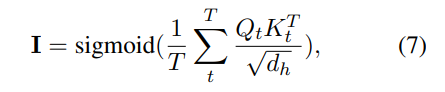
其中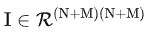 ,即为预测的表格,T为多头的数量。 ,即为预测的表格,T为多头的数量。 2.4 优化函数优化的函数就是一个二分类交叉熵: 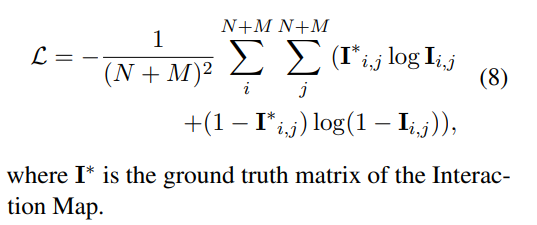
3、实验结果就说下论文提出的方法(UniRel)的主要实验结果。实验在NYT和WebGLG上做的,相对来说实验数据集少了,结果如下: 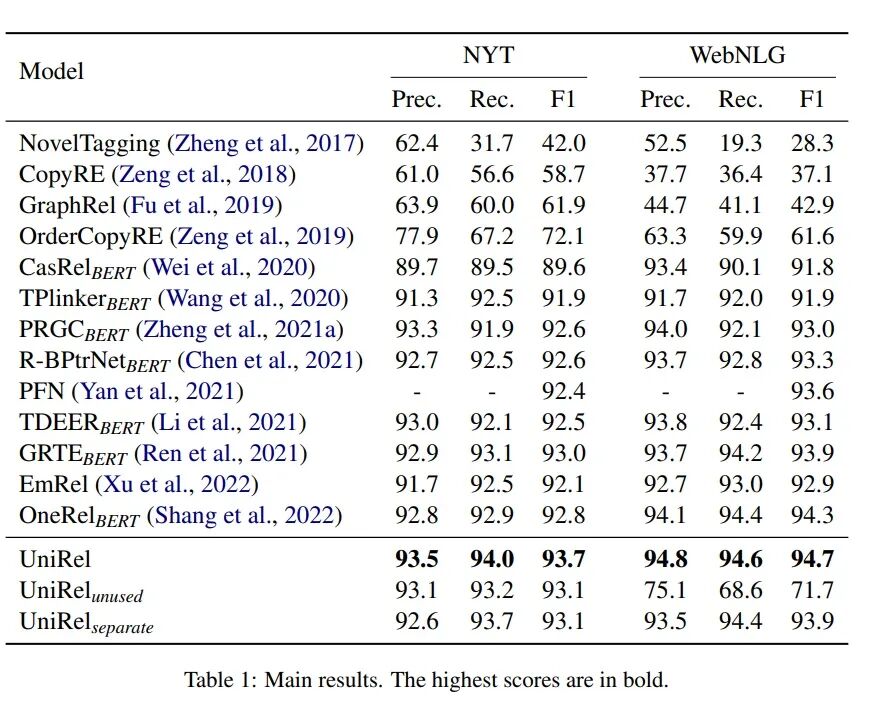
对比的都是我们常见关系抽取模型,可以看出,1)UniRel模型在NYT数据集提升比较明显,F1值有近1个点的提升;在WebNLG上,F1值有0.4个点的提升;2)UiRel_unused表示用bert 词表中[unused]来代替关系类别的核心词,可以看出在WebNLG中影响非常大,说明有效的去表征关系类型的语义信息很重要;3)UniRel_separate表示文本和关系label分开来表征,不拼接在一起,预测的效果表差,说明拼接在一起有交互促进的作用。 在此有几个想法:1)文中没有对比很熟知的GPLinker模型;2)既然关系类型的语义信息很重要,文中只用一个单词来代表,如果用多个单词来代表,是不是效果会更好;3)如WebNLG数据集有171种关系类型,相当于原始的输入序列长度增加170+,这样导致预测的表格更为稀疏; 4、结语本次分享一篇比较新的关系抽取方法,其新颖之处是让关系类型参与表征和交互学习,起到促进提升的作用。论文开源代码:https://github.com/wtangdev/UniRel,有兴趣可在自己的业务场景下测试看看效果。
|










