|
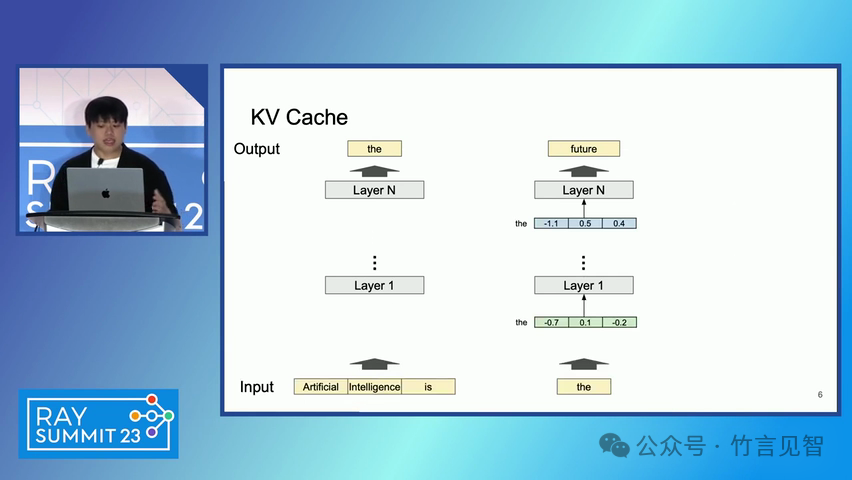
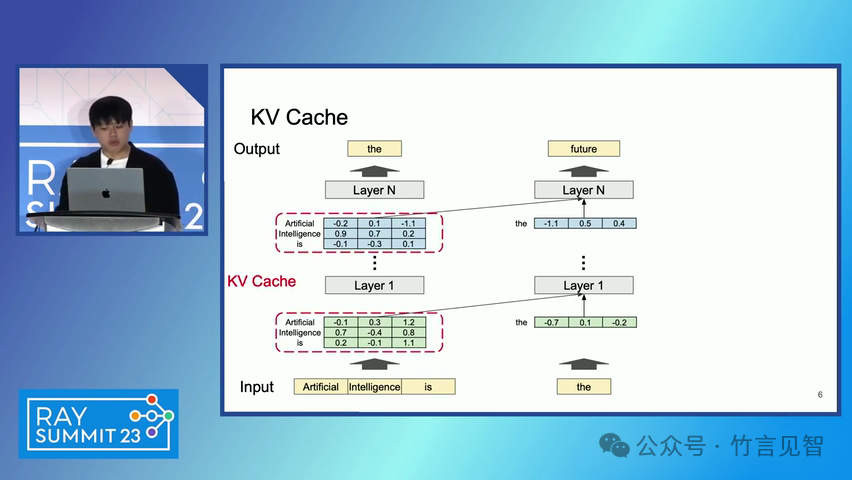
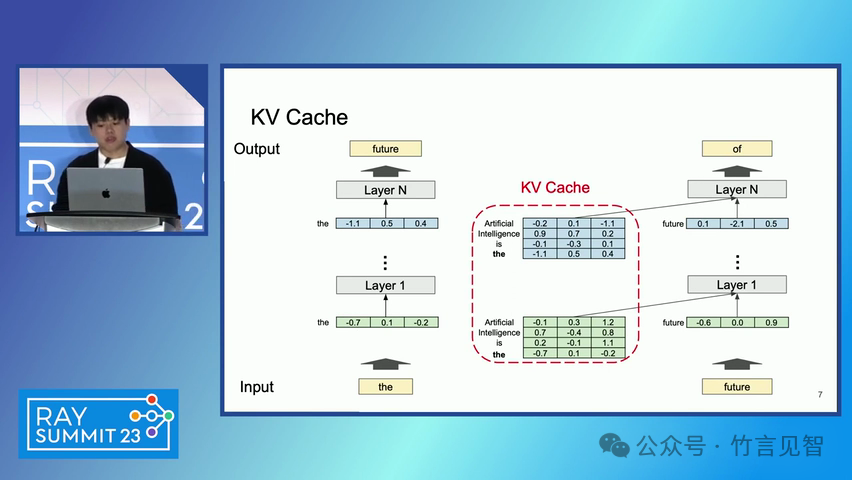
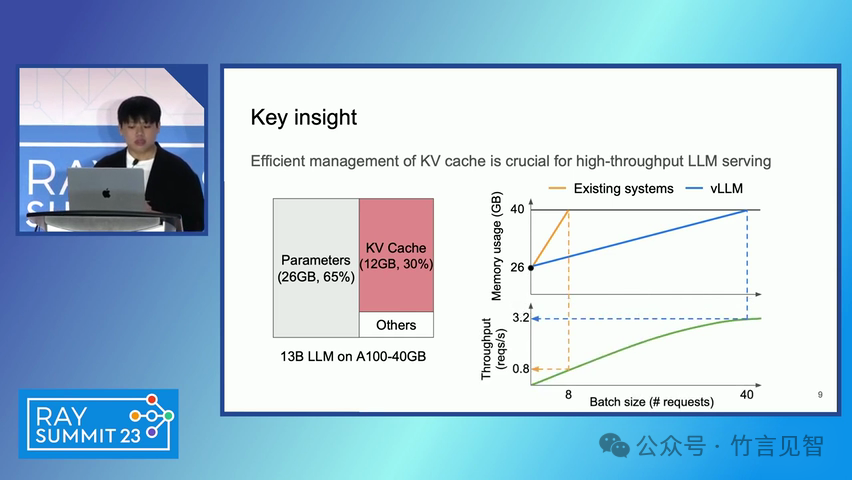
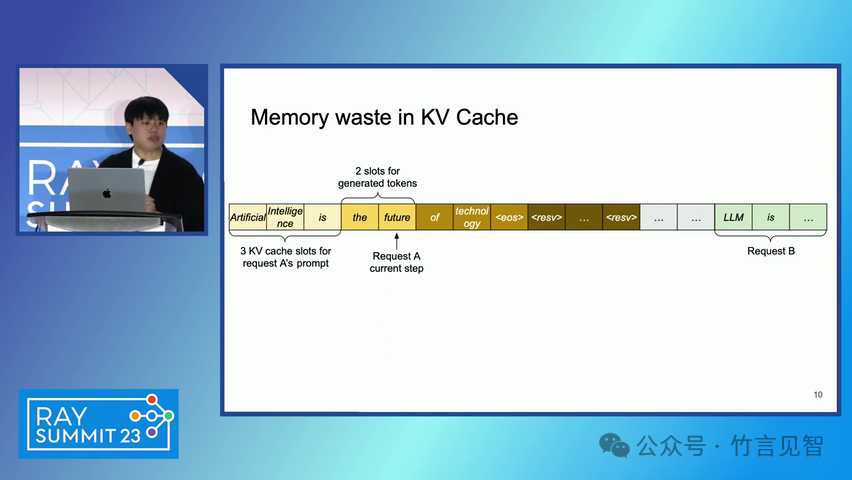
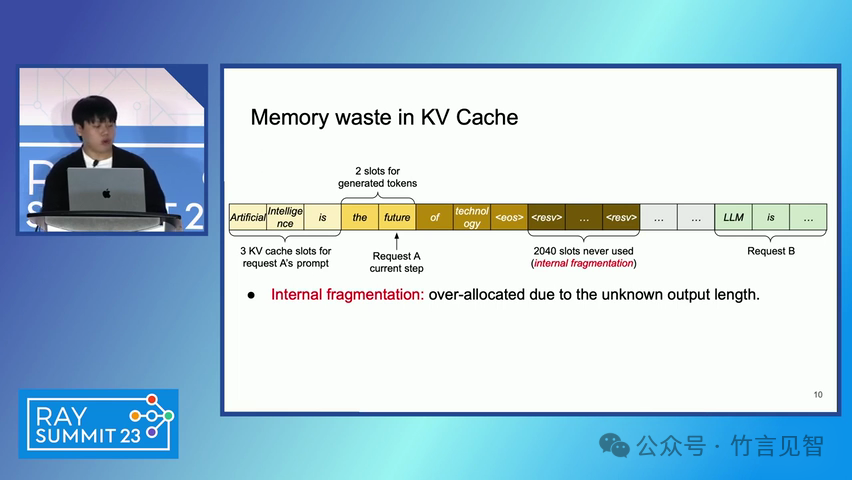
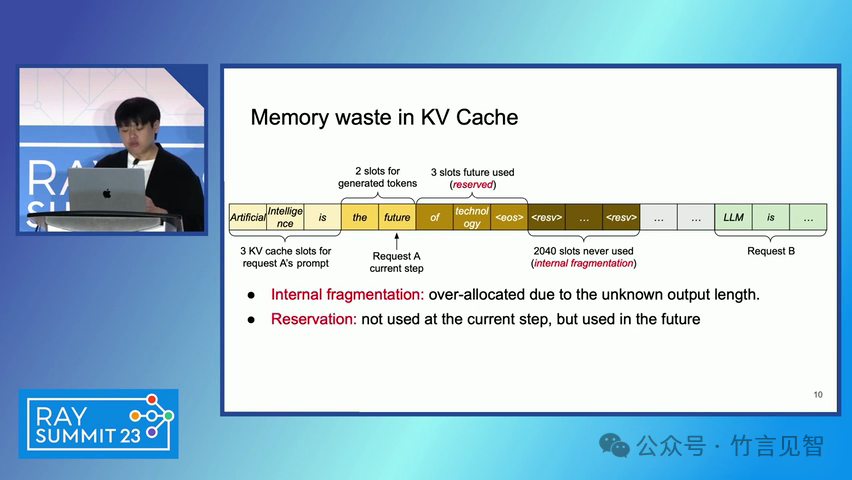
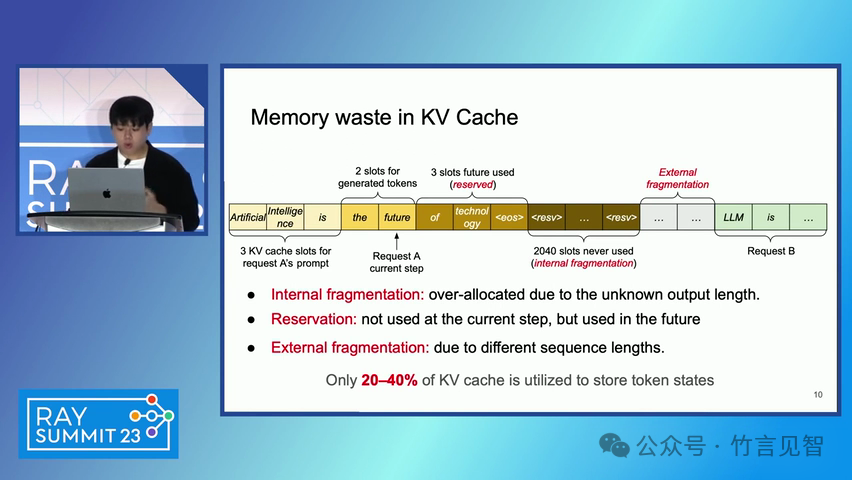
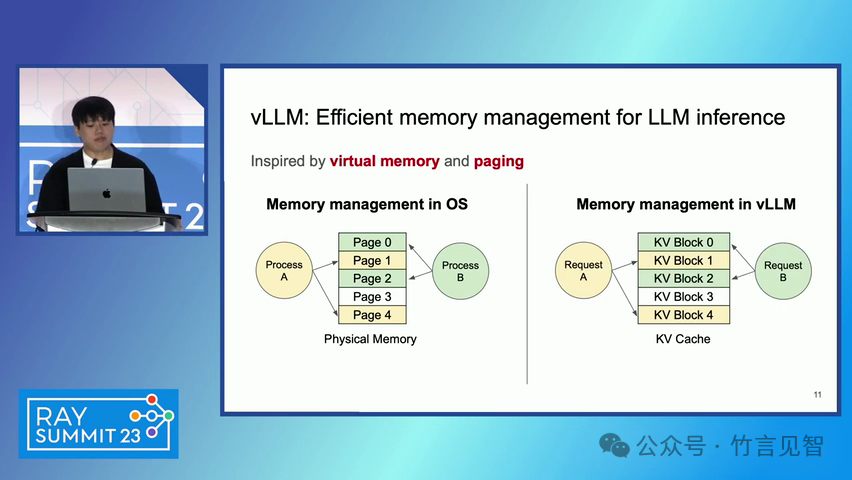
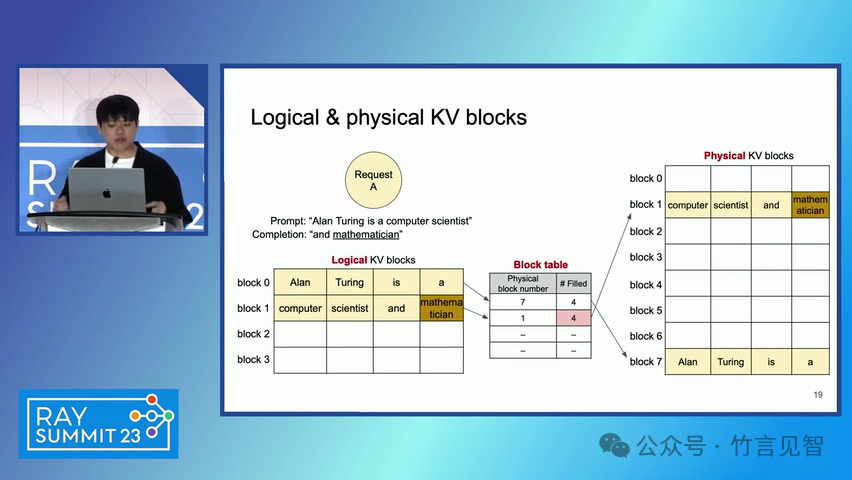
ingFang SC", miui, "Hiragino Sans GB", "Microsoft Yahei", sans-serif;letter-spacing: 0.5px;text-align: start;text-wrap: wrap;background-color: rgb(255, 255, 255);">摘要ingFang SC", miui, "Hiragino Sans GB", "Microsoft Yahei", sans-serif;text-align: start;background-color: rgb(255, 255, 255);white-space-collapse: preserve !important;word-break: break-word !important;">本文提出了一种名为 PagedAttention 的新型注意力算法,以及一个基于该算法构建的大模型(LLM)服务系统 vLLM。该系统通过高效的内存管理,显著提高了 LLM 的吞吐量。PagedAttention 算法受到操作系统中虚拟内存和分页技术的启发,允许在非连续的分页内存中存储连续的键值对。ingFang SC", miui, "Hiragino Sans GB", "Microsoft Yahei", sans-serif;text-align: start;background-color: rgb(255, 255, 255);white-space-collapse: preserve !important;word-break: break-word !important;"> vLLM 系统通过块级内存管理和抢占式请求调度,实现了近乎零浪费的键值缓存(KV cache)内存,并在请求之间灵活共享 KV 缓存。实验结果显示,vLLM 在保持相同延迟水平的情况下,将流行 LLM 的吞吐量提高了 2-4 倍。ingFang SC", miui, "Hiragino Sans GB", "Microsoft Yahei", sans-serif;letter-spacing: 0.5px;text-align: start;text-wrap: wrap;background-color: rgb(255, 255, 255);">问题现状ingFang SC", miui, "Hiragino Sans GB", "Microsoft Yahei", sans-serif;text-align: start;background-color: rgb(255, 255, 255);white-space-collapse: preserve !important;word-break: break-word !important;">大模型(LLM)的高吞吐量服务需要同时处理大量请求,现有系统在管理每个请求的键值缓存(KV cache)内存时存在挑战,因为这些内存需求巨大且动态变化。当管理效率低下时,内存会因碎片化和冗余复制而显著浪费,限制了批量处理的大小。现有的 LLM 服务系统在管理 KV 缓存内存时存在内部和外部内存碎片化,且无法利用内存共享的机会。 解决方案
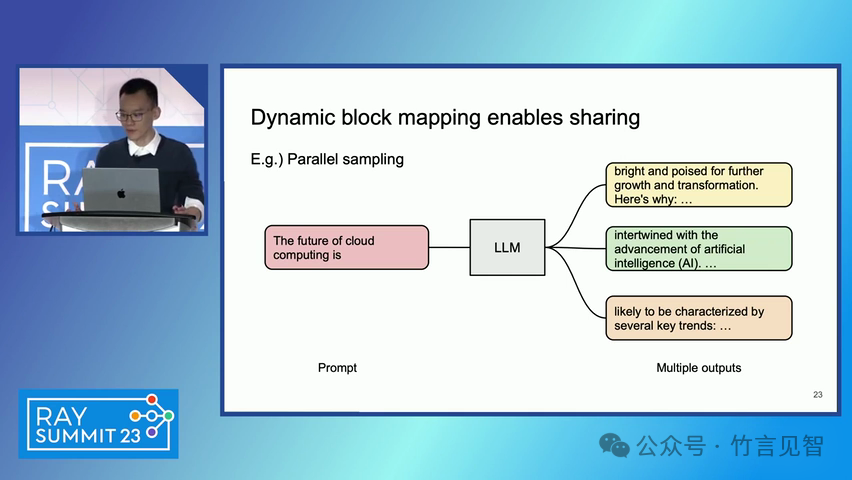
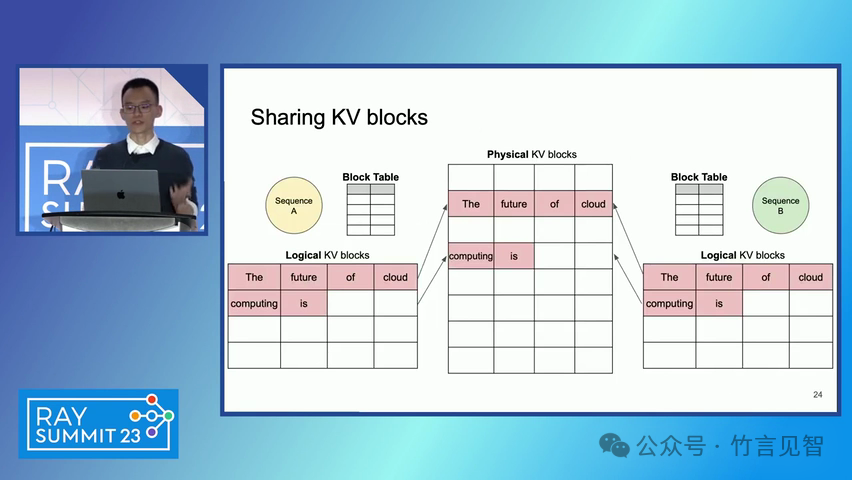
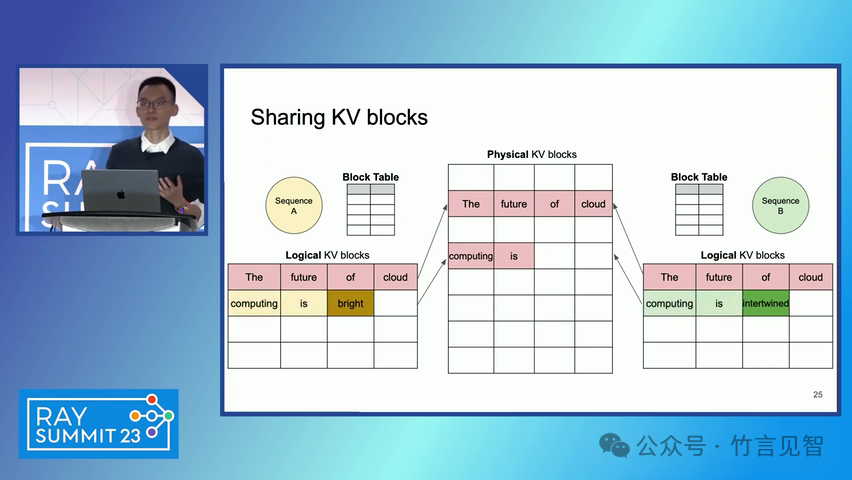
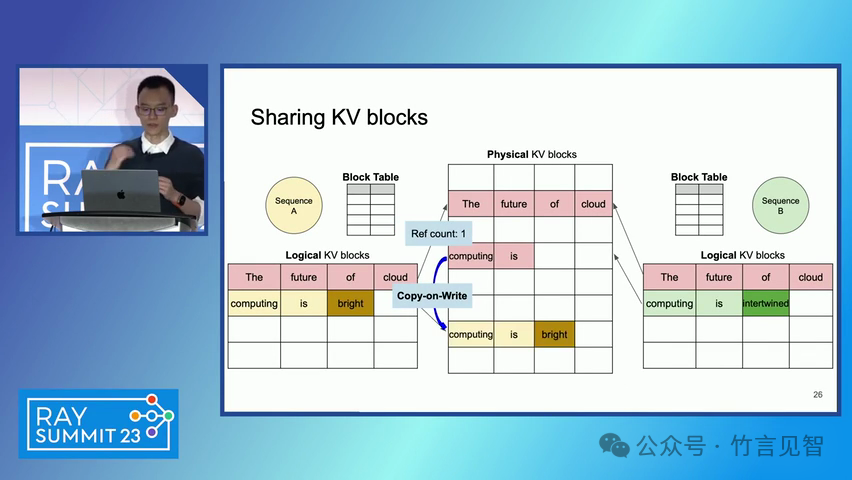
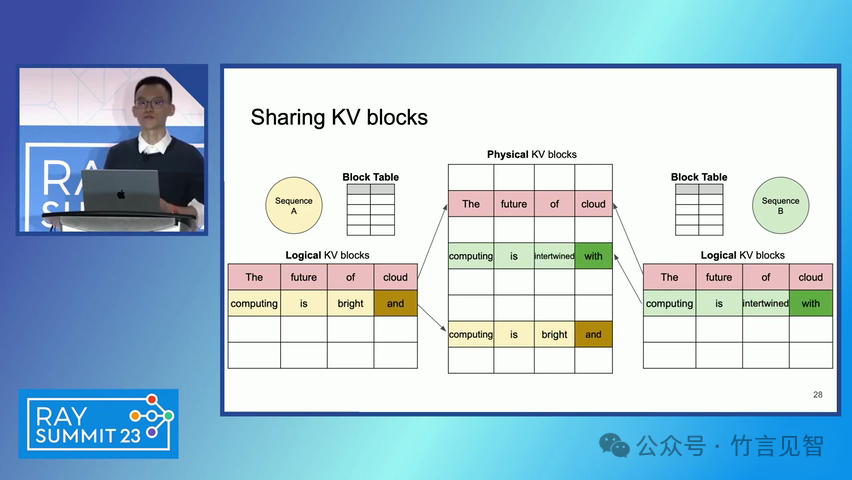
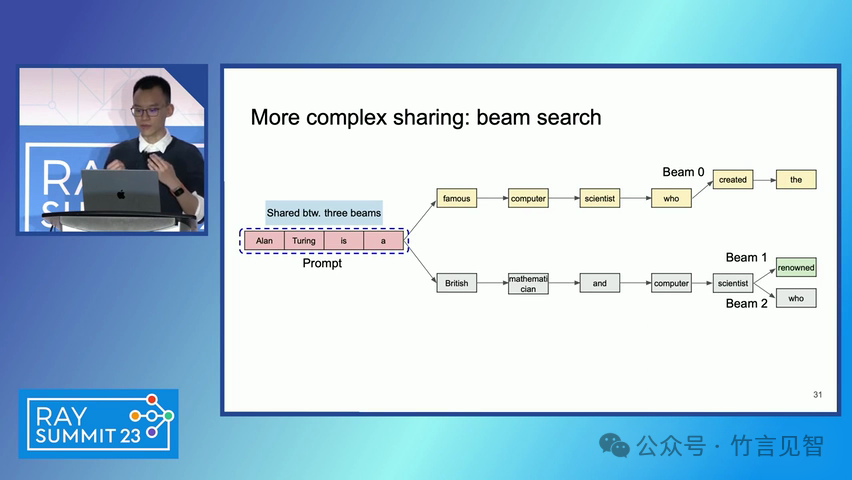
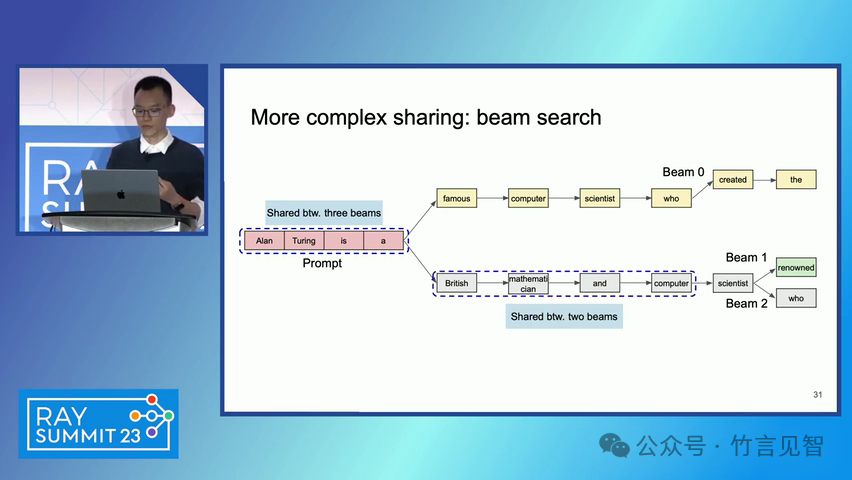
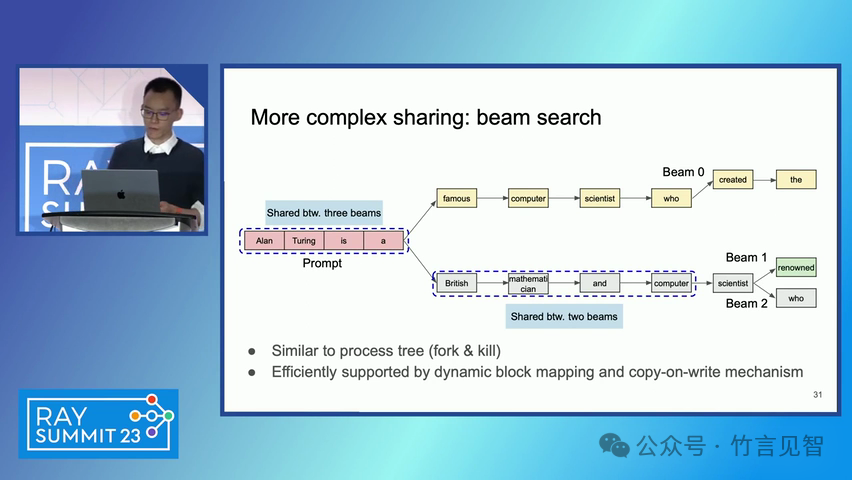
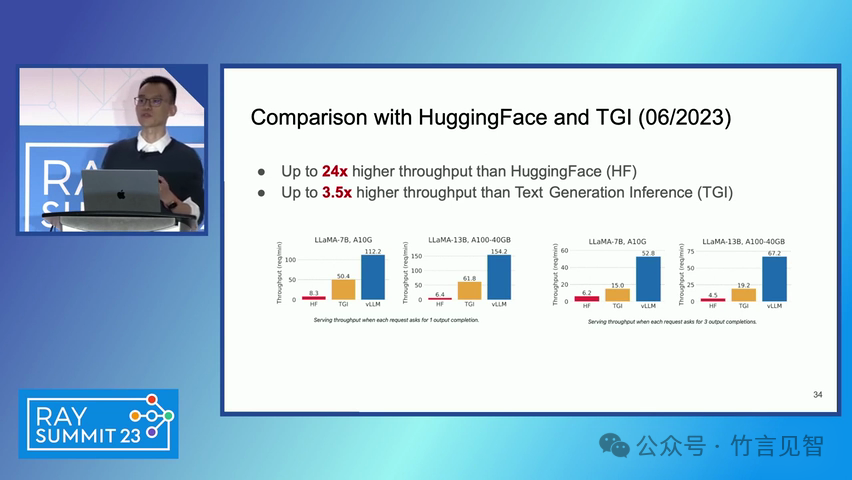
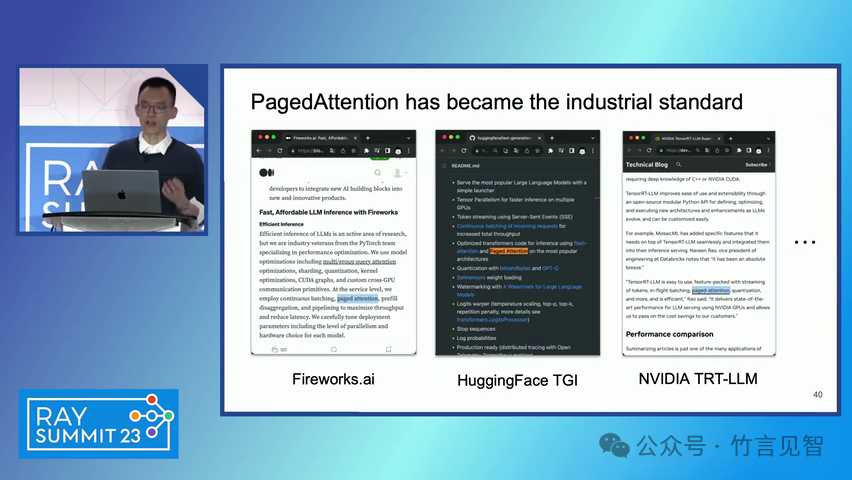
ingFang SC", miui, "Hiragino Sans GB", "Microsoft Yahei", sans-serif;letter-spacing: 0.5px;text-align: start;text-wrap: wrap;background-color: rgb(255, 255, 255);" class="list-paddingleft-1">PagedAttention 算法:一种受操作系统虚拟内存和分页技术启发的注意力算法,允许在非连续的内存空间中存储连续的键和值。 vLLM 系统:一个基于 PagedAttention 构建的高吞吐量分布式 LLM 服务引擎,通过块级内存管理和抢占式请求调度,实现了高效的内存利用。 内存管理:vLLM 通过将 KV 缓存划分为固定大小的块,并在需要时动态分配这些块,从而减少了内存碎片化和浪费。 解码算法支持:vLLM 支持多种解码算法,如并行采样和束搜索(beam search),通过内存共享机制进一步提高内存效率。 ingFang SC", miui, "Hiragino Sans GB", "Microsoft Yahei", sans-serif;letter-spacing: 0.5px;text-align: start;text-wrap: wrap;background-color: rgb(255, 255, 255);">实验数据效果ingFang SC", miui, "Hiragino Sans GB", "Microsoft Yahei", sans-serif;letter-spacing: 0.5px;text-align: start;text-wrap: wrap;background-color: rgb(255, 255, 255);" class="list-paddingleft-1">吞吐量提升:vLLM 在不同模型和工作负载上的评估显示,其吞吐量比现有的最先进系统(如 FasterTransformer 和 Orca)提高了 2-4 倍。 内存效率:通过 PagedAttention 和 vLLM 的内存管理策略,显著减少了内存浪费,提高了内存利用率。 延迟保证:在提高吞吐量的同时,vLLM 保持了与现有系统相似的延迟水平。 ingFang SC", miui, "Hiragino Sans GB", "Microsoft Yahei", sans-serif;letter-spacing: 0.5px;text-align: start;text-wrap: wrap;background-color: rgb(255, 255, 255);">后续扩展ingFang SC", miui, "Hiragino Sans GB", "Microsoft Yahei", sans-serif;letter-spacing: 0.5px;text-align: start;text-wrap: wrap;background-color: rgb(255, 255, 255);" class="list-paddingleft-1">分布式执行:vLLM 支持在分布式 GPU 上执行大型 LLM,通过模型并行策略进一步提高扩展性。 内存管理优化:vLLM 的内存管理策略可以应用于其他具有类似内存需求的 GPU 工作负载,尽管这需要针对具体工作负载进行优化。 decoding算法扩展:vLLM 展示了对多种解码算法的支持,未来可以进一步扩展以支持更多复杂的解码场景
视频地址: https://www.bilibili.com/video/BV1TN4y1B7Fs


































|










