有效市场假说认为股票价格反映了所有可用信息,但研究表明市场效率存在局限性,因此研究人员正在探索各种数据类型以增强预测能力。本文提出了一种新的任务——因素提取,通过使用因素来增强股票运动预测。作者提出了一种新的框架LLMFactor,通过SKGP从LLMs中提取因素,然后解释股票价格趋势。实验结果表明,LLMFactor具有优越的预测结果和解释能力。本文的主要贡献是提出了因素提取任务、SKGP策略和LLMFactor框架。

任务定义
对于给定的股票,我们结合其在目标预测日期发布的相关新闻,预测其历史股票价格序列P。预测股票走势的任务被表述为一个二元分类问题,其中股票价格序列被转换成一系列股票走势P。我们的目标是在给定日期目标、新闻目标和前一天股价的情况下预测当天的股价。我们的方法的基础是序列知识引导提示(SKGP)策略,它包括三个主要阶段。初始阶段包括将股票与相关新闻相匹配,并获取背景知识。
设S为股票列表,其中每个元组(Ci,Ti,Ii)由一家公司Ci、其股票代码Ti和其所属行业Ii组成。我们将S与目标新闻匹配。然后,我们提示LLM获得股票目标与股票匹配之间的关系。这种获取新闻目标背景知识的方法大大提高了我们对新闻内容的理解。
SKGP的下一步包括从新闻目标生成因子。这些因素的重要性有三个方面:
它们与股票走势的关系比关键词、情绪、新闻摘要或整篇新闻文章更密切,因此提供了更有可能获利的市场趋势预测。
与从其他来源获得的因素相比,从新闻文本中获得的因素可以更直接、更详细地了解股价波动。
提高了股价趋势的可解释性和法学硕士预测背后的理论基础。
为了产生可靠的因素,我们指导LLM分析新闻内容,识别可能影响股价的因素。这种方法充分利用了法学硕士的固有知识。提示方法描述为LLM(FactorTemplate)=factor,其中FactorTemplate是一个结构化的句子:“请从以下新闻中提取可能影响股票目标股价的前k个因素”,后面是新闻目标,输出是LLM生成的因素。LLM输出的影响因素并不局限于新闻中的词汇,LLM会考虑新闻的内容及其对股票走势的潜在影响,通常会总结内容中的重要元素。
为了预测股票走势,我们整合新闻背景知识和因素来指导LLM。同时,我们将时间序列数据转换为文本格式,以供LLM理解。给定文本股票移动序列TextMovement及其日期系列date ={日期1,日期2,…,日期t},过去的股票价格变动被转换成一个TimeTemplate,其结构为“日期i,股票目标的股价f(P i)”。
随后,我们构建了一个PriceTemplate,其中包括一个初始指令,“基于以下信息,请判断股票价格的方向是上涨还是下跌,填空并给出理由”,然后是一个结语指令,“在日期i,股票目标的股票价格将___。”通过整合关系、因子、时间模板和PriceTemplate,我们将提示方法表述为LLM(关系、因子、时间模板、PriceTemplate)=预测。预测结果指定了股票价格是“上涨”还是“下跌”,以及这种推断的基本原理。
SKGP提供了一种预测股票走势的强大技术,从SKGP衍生的因素为股票市场趋势提供了额外的见解。例如,因子分析可以应用于股票市场。以英伟达的股价走势为例,在经历了过去五天的持续上涨后,蓝色方框突出显示的那一天也呈现出上涨趋势。为了解释这一现象,我们的LLMFactor确定了一组简明的因素,例如“英伟达1月份的股票上涨,新产品发布,以及电动汽车制造商选择英伟达Drive Thor。”
数据集
本文在四个基准数据集上进行实验,分别是StockNet、CMINUS、CMIN-CN和EDT。其中,前三个数据集关注时间序列预测,而EDT数据集则关注新闻内容。这些数据集包含了股票相关的推文和历史价格数据,用于股票市场的分析。
我们使用准确率(ACC)和马修斯相关系数(MCC)作为评估指标。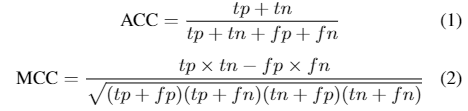
为了进行预测,我们使用了几个模型来识别文本中的关键短语:PromptRank、KeyBERT、YAKE、TextRank、TopicRank、SingleRank和TFIDF。
我们使用以下模型来分析文本中的情绪并预测股市走势:EDT、FinGPT、GPT-4-turbo、GPT-4、GPT-3.5-turbo、RoBERTa、FinBERT。
我们采用同时利用文本和时间序列数据的模型来预测股票走势:CMIN、StockNet。
结果
LLMFactor能够从文本数据中识别影响股票价格的重要因素,并结合关系和时间信息进行综合分析。在四个数据集上的实验结果表明,LLMFactor的性能优于其他方法,包括基于时间、情感和关键词的方法。

与其他SOTA相比,LLMFactor在四个数据集上的MCC提高了2.9%,0.4%,11%和4.8%。关键词模型的表现差异不大,情感模型的表现因模型不同而异。时间模型和情感模型的表现相当,但LLMFactor在SKGP技术的帮助下,能够更好地过滤无关内容,提供更全面的分析。
在不同数据集上的平均分数分析表明,LLMFactor在美国市场的StockNet和CMIN-US数据集上的平均准确率超过63%,平均MCC超过0.2。但在针对中国市场的CMIN-CN数据集上,其表现略有下降。EDT数据集中缺乏历史价格信息,这可能会降低LLMFactor的效果,强调了金融市场分析所需的全面数据的重要性。
本文对LLMFactor进行了消融分析。实验结果表明,价格层对ACC和MCC的总体表现贡献了约86%和32%,因素层在ACC和MCC方面分别提高了9%和46%,而关系层则分别提高了5%和22%。因素层对LLMFactor的整体性能贡献最大。此外,本文还对不同类型的FactorTemplate进行了实验。
通过对美国和中国市场中的股票进行因子分析,LLMFactor能够有效地整合公司关联背景知识、历史新闻和价格数据,从而提高股票市场动态的可解释性。通过案例分析,展示了LLMFactor在股票市场分析中的实际效果。










