|
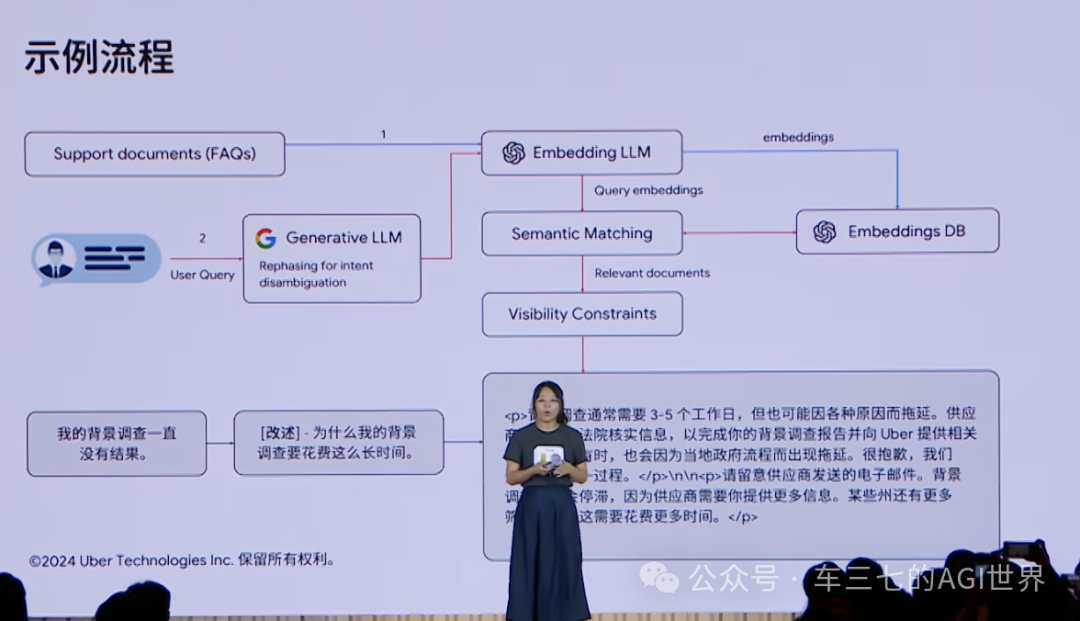
从B站看到一位小姐姐分享《基于 Gemini 和向量搜索的生成式推荐》,里面提到做RAG的流程,我总结为4大阶段10个步骤如下: 一、知识准备阶段 1. 文档收集与预处理 首先收集大量的相关文档,即知识。这些文档可以是文本文件、PDF、网页、图片等多种形式。收集完成后,对文档进行预处理,包括清洗、去重等,确保数据的质量。其中可以做元数据提取,提取文件名、章节title、图片alt信息等,也利用OCR等技术,将PDF、图片等内容数字化。 2. 文档内容分块 将文档分割成若干个数据分块,以便于后续的处理和检索。有多种分块方式,比如固定大小分块或意图分块等。固定大小分块要注意增加“块”的冗余量,否则会损失很多语义,比如“我们今天晚上应该去吃个大餐庆祝一下”,可能被分在两个“块”里面——“我们今天晚上应该”、“去吃个大餐庆祝一下”,这样对检索是非常不友好的。增加“块”的冗余,就是一头一尾保留相邻“块”头尾的内容。 3. 向量数据库存储 将分块后的内容转化为向量,存储到向量数据库中,即embedding,以便于快速检索。 二、问题处理阶段 4. 用户交互与问题处理 针对用户问题,使用大模型的能力进行拼写检查和内容改写,在保证问题原意的前提下,使问题变成一个适合向量检索的问题。比如“用户提问:我的背景调查一直没有结果。”改写为“为什么我的背景调查要花费这么长时间。” 5. 问题向量化 将处理后的用户问题转化为向量,以便与向量数据库中的向量进行相似度检索和语义匹配。 三、问题召回阶段 6. 内容召回 根据匹配结果,召回与问题最相关的topN个文档。为保证检索结果全面性和准确性,可能会混合使用相似度检索、关键词检索、SQL检索等多种技术。 7. 合规处理 根据既定的安全规则,对召回文档进行审查处理,确保信息的安全性和合法性,包括用户是否有权接触该信息。 8. 生成回答 将用户问题、召回的合规文档等内容组成提示词提供大模型,生成回答。 四、答案优化阶段 9. 多轮检索优化 为了保证答案的准确性和完整性,系统可能需要进行多轮检索,对每一轮生成的答案进行比较,判断是否需要修改或追加答案。 这里的原因是“块”的数量很多,每次检索的维度不一定是最优的,所以需要把相关度、匹配度等因素做一些重新调整,得到更符合业务场景的排序。可能有一个内部判断器来评审相关度,触发重排序。 10. 最终答案呈现 经过多轮检索后,最终让大模型生成一个经过检验的最准确的答案,呈现给用户。 | 









