前言Stability AI 作为开源图像生成领域的领军者,不断突破技术边界,6月12日发布了其最新一代文本到图像生成模型——Stable Diffusion 3。这次发布的是 Stable Diffusion 3 的 Medium 模型,拥有 20 亿参数,在图像质量、文本遵循度和排版方面都展现出超越现有模型的强大实力。Stability AI 未来还将开源 40 亿和 80 亿参数的版本,进一步提升模型能力,满足不同用户的需求。 
技术特点Stable Diffusion 3 的核心技术是全新的 多模态扩散Transformer (MMDiT) 架构。与以往版本相比,MMDiT 采用独立的权重集分别处理图像和语言表示,从而提升了模型对文本的理解能力,并改善了文本生成效果: 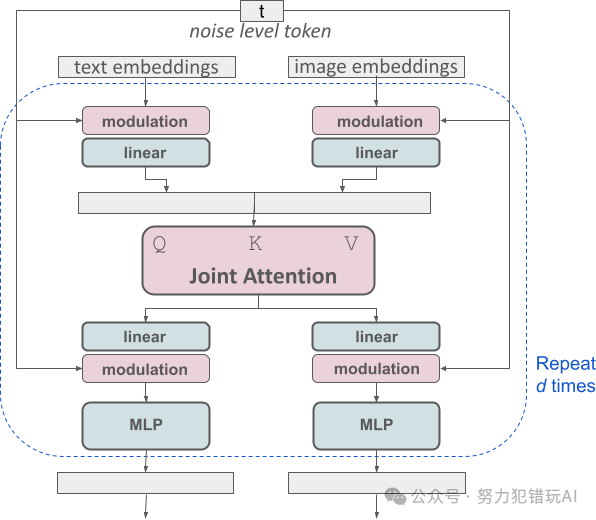
Stable Diffusion 3 采用了一种新颖的 修正流 (Rectified Flow, RF) 公式,通过将数据和噪声在训练过程中连接成线性轨迹,实现了更直接的推断路径,从而使用更少的采样步骤就能生成高质量的图像。此外,Stable Diffusion 3 还引入了新的 轨迹采样调度,对轨迹中间部分进行加权,从而提高模型在训练过程中的预测能力。 性能表现Stability AI 对 Stable Diffusion 3 进行了大量测试,并将生成结果与包括 DALL·E 3、Midjourney v6、Ideogram v1 以及其他开源模型在内的多个模型进行了比较。结果表明,Stable Diffusion 3 在以下方面展现出优势: 文本遵循度: Stable Diffusion 3 在文本遵循度方面表现出色,能够更准确地将文本内容融入到图像中,生成的图像更符合文本描述。 图像质量: Stable Diffusion 3 生成的图像具有更高的视觉质量,细节更丰富,更具艺术性。 排版能力: Stable Diffusion 3 在排版方面也展现出强大的能力,能够根据文本信息生成更美观、更易读的图像。
在实际应用中,Stable Diffusion 3 的 80 亿参数可以在 RTX 4090 显卡上运行,并能够在 34 秒内生成分辨率为 1024x1024 的图像。为了降低硬件门槛,Stability AI 将发布多个版本的 Stable Diffusion 3,包括 40 亿和 80 亿参数的模型,以满足不同用户的需求。 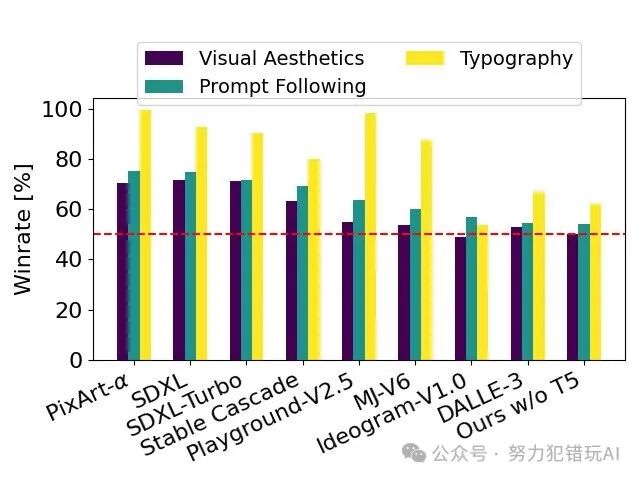
应用场景Stable Diffusion 3 具有广泛的应用场景,能够为各种需要图像生成的应用提供强大的支持: 艺术创作: 艺术家可以使用 Stable Diffusion 3 来生成各种风格的图像,帮助他们进行创作和实验。 广告设计: 广告设计师可以使用 Stable Diffusion 3 来快速生成符合创意要求的广告图片,提升广告效果。 游戏开发: 游戏开发者可以使用 Stable Diffusion 3 来生成游戏场景、人物、道具等图像,提高游戏的美观度和沉浸感。 影视制作: 影视制作人员可以使用 Stable Diffusion 3 来生成电影、电视剧等作品中的场景、道具等图像,提升作品的视觉效果。

总结Stable Diffusion 3 的发布,标志着文本到图像生成技术取得了新的突破。其全新的多模态扩散Transformer架构、卓越的生成效果以及广泛的应用场景,使其成为目前最值得期待的开源图像生成模型之一。相信随着技术的不断发展,Stable Diffusion 3 将为图像生成领域带来更多可能性,并为各个行业带来更大的价值。 | 









