TabPedia是一个表格理解模型,包括两个训练阶段:预训练和微调。预训练阶段旨在将视觉特征与大型语言模型对齐,微调阶段则专注于视觉表格感知。
模型架构
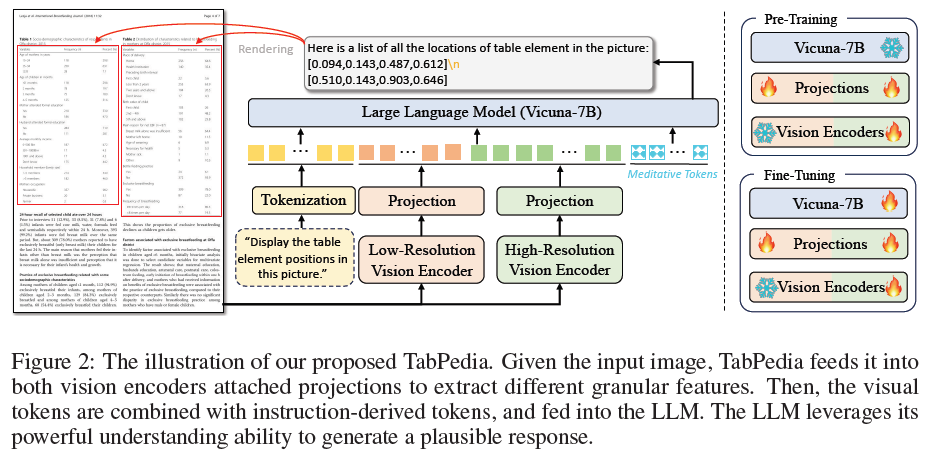
高分辨率视觉编码器。高分辨率图像对于确保LLM能够掌握丰富的视觉信息至关重要。本文采用Swin-B对输入图像的高分辨率格式进行编码。给定输入的RGB图像I,我们首先将其调整为预定义的高分辨率尺度H×W,记为Ih。默认情况下,H和W分别设置为2560和1920。我们在缩放过程中保持了宽高比,以防止表内容和结构的失真。然后,将图像输入到vanilla Swin Transformer中,以获得按1/32倍下采样的特征映射Vh,每个token具有1024维。
低分辨率视觉编码器。为了保持整体布局信息,原始图像也被调整为低分辨率图像,记为Il。选择预训练的CLIP视觉编码器ViTL/14对224×224的低分辨率图像进行编码。输出序列Vl由256个标记组成,每个标记具有512维。
预测。对于高分辨率特征图Vh,由于输入文本长度的限制,我们采用了一个内核大小为3、步长为2的2D卷积层,然后将其展平为64×64 token,记为Vˆh。对于低分辨率视觉特征Vl,采用一个线性层来投影视觉标记,记为Vˆl。
概念协同。我们利用Vicuna-7B作为LLM来生成其响应。考虑到表感知和理解任务的差异性,引入meditative token来实现LLM的概念协同,自适应地使不同区域的视觉token能够理解特定任务问题的意图。最后,构造整个输入序列为X=[Q,<IMG_S>;Vˆl;<IMG_SEP>;Vˆh;<IMG_E>;M]。<IMG_S>、<IMG_E>和<IMG_SEP>是可学习的特殊标记,它们分别表示视觉标记的开始和结束,以及不同分辨率标记的分离。
目标。由于TabPedia像其他LLM一样被训练为预测下一个token,因此它通过在训练时最大化预测损失的可能性来进行优化。
预训练
预训练过程包括文本检测、识别、定位、长文本阅读和图像字幕等任务,以使视觉编码器能够有效地感知文本和视觉信息。预训练过程中,我们同时优化高分辨率视觉编码器和两个投影器,同时冻结大型语言模型和低分辨率视觉编码器。
表格感知微调
通过预训练,TabPedia可以理解各种文档图像的文本和结构,但无法按照指示执行不同的表格理解任务。为了增强模型的指示遵循能力,我们首先构建了一个大规模的视觉表格理解数据集。基于这个数据集,我们引入了四个与表格相关的任务,即TD、TSR、TQ和TQA,以同时培养感知和理解能力。在这个阶段,我们进一步解冻LLM并对整个框架进行微调,除了低分辨率视觉编码器。
本文构建的数据集包括五个公共数据集。为了确保指令的多样性,使用GPT3.5生成了多个指令。同时提供了每个表格任务的用户问题示例。

表格检测(TD)旨在检测文档图像中所有表格的位置。以往的方法主要使用DETR或R-CNN的变体来预测大量重叠的边界框,需要复杂的后处理(如非极大值抑制)来生成最终结果。相比之下,我们采用LLM直接生成实例表格的位置,格式为“[x1,y1,x2,y2]”,其中x1,y1,x2,y2表示相应边界框左上角和右下角的归一化坐标。此外,为了便于检测多个表格的结果,我们使用特殊符号“\n”在输出响应中分割多个表格位置。我们使用PubTab1M-Det执行TD任务,其中的图像来自具有不同比例和旋转类型的表格的PDF文档。
表格结构识别(TSR)是一个用于解析表格结构的任务,主要针对HTML和Markdown两种文本序列来表示表格。HTML可以表示各种类型的表格,但包含大量的标记语法,导致输出响应过长。相比之下,Markdown更简洁,但无法表示跨多行或多列的单元格。为了权衡输出的简洁性和表格解析的完整性,我们提出了一种基于检测格式的规范表格结构表示。我们选择了PubTab1M-Str、FinTabNet和PubTabNet这三个数据集来支持TSR任务。
表格查询(TQ)任务与TSR任务不同,它直接从原始文档图像中解析表格,基于给定的表格位置。这个任务更具挑战性,因为表格的分辨率降低,周围其他文档内容的干扰。
表格问答(TQA)旨在通过表格理解和推理提供精确的答案。我们生成了大量的TQA数据,通过使用Gemini Pro的多模态理解能力,从FinTabNet和PubTab1M中的部分图像中生成。
为了更好地评估各种模型在真实世界表格图像上的TQA性能,我们基于FinTabNet和PubTab1M的测试集构建了一个复杂的TQA数据集(ComTQA)。与WTQ和TabFact相比,ComTQA具有更具挑战性的问题,例如多个答案、数学计算和逻辑推理。总共,我们通过专家注释从大约1.5k个图像中注释了约9k个高质量的问答对。
实现细节
参数设置。meditative token的数量设置为256。文本序列的最大长度设置为4000。我们采用具有单周期学习率策略的余弦调度。在16块A100上进行训练。
数据集。为了全面评估TabPedia的性能,为每个任务使用多个基准。TD任务选择PubTab1M-Det,TSR任务选择FinTabNet、PubTabNet和PubTab1M-Str,对于TQ任务选择PubTab1M-Syn,对于TQA任务选择WTQ 、TabFact和我们的ComTQA。
评价指标。对于TD任务评估指标包括precision, recall和f1-score IoU@0.75。对于TSR和TQ任务,使用基于结构树编辑距离的相似性(S-TEDS)、GriTS指标。对于TQA任务,我们采用准确性度量标准,如果模型生成的响应包含ground truth中存在的字符串,则判断其正确。
定量结果
在表格检测、表格结构识别、表格问题回答等任务上,TabPedia都表现出了优异的性能,甚至在处理真实世界的表格时也能取得很好的效果。相比于其他方法,TabPedia的优势在于它能够直接生成独立的表格实例位置,无需进行额外的后处理操作。这使得TabPedia能够更好地处理复杂的表格理解任务。










