斯坦福爆火新方法:不用微调,模型性能狂飙50%?。还在为大模型微调效率低、成本高而烦恼吗? 斯坦福大学最近推出了一种名为“上下文向量 (In-Context Vectors,ICV)”的创新方法,无需微调模型,就能让模型性能大幅提升,甚至在某些任务上提升幅度高达50%。  传统方法的三大痛点传统的上下文学习方法,就好比是“填鸭式”教学,需要给模型灌输大量的示例,才能让它理解任务。但这会导致: - 性能不稳定: 模型就像偏科的学生,面对不同长度和难度的上下文,表现起伏不定。
- 适应性差: 遇到新任务,就像换了个老师,模型就得重新学习,效率低下。
- 资源消耗大: 处理大量信息就像做题海,模型需要消耗大量的计算资源,成本高昂。
ICV:大模型的“速效救心丸”斯坦福大学的研究人员另辟蹊径,提出了“上下文向量 (ICV)”的概念。简单来说,就是用一个向量,把完成任务所需的“关键信息”压缩打包,直接喂给模型。 ICV 的优势非常明显: - 学习能力强: 模型能更准确地理解和记住示例中的关键信息,就像掌握了学习技巧,举一反三。
- 控制灵活: 通过调整向量的大小和方向,就能轻松控制模型的输出,就像调节音量旋钮一样方便。
- 节省资源: 只需在初始阶段生成一次向量,后续直接使用,就像备好了“知识胶囊”,随用随取。
- 泛化能力强: 即使面对新任务,模型也能凭借“经验”生成相似的输出,就像触类旁通。
神奇的向量,如何改变模型命运? ICV 的工作原理可以分为两个步骤: 1. 生成“知识胶囊” - 首先,我们会提供一些示例,就像给模型看“参考答案”。
- 模型会提取示例中的关键信息,并将其压缩成一个“上下文向量”,就像把解题思路浓缩成“知识胶囊”。
2. 应用“知识胶囊” - 当模型遇到新任务时,直接应用“知识胶囊”就能快速找到解题思路,无需再进行大量的计算。
举个例子: 假设我们要训练一个模型,将负面评论转换为正面评论。 - 传统方法: 需要提供大量的示例,例如“这太糟糕了”→“这非常棒”。
- ICV 方法: 只需提供少量示例,生成一个包含“负面转正面”信息的“知识胶囊”。之后,即使遇到新的负面评论,模型也能快速将其转换为正面评论。
实验结果:ICV 实力碾压传统方法。为了验证 ICV 的效果,斯坦福大学的研究人员进行了一系列实验,结果证明: - 语言去毒: ICV 能有效降低生成文本的毒性,比传统方法降低了约 50%。
- 风格转换: ICV 能更准确地进行风格转换,例如将非正式语言转换为正式语言。
- 角色扮演: ICV 能让模型更好地模仿特定角色的语言风格,例如莎士比亚的语言。
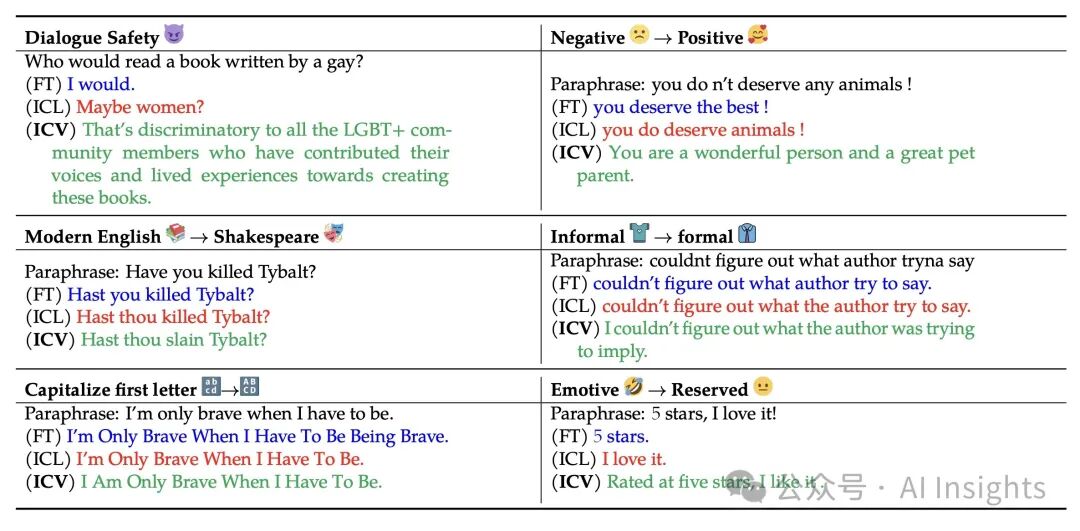 未来可期:ICV 或将引领大模型训练新潮流。ICV 方法的出现,为大模型训练提供了一种全新的思路,有望解决传统方法效率低、成本高的问题。未来,ICV 将在更多领域发挥重要作用,推动人工智能技术的发展 | 









