ingFang SC", miui, "Hiragino Sans GB", "Microsoft Yahei", sans-serif; background-color: rgb(255, 255, 255); word-break: break-word !important;">从非结构化数据中提取结构化数据,不仅是 LLM 的核心用例,也是检索和 RAG 使用案例中数据处理的关键要素。今天我们很高兴宣布 LlamaExtract 的 beta 版本发布,这是一个托管服务,让您能够从非结构化文档中执行结构化提取。ingFang SC", miui, "Hiragino Sans GB", "Microsoft Yahei", sans-serif; background-color: rgb(255, 255, 255); word-break: break-word !important;">它执行以下操作:
ingFang SC", miui, "Hiragino Sans GB", "Microsoft Yahei", sans-serif; letter-spacing: 0.5px; background-color: rgb(255, 255, 255);">从现有候选文档集推断出模式。您可以选择稍后编辑此模式。 根据指定的模式(无论是从上一步推断出来的、由人类指定的,或两者兼有)从一组文档中提取值。 ingFang SC", miui, "Hiragino Sans GB", "Microsoft Yahei", sans-serif; background-color: rgb(255, 255, 255); word-break: break-word !important;">LlamaExtract 可通过 UI 和 API 供 LlamaCloud 用户使用。模式推断目前有 5 个文件的限制,每个文件最多 10 页。给定现有模式,模式提取发生在每个文档级别上。ingFang SC", miui, "Hiragino Sans GB", "Microsoft Yahei", sans-serif; font-size: 14px; letter-spacing: 0.5px; background-color: rgb(255, 255, 255);">LlamaExtract 目前处于beta阶段,这意味着它是一个我们正在努力改进的实验性功能,使其更普遍可扩展和可用。请将任何问题报告到我们的 Github! ingFang SC", miui, "Hiragino Sans GB", "Microsoft Yahei", sans-serif; letter-spacing: 0.5px; background-color: rgb(255, 255, 255);">元数据提取是 LLM ETL 栈的关键部分ingFang SC", miui, "Hiragino Sans GB", "Microsoft Yahei", sans-serif; background-color: rgb(255, 255, 255); word-break: break-word !important;">LLM 应用需要一个新的数据 ETL 栈。这个数据加载、转换和索引层对于非结构化数据上的下游 RAG 和代理使用案例至关重要。ingFang SC", miui, "Hiragino Sans GB", "Microsoft Yahei", sans-serif; background-color: rgb(255, 255, 255); word-break: break-word !important;">我们构建了 LlamaParse 和 LlamaCloud 来满足这些 ETL 需求,并在生产中为成千上万的复杂文档生产管道提供动力。通过与我们的用户和客户合作,我们意识到除了块级嵌入之外,自动化元数据提取是转换故事(ETL 中的 “T”)的重要组成部分;它是增加对广泛非结构化数据透明度和控制的核心必要成分。ingFang SC", miui, "Hiragino Sans GB", "Microsoft Yahei", sans-serif; background-color: rgb(255, 255, 255); word-break: break-word !important;">这引导我们构建了 LlamaExtract 的初始版本:旨在自动化您的非结构化数据转换。LlamaExtract 是一个 API,它还有一个 Python客户端,当然还有 LlamaCloud 中的 Web UI。ingFang SC", miui, "Hiragino Sans GB", "Microsoft Yahei", sans-serif; background-color: rgb(255, 255, 255); word-break: break-word !important;">使用 UI 进行原型设计LlamaExtract UI 允许您对提取作业进行原型设计。在左侧点击 “提取(beta)” 标签后,您可以点击 “创建新模式” 以定义新的提取作业,这将带您进入模式创建屏幕: 
将文件拖放到 UI 中。点击 “下一步” 启动模式推断 — 推断出的 JSON 模式将在下面的 “模式” 部分显示: 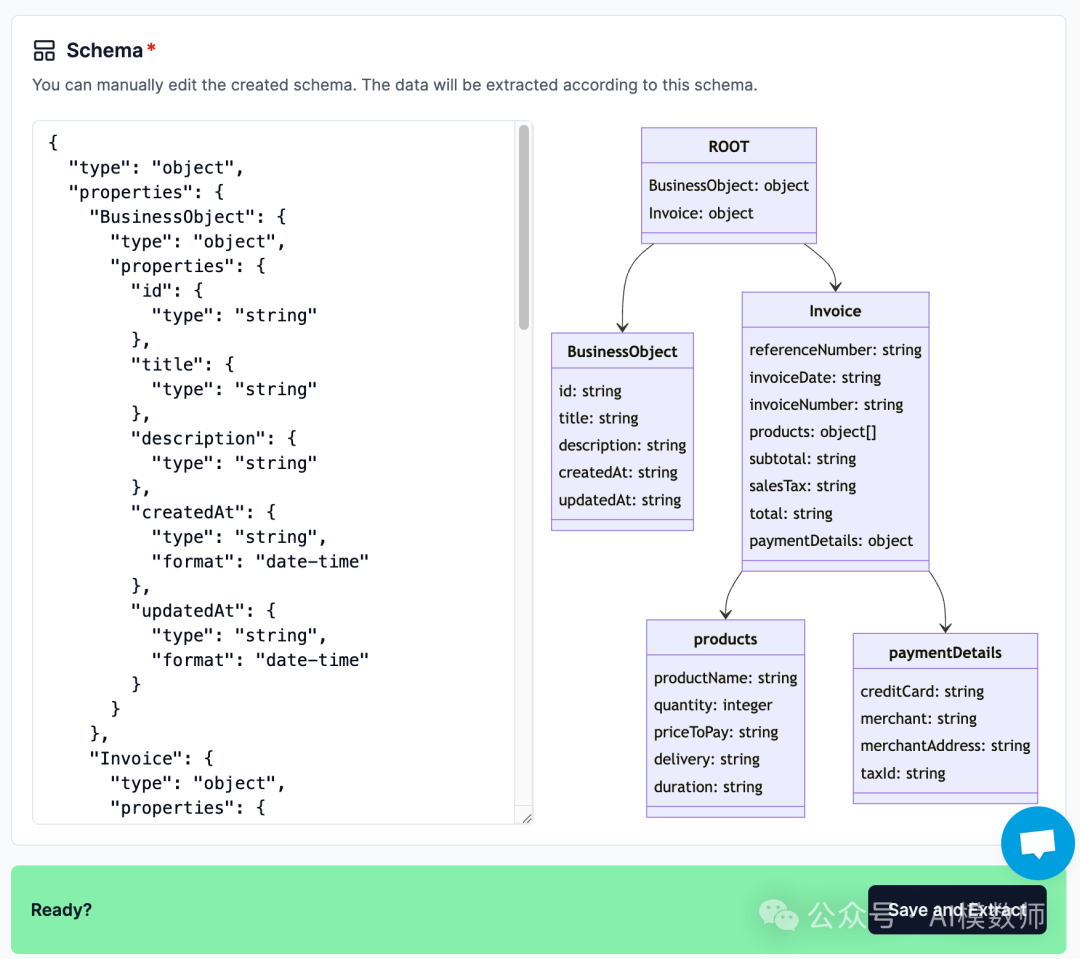
这遵循 Pydantic JSON 模式格式;推断之后,您可以完全自由地自定义和修改推断出的模式。模式可视化将反映您的更改。 一旦您对模式满意,您可以启动提取,这将返回最终的 JSON 对象,其中包含符合模式的提取键和值。 使用 API 创建提取工作流 API 允许用户更灵活地集成模式推断和提取。要通过我们的客户端包访问 API,请按照以下步骤操作:
您可以选择推断一个模式或指定自己的模式(或者先推断,然后按您的喜好程序修改)。如果您想使用 LlamaExtract 的模式推断能力,请执行: pythonfrom llama_extract import LlamaExtract
extractor = LlamaExtract()extraction_schema = extractor.infer_schema("Test Schema", ["./file1.pdf","./file2.pdf"])
如果您更倾向于直接指定模式而不是推断它。 最简单的方法是定义一个Pydantic对象并将其转换为JSON模式: frompydanticimportBaseModel,Field
classResumeMetadata(BaseModel):"""Resume metadata."""
years_of_experience: int= Field(..., description="Number of years of work experience.")highest_degree: str= Field(..., description="Highest degree earned (options: High School, Bachelor's, Master's, Doctoral, Professional)")professional_summary: str= Field(..., description="A general summary of the candidate's experience")extraction_schema = extractor.create_schema("Test Schema", ResumeMetadata)
extractions=extractor.extract(extraction_schema.id,["./file3.pdf","./file4.pdf"])
您可以看到提取的数据: print(extractions[0].data)
场景用例 LlamaExtract 使用 LlamaParse 作为其底层解析器,能够处理复杂的文档类型通过我们的初步探索,以下是LlamaExtract 有价值的一些初始数据集: |










