介绍如何利用Ollama工具,实现Llama 3模型的本地部署与应用,以及通过Open WebUI进行模型交互的方法。

2024年4月,Meta公司开源了Llama 3 AI模型,迅速在AI社区引起轰动。紧接着,Ollama工具宣布支持Llama 3,为本地部署大型模型提供了极大的便利。
本文介绍如何利用Ollama工具,实现Llama 3–8B模型的本地部署与应用,以及通过Open WebUI进行模型交互的方法。
1 安装Ollama
使用“curl | sh”,可以一键下载并安装到本地:
$curl-fsSLhttps://ollama.com/install.sh|sh
>>>Downloadingollama...
########################################################################100.0%
>>>Installingollamato/usr/local/bin...
>>>Creatingollamauser...
>>>Addingollamausertovideogroup...
>>>Addingcurrentusertoollamagroup...
>>>Creatingollamasystemdservice...
>>>Enablingandstartingollamaservice...
Createdsymlinkfrom/etc/systemd/system/default.target.wants/ollama.serviceto/etc/systemd/system/ollama.service.
>>>TheOllamaAPIisnowavailableat127.0.0.1:11434.
>>>Installcomplete.Run"ollama"fromthecommandline.
WARNING:NoNVIDIA/AMDGPUdetected.OllamawillruninCPU-onlymode.
可以看到,下载后Ollama启动了一个ollama系统服务。这项服务是Ollama的核心API服务,并且它驻留在内存中。通过systemctl确认服务的运行状态:
$systemctlstatusollama
●ollama.service-OllamaService
Loaded:loaded(/etc/systemd/system/ollama.service;enabled;vendorpreset:disabled)
Active:active(running)since一2024-04-2217:51:18CST;11hago
MainPID:9576(ollama)
Tasks:22
Memory:463.5M
CGroup:/system.slice/ollama.service
└─9576/usr/local/bin/ollamaserve
另外,这里对Ollama的systemd单元文件做了一些修改。修改了Environment的值,并添加了“OLLAMA_HOST=0.0.0.0”,以便在容器中运行的OpenWebUI能够访问Ollama API服务:
# cat /etc/systemd/system/ollama.service
[Unit]
Description=Ollama Service
After=network-online.target
[Service]
ExecStart=/usr/local/bin/ollama serve
User=ollama
Group=ollama
Restart=always
RestartSec=3
Environment=" ATH=/root/.cargo/bin:/usr/local/cmake/bin:/usr/local/bin:.:/root/.bin/go1.21.4/bin:/root/go/bin:/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/root/bin" "OLLAMA_HOST=0.0.0.0"
ATH=/root/.cargo/bin:/usr/local/cmake/bin:/usr/local/bin:.:/root/.bin/go1.21.4/bin:/root/go/bin:/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/root/bin" "OLLAMA_HOST=0.0.0.0"
[Install]
WantedBy=default.target
修改后,执行以下命令使其生效:
$systemctldaemon-reload
$systemctlrestartollama
2 下载并运行大模型
Ollama支持一键下载和运行模型。
这里用的是一台16/32GB的云虚拟机,但没有GPU。所以使用的是经过聊天/对话微调的Llama3-8B指令模型。只需使用以下命令快速下载并运行模型(4位量化):
$ollamarunllama3
pullingmanifest
pulling00e1317cbf74...0%▕▏0B/4.7GB
pulling00e1317cbf74...7%▕█▏331MB/4.7GB34MB/s2m3s^C
pullingmanifest
pullingmanifest
pullingmanifest
pullingmanifest
pulling00e1317cbf74...61%▕█████████▏2.8GB/4.7GB21MB/s1m23s^C
......
下载和执行成功后,命令行将等待你的问题输入。我们可以随意输入一个关于Go的问题。以下是输出结果:
$ollamarunllama3
>>>couldyoutellmesomethingaboutgolanglanguage?
Go!
HerearesomeinterestingfactsandfeaturesabouttheGoprogramminglanguage:
**WhatisGo?**
Go,alsoknownasGolang,isastaticallytyped,compiled,anddesignedtobeconcurrentandgarbage-collectedlanguage.It
wasdevelopedbyGooglein2009.
**KeyFeatures:**
1.**Concurrency**:Gohasbuilt-inconcurrencysupportthroughgoroutines(lightweightthreads)andchannels(communication
mechanisms).Thismakesiteasytowriteconcurrentprograms.
2.**GarbageCollection**:Gohasaautomaticgarbagecollector,whichfreesdevelopersfromworryingaboutmemory
management.
3.**StaticTyping**:Goisstaticallytyped,meaningthatthetypesystemchecksthetypesofvariablesatcompiletime,
preventingtype-relatederrorsatruntime.
4.**SimpleSyntax**:Go'ssyntaxisdesignedtobesimpleandeasytoread.Ithasaminimalisticapproachtoprogramming
languagedesign.
......
推理速度大约是每秒5到6个token,这个速度是可以接受的,但这个过程对CPU资源的消耗相当大:
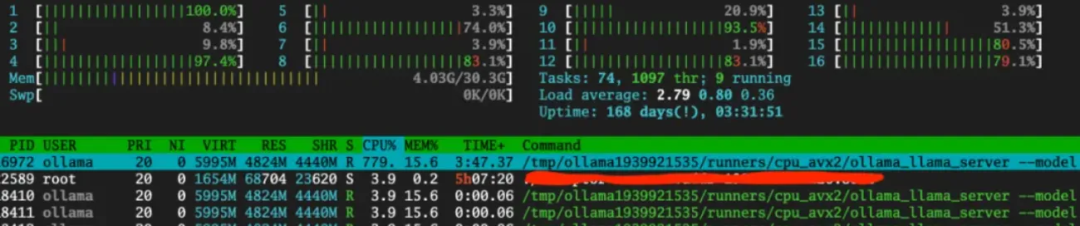
除了可以通过命令行与Ollama API服务交互外,还可以使用Ollama的RESTful API:
$curlhttp://localhost:11434/api/generate-d'{
>"model":"llama3",
>"prompt":"Whyistheskyblue?"
>}'
{"model":"llama3","created_at":"2024-04-22T07:02:36.394785618Z","response":"The","done":false}
{"model":"llama3","created_at":"2024-04-22T07:02:36.564938841Z","response":"color","done":false}
{"model":"llama3","created_at":"2024-04-22T07:02:36.745215652Z","response":"of","done":false}
{"model":"llama3","created_at":"2024-04-22T07:02:36.926111842Z","response":"the","done":false}
{"model":"llama3","created_at":"2024-04-22T07:02:37.107460031Z","response":"sky","done":false}
{"model":"llama3","created_at":"2024-04-22T07:02:37.287201658Z","response":"can","done":false}
{"model":"llama3","created_at":"2024-04-22T07:02:37.468517901Z","response":"vary","done":false}
{"model":"llama3","created_at":"2024-04-22T07:02:37.649011829Z","response":"depending","done":false}
{"model":"llama3","created_at":"2024-04-22T07:02:37.789353456Z","response":"on","done":false}
{"model":"llama3","created_at":"2024-04-22T07:02:37.969236546Z","response":"the","done":false}
{"model":"llama3","created_at":"2024-04-22T07:02:38.15172159Z","response":"time","done":false}
{"model":"llama3","created_at":"2024-04-22T07:02:38.333323271Z","response":"of","done":false}
{"model":"llama3","created_at":"2024-04-22T07:02:38.514564929Z","response":"day","done":false}
{"model":"llama3","created_at":"2024-04-22T07:02:38.693824676Z","response":",","done":false}
......
此外,可以在日常生活中使用大型模型的方式还有通过Web UI进行交互。有许多Web和桌面项目支持Ollama API。在这里选择了Open WebUI,它是从Ollama WebUI发展而来的。
3 安装并使用Open WebUI与大型模型交互
体验Open WebUI最快的方式当然是使用容器安装。但是,官方镜像站点ghcr.io/open-webui/open-webui:main下载速度太慢。这里在Docker Hub上找到了一个个人镜像。以下是在本地安装Open WebUI的命令:
$dockerrun-d-p13000:8080--add-host=host.docker.internal:host-gateway-vopen-webui:/app/backend/data-eOLLAMA_BASE_URL=http://host.docker.internal:11434--nameopen-webui--restartalwaysdyrnq/open-webui:main
容器启动后,通过访问主机上的13000端口来打开Open WebUI页面:

Open WebUI会把第一个注册的用户视为管理员用户。注册并登录后,进入首页:
在选择模型后,可以输入问题并与由Ollama部署的Llama3模型进行对话:

推荐书单
《Llama大模型实践指南》
本书共包括7章,涵盖了从基础理论到实际应用的全方位内容。第1章深入探讨了大模型的基础理论。第2章和第3章专注于Llama 2大模型的部署和微调,提供了一系列实用的代码示例、案例分析和最佳实践。第4章介绍了多轮对话难题,这是许多大模型开发者和研究人员面临的一大挑战。第5章探讨了如何基于Llama 2定制行业大模型,以满足特定业务需求。第6章介绍了如何利用Llama 2和LangChain构建高效的文档问答模型。第7章展示了多语言大模型的技术细节和应用场景。本书既适合刚入门的学生和研究人员阅读,也适合有多年研究经验的专家和工程师阅读。通过阅读本书,读者不仅能掌握Llama 2大模型的核心概念和技术,还能学会如何将这些知识应用于实际问题,从而在这一快速发展的领域中取得优势。










