随着人工智能和机器学习技术的快速发展,软件开发行业正经历巨大变革。代码助手工具通过代码生成、智能补全、代码问答等功能,显著提升开发效率并减少代码错误,逐渐成为开发流程中不可或缺的组成部分。
为全面评估代码助手工具在实际开发中的性能,我们设计了多维度的专业场景测评,涵盖网页UI设计、网络爬虫、数据分析与可视化,扩展至系统开发、模型部署和分布式系统等多个技术领域。
本文将详细介绍我们为代码助手工具设计的测评基准SuperCLUE-Coder,包括构成、方法和应用场景,旨在提供一套科学严谨的评价体系,助力代码助手工具的研发和在各专业领域的应用推广。 排行榜地址:www.SuperCLUEai.com 官网地址:www.CLUEbenchmarks.com 1. 中文原生代码生成能力评估 立足于为中文编程环境提供基础评测的设施,测评项目中的代码输入和生成都是原生中文,不是英文或其翻译版本;充分考虑国内代码生成平台的行业特点与应用场景,从国内编程者的实际需求出发,致力于打造适合中国语义环境的代码生成测评指标。 2. 实际编程场景应用潜力评估 该体系还深入探讨了代码生成平台在实际编程场景中的综合能力,包括Web开发、数据分析、网络爬虫等常见场景。通过模拟实际编程中的任务和问题,可以测试平台对具体任务的处理逻辑和处理结果的准确性,从而评估其在不同场景下的适用性和实用性。这种以实际应用为导向的测评方式,有助于确保代码生成平台能够更好地满足开发者的需求和期望。 3. 发展趋势与创新性测评标准 该测评体系紧密结合了代码生成领域的现状与发展趋势,全面评估代码生成平台在多种编程语言和环境下的表现。具体来说,该测评体系不仅考察代码生成平台基础的代码准确性和质量,还提出了对代码可读性、可维护性及扩展性的测评。这样的测评体系能为代码生成技术的进一步发展提供有力的支持。 二、测评体系 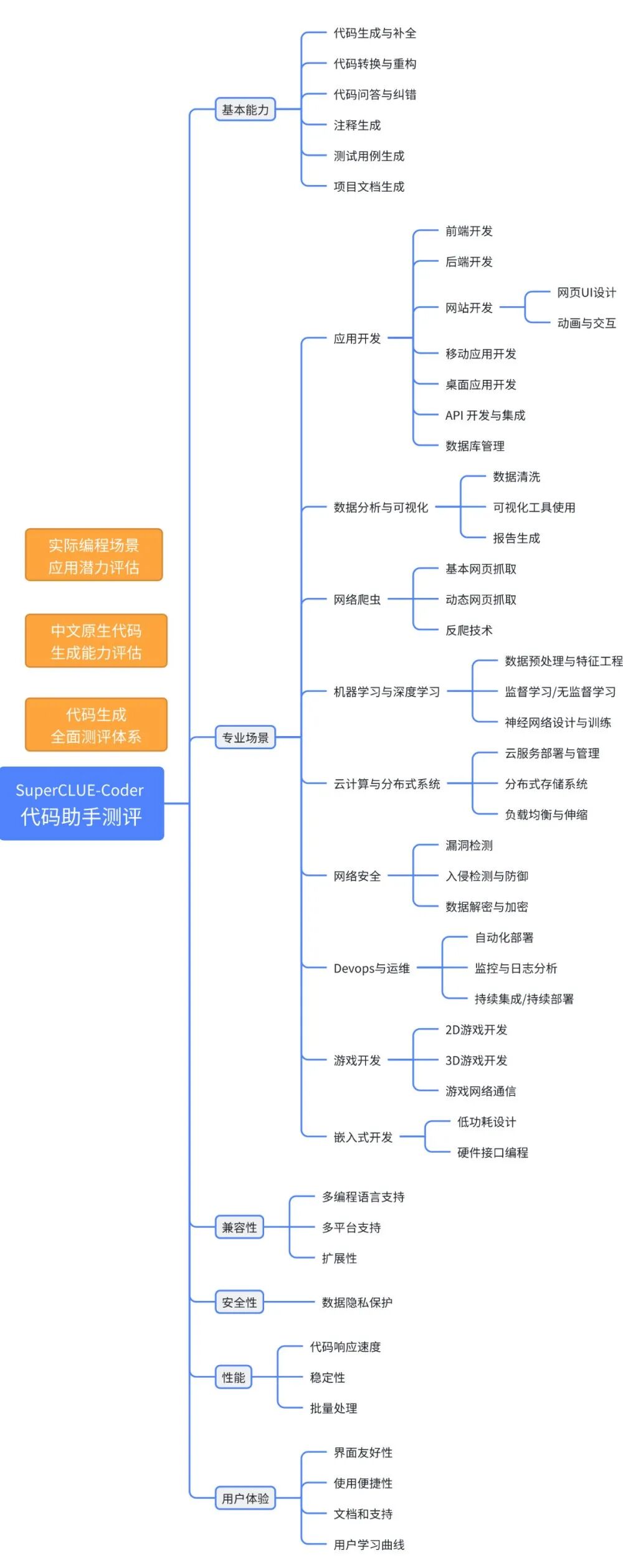
- 代码生成:根据用户的描述或需求,生成高质量的代码,满足指定的功能需求。
- 示例: 用户输入“生成一个计算两个数之和的函数”,系统生成相应的函数代码。
- 代码问答:快速准确地回答用户关于代码的问题,包括语法、功能和错误解释等。
- 示例:用户输入“为什么这段Python代码会报错?”
系统回复:“你的代码缺少结束引号,应该改成print("Hello World")。” -- -- - 代码理解:理解和解释用户提供的代码,包括其功能和工作原理。
- 示例:用户输入一段代码def multiply(a, b): return a * b
- 代码纠错:识别代码中的错误并提供修正建议,确保代码的正确性和稳定性。
示例: 用户在编写函数名时,系统能实时建议补全常用函数名,帮助用户快速完成代码。 -- - 注释生成:为用户提供的代码生成相应的注释,帮助用户理解代码的功能和逻辑。
示例:用户输入一段没有注释的代码,系统生成详细的代码注释,解释每一行代码的作用。- 测试用例生成:为用户提供的代码生成相应的测试用例,以验证代码的正确性和稳定性。
示例:用户输入需求和一段函数代码,系统生成相应的测试用例,验证函数在各种输入下的输出是否正确。- 代码修改记录生成:为代码的修改过程生成详细的记录,帮助用户追踪和管理代码变更。
- 数据分析/可视化:对用户提供的数据进行分析并生成相应的可视化图表,帮助用户理解数据。
系统生成:分析报告和趋势图,展示各季度的销售情况。 -- 示例:用户提供一个电商网站的URL,系统生成网络爬虫代码,自动提取商品名称和价格。- 网页UI设计:根据用户提供的需求生成美观且兼容的网页UI代码,提升用户体验
示例: 用户描述需要一个带导航栏和内容区的网页布局,系统生成HTML和CSS代码。- 游戏开发:生成游戏开发所需的代码,支持多种游戏开发平台和引擎。
示例: 用户输入简单的游戏需求,系统生成基础的游戏开发代码,包括游戏循环和基本交互。- 网络安全攻防:检测和分析网络流量中的异常行为,提供安全防护措施,确保系统和数据的安全。
示例: 用户提供一段网络流量数据,系统识别出异常流量并提供防护建议。- Devops与运维:生成自动化运维脚本,帮助用户实现持续集成和持续部署,提高运维效率。
示例: 用户输入部署需求,系统生成相应的CI/CD脚本,实现自动化部署。 - 图像处理/处理:根据用户提供的图像或描述进行处理或生成新的图像,满足用户的图像处理需求。
示例: 用户上传一张图片并请求模糊处理,系统生成图像读取以及模糊处理函数。- 模型训练与部署:根据用户提供的数据生成并训练机器学习模型,并提供相应的部署代码。
示例:用户上传一份数据集,系统生成并训练机器学习模型,并提供模型部署代码。- 嵌入式开发:生成符合嵌入式设备要求的代码,满足嵌入式开发的需求。
示例: 用户输入设备需求,系统生成相应的嵌入式控制代码。维度三:兼容性 维度四:安全性 - 数据隐私保护:采取严格的数据隐私保护措施,确保用户数据的安全和保密。
- 代码响应速度:快速响应用户的请求,确保高效的交互体验。
稳定性:保持高稳定性,避免频繁的系统崩溃或故障。 - 批量处理:能够高效地处理大量用户请求,保持高效和准确的处理能力。
- 界面友好性:界面设计简洁、直观,提升用户的操作体验和满意度。用户在使用过程中,能够轻松找到所需功能,界面布局合理,操作便捷。
使用便捷性:具备简便易用的特点,用户能快速上手并高效操作。 文档和支持:应提供详细的文档和技术支持,帮助用户解决使用中的问题。 用户学习曲线:设计合理的学习路径,帮助用户在短时间内掌握系统的使用方法 - 用户通过在线教程和操作指南,能够快速掌握系统的基本操作和主要功能。
构建专用测评集,对每个维度进行细粒度评估并提供详细的反馈信息。
测评集构建 通过细化和调研具体开发场景需求,构建不同测试维度的中文测评数据,确保测评数据能够全面覆盖测评体系。评估流程 自动化测试分数:利用大模型(如,GPT-4o)根据预先设定的评价标准自动化测试,对系统的各项功能进行评估并生成分数。大模型可以通过模拟真实使用场景,快速、准确地对系统性能进行多维度测量。
四、测评示例 场景描述: 用户希望通过代码助手模型生成一段代码,该代码可以调用 ChatGPT API,并利用它返回的结果生成一个爬取中国大学排名信息的脚本。
用户对代码助手模型发出如下指令:帮我生成一段代码让我可以调用 ChatGPT 的 API,并利用它返回一段爬取中国大学排名网址信息的脚本,url:ingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;font-size: 15px;letter-spacing: 0.034em;">https://www.usnews.com/education/best-global-universities/chinaingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;letter-spacing: 0.034em;">模型输出和评估: 模型1-生成的代码:
importopenai#设置API密钥openai.api_key='YOUR_API_KEY'#定义请求数据prompt="帮我生成一段Python代码,用于爬取中国大学排名信息的脚本,url:https://www.usnews.com/education/best-global-universities/china"response=openai.Completion.create(engine="text-davinci-004",prompt=prompt,max_tokens=200)#打印ChatGPT的响应print(response.choices[0].text.strip())importrequestsfrombs4importBeautifulSoup#目标网址url='https://www.usnews.com/education/best-global-universities/china'#发送请求response=requests.get(url)response.encoding='utf-8'#解析HTML内容soup=BeautifulSoup(response.text,'html.parser')#提取排名信息rankings=[]foriteminsoup.select('.ranking-item'):rank=item.select_one('.rank').text.strip()name=item.select_one('.name').text.strip()rankings.append((rank,name))#打印排名信息forrank,nameinrankings:print(f"{rank}:{name}")ingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;font-size: var(--articleFontsize);letter-spacing: 0.034em;">结构合理性:代码的模块划分是否合理,是否有清晰功能区分。是否考虑了潜在的错误处理和异常情况。准确性:评估代码的准确性和完整性,是否涵盖了所有必要的步骤和细节。 可扩展性:评估代码的可扩展性和可维护性,是否便于后续的修改和扩展。综合评价:(4 + 3.5 + 3.5) / 3 = 3.67 | 









