ingFang SC", Cambria, Cochin, Georgia, serif;font-style: normal;font-variant-ligatures: normal;font-variant-caps: normal;letter-spacing: normal;orphans: 2;text-indent: 0px;text-transform: none;widows: 2;word-spacing: 0px;-webkit-text-stroke-width: 0px;white-space: normal;text-decoration-thickness: initial;text-decoration-style: initial;text-decoration-color: initial;">引言ingFang SC", Cambria, Cochin, Georgia, serif;font-size: medium;font-style: normal;font-variant-ligatures: normal;font-variant-caps: normal;font-weight: 400;orphans: 2;text-indent: 0px;text-transform: none;widows: 2;word-spacing: 0px;-webkit-text-stroke-width: 0px;white-space: normal;text-decoration-thickness: initial;text-decoration-style: initial;text-decoration-color: initial;">2022年ChatGPT的成功发布让人们意识到,生成式AI不仅能为希望自动化手动且耗时任务的个人带来诸多优势,也能助力寻求提升客户体验和优化运营的企业。ingFang SC", Cambria, Cochin, Georgia, serif;font-size: medium;font-style: normal;font-variant-ligatures: normal;font-variant-caps: normal;font-weight: 400;orphans: 2;text-indent: 0px;text-transform: none;widows: 2;word-spacing: 0px;-webkit-text-stroke-width: 0px;white-space: normal;text-decoration-thickness: initial;text-decoration-style: initial;text-decoration-color: initial;">生成式AI解决方案需求的增加促使多家公司投资于开源解决方案的研究与开发,如Mistral AI的Mixtral或Meta的LLaMA 3。对生成式AI(GenAI)的大量投资使得这些模型广泛面向公众开放,从而使多数公司的关注点从开发内部大型语言模型(LLMs)转向部署这些开源版本。ingFang SC", Cambria, Cochin, Georgia, serif;font-size: medium;font-style: normal;font-variant-ligatures: normal;font-variant-caps: normal;font-weight: 400;orphans: 2;text-indent: 0px;text-transform: none;widows: 2;word-spacing: 0px;-webkit-text-stroke-width: 0px;white-space: normal;text-decoration-thickness: initial;text-decoration-style: initial;text-decoration-color: initial;">关于这些模型的产品化,我们不禁思考两个问题:应使用哪种模型,以及如何大规模且安全地部署它?本文旨在解答这些问题。我们提出了一种名为RAQ(相对答案质量)的方法,通过使用独立LLM比较和排序不同LLM的答案来评估它们。我们方法的关键差异在于,它可以轻松融入任何工作流程,并能评估任何领域/主题/用例上的任意LLM集合。RAQ可应用于拥有特定主题问题和正确答案数据集的组织,也可在没有此类数据集的情况下应用。我们提出的方法的另一优势是,数据集大小可以量化。我们利用统计测试来确定排名差异是否显著,使机器学习从业者能自信地判断一个LLM是否优于另一个。排名本质上基于它们与真实答案的接近程度,无论被评估数据的领域/主题/用例如何。ingFang SC", Cambria, Cochin, Georgia, serif;font-size: medium;font-style: normal;font-variant-ligatures: normal;font-variant-caps: normal;font-weight: 400;orphans: 2;text-indent: 0px;text-transform: none;widows: 2;word-spacing: 0px;-webkit-text-stroke-width: 0px;white-space: normal;text-decoration-thickness: initial;text-decoration-style: initial;text-decoration-color: initial;">针对第二个问题,我们展示了如何利用NVIDIA的新NIM微服务轻松从研究过渡到生产级解决方案。NIM支持大规模部署LLM,首先通过使用NVIDIA托管服务的快速原型设计,然后针对生产环境,在任何私有云或物理硬件上进行自托管部署。针对加速硬件配置组合和领先开源模型的推理引擎已预先优化,因此我们能以最小努力搭建基础设施。此外,它还提供了使用LoRA对模型进行微调的灵活性。ingFang SC", Cambria, Cochin, Georgia, serif;font-size: medium;font-style: normal;font-variant-ligatures: normal;font-variant-caps: normal;font-weight: 400;orphans: 2;text-indent: 0px;text-transform: none;widows: 2;word-spacing: 0px;-webkit-text-stroke-width: 0px;white-space: normal;text-decoration-thickness: initial;text-decoration-style: initial;text-decoration-color: initial;"> ingFang SC", Cambria, Cochin, Georgia, serif;font-size: medium;font-style: normal;font-variant-ligatures: normal;font-variant-caps: normal;font-weight: 400;orphans: 2;text-indent: 0px;text-transform: none;widows: 2;word-spacing: 0px;-webkit-text-stroke-width: 0px;white-space: normal;text-decoration-thickness: initial;text-decoration-style: initial;text-decoration-color: initial;">一如既往,代码可在我们的GitHub上获取。ingFang SC", Cambria, Cochin, Georgia, serif;font-style: normal;font-variant-ligatures: normal;font-variant-caps: normal;letter-spacing: normal;orphans: 2;text-indent: 0px;text-transform: none;widows: 2;word-spacing: 0px;-webkit-text-stroke-width: 0px;white-space: normal;text-decoration-thickness: initial;text-decoration-style: initial;text-decoration-color: initial;">RAQ:相对答案质量ingFang SC", Cambria, Cochin, Georgia, serif;font-size: medium;font-style: normal;font-variant-ligatures: normal;font-variant-caps: normal;font-weight: 400;orphans: 2;text-indent: 0px;text-transform: none;widows: 2;word-spacing: 0px;-webkit-text-stroke-width: 0px;white-space: normal;text-decoration-thickness: initial;text-decoration-style: initial;text-decoration-color: initial;">如前所述,在ChatGPT发布后,对开源大型语言模型(LLMs)的研究和开发投入了巨大资源。事实上,几乎每周都有新的模型或模型的变体发布。面对如此多的选择,如何为自己的应用场景选择最佳模型呢?ingFang SC", Cambria, Cochin, Georgia, serif;font-size: medium;font-style: normal;font-variant-ligatures: normal;font-variant-caps: normal;font-weight: 400;orphans: 2;text-indent: 0px;text-transform: none;widows: 2;word-spacing: 0px;-webkit-text-stroke-width: 0px;white-space: normal;text-decoration-thickness: initial;text-decoration-style: initial;text-decoration-color: initial;">定量指标如推理时间很重要,在选择LLM时应予以考虑。然而,一个推理速度快但回答质量低的LLM可能并非理想选择。 ingFang SC", Cambria, Cochin, Georgia, serif;font-size: medium;font-style: normal;font-variant-ligatures: normal;font-variant-caps: normal;font-weight: 400;orphans: 2;text-indent: 0px;text-transform: none;widows: 2;word-spacing: 0px;-webkit-text-stroke-width: 0px;white-space: normal;text-decoration-thickness: initial;text-decoration-style: initial;text-decoration-color: initial;">一如既往,代码可在我们的GitHub上获取。ingFang SC", Cambria, Cochin, Georgia, serif;font-style: normal;font-variant-ligatures: normal;font-variant-caps: normal;letter-spacing: normal;orphans: 2;text-indent: 0px;text-transform: none;widows: 2;word-spacing: 0px;-webkit-text-stroke-width: 0px;white-space: normal;text-decoration-thickness: initial;text-decoration-style: initial;text-decoration-color: initial;">RAQ:相对答案质量ingFang SC", Cambria, Cochin, Georgia, serif;font-size: medium;font-style: normal;font-variant-ligatures: normal;font-variant-caps: normal;font-weight: 400;orphans: 2;text-indent: 0px;text-transform: none;widows: 2;word-spacing: 0px;-webkit-text-stroke-width: 0px;white-space: normal;text-decoration-thickness: initial;text-decoration-style: initial;text-decoration-color: initial;">如前所述,在ChatGPT发布后,对开源大型语言模型(LLMs)的研究和开发投入了巨大资源。事实上,几乎每周都有新的模型或模型的变体发布。面对如此多的选择,如何为自己的应用场景选择最佳模型呢?ingFang SC", Cambria, Cochin, Georgia, serif;font-size: medium;font-style: normal;font-variant-ligatures: normal;font-variant-caps: normal;font-weight: 400;orphans: 2;text-indent: 0px;text-transform: none;widows: 2;word-spacing: 0px;-webkit-text-stroke-width: 0px;white-space: normal;text-decoration-thickness: initial;text-decoration-style: initial;text-decoration-color: initial;">定量指标如推理时间很重要,在选择LLM时应予以考虑。然而,一个推理速度快但回答质量低的LLM可能并非理想选择。在特定应用场景下对LLM进行定性评估是一项耗时且手动的工作,因为需要基于数百个问题来评估模型。这非常主观,需要阅读数百个答案并与标准答案进行比较。因此,为了解决这一问题并减少评估回答质量所需的手动工作,我们提出了RAQ框架。 RAQ框架依赖于一个独立的LLM,该LLM接收问题、标准答案以及一组LLMs的答案,并利用这个独立LLM根据它们与标准答案的匹配程度进行排序。当不存在带有问题和答案的数据集时,可以开发RAQ的扩展版本。在这种情况下,我们可以使用另一个独立LLM来为我们生成这些数据。还有一种混合设置,即存在一个小型数据集但不足以运行RAQ。此时,我们可以利用这个小数据集作为种子,通过独立LLM采用半合成方法生成类似示例。 独立LLMs可能包含偏见和其他潜在问题。为了克服这一点,我们提出两种选择:i) 选择最佳可用开源或闭源模型;或者 ii) 选择一批顶级模型,并对每个独立LLM运行RAQ。后者在应用通用RAQ框架之前需要一个额外步骤,即在计算中位数和标准差之前汇总结果。对于RAQ来说,一个关键点是确保独立LLMs或LLMs集合不在我们正在评估的LLMs集合中,否则会引入对该特定模型或模型集合的强烈偏见。 最后,RAQ还可以包括额外指标以提供对LLMs集合的全面比较。例如,我们可以计算每秒字数和平均回答长度,这些指标提供了关于模型性能和冗长度的额外数据点。 RAQ 实战我们首先创建以下提示:我们要求独立的LLM根据答案质量对LLM ID进行比较和排序。 基于正确答案:{Ground Truth Answer},将以下答案的ID从最正确到最不正确进行排序:
ID: 1 答案:{LLM 1 答案}
ID: 2 答案:{LLM 2 答案}
ID: 3 答案:{LLM 3 答案}
...
我们多次运行此过程并记录所有提供的排名。在收集所有问题的排名后,我们执行邓恩多重比较检验[2]。它帮助我们了解所有LLM的排名之间是否存在显著差异,或者它们的表现是否相似。此检验对每个独立组进行成对比较,并告知哪些组在预定义的显著性水平(通常为5%)上统计显著不同。 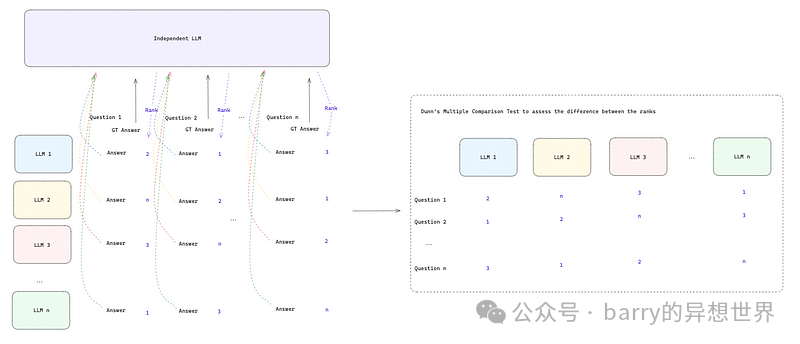
NVIDIA NIM:是什么?NVIDIA NIM [1] 是提供现成 AI 模型推理 API 的容器。它是一种云原生微服务解决方案,旨在简化部署过程并减少时间消耗。它消除了将 AI 模型连接到现有企业基础设施的复杂性。 公司通常通过三种方式部署大型语言模型(LLM):在自己的物理硬件上、在云上或通过第三方托管的 API。前两种选项提供了数据隐私、安全性和模型灵活性等优势。然而,它们需要非常专业的资源以避免效率低下,例如硬件利用不足或应用程序性能问题。另一方面,后者解决了性能问题,但不确保数据隐私、安全性和模型灵活性。它还会成为核心依赖,为系统带来额外风险。 NIM 通过两种方式弥合这些差距。首先,它们提供自己的第三方 API 供您使用。主要区别在于,它们提供社区支持的模型并确保数据隐私和安全。它们仅提供运行这些模型的微服务;因此,与 OpenAI、Anthropic、Google 等案例不同,没有动机使用任何数据进行训练目的。第二种选择是使用 NIM 在您的专用基础设施上部署模型。在这种情况下,NIM 为每个模型和硬件配置提供优化的推理引擎。这意味着 NVIDIA 团队已经在基础设施方面完成了确保低延迟和高吞吐量的关键工作。此外,它提供了灵活性,可以选择其目录中的任何模型并进行最小程度的更改进行部署。最后,这些模型还可以通过 LoRA 进行微调。 以下是介绍如何在您自己的基础设施上从 NIM 目录中启动 LLM 的过程: 安装 Docker(https://docs.docker.com/engine/install/) 安装 NVIDIA Container Toolkit(https://docs.nvidia.com/datacenter/cloud-native/container-toolkit/latest/install-guide.html) 登录 NVIDIAdocker login [nvcr.io](<http://nvcr.io/>) 设置您的 NVIDIA NGC API 密钥export NGC_API_KEY=<your api key> 定义容器名称、镜像名称和下载模型的本地路径。如果您想部署另一个模型,例如 LLaMA 3 70B,只需将IMG_NAME更改为nvcr.io/nim/meta/meta-llama3-70b-instruct:<version>
# 选择一个容器名称用于记录
export CONTAINER_NAME=meta-llama3-8b-instruct
# 从 NGC 选择一个 LLM NIM 镜像
export IMG_NAME="nvcr.io/nim/meta/${CONTAINER_NAME}:1.0.0"
# 选择系统上的一个路径用于缓存下载的模型
export LOCAL_NIM_CACHE=~/.cache/nim
mkdir -p "$LOCAL_NIM_CACHE"
运行以下 docker 命令。
# 启动 LLM NIM
docker run -it --rm --name=$CONTAINER_NAME \
--runtime=nvidia \
--gpus all \
--shm-size=16GB \
-e NGC_API_KEY \
-v "$LOCAL_NIM_CACHE:/opt/nim/.cache" \
-u $(id -u) \
-p 8000:8000 \
$IMG_NAME

一切就绪。我们现在可以向刚刚部署的 LLaMA 3 8B 发送请求。 import requests
from pprint import pp
endpoint = '<http://0.0.0.0:8000/v1/chat/completions>'
headers = {
'accept': 'application/json',
'Content-Type': 'application/json'
}
messages = [
{"role": "user",
"content": "写一条简短的信息解释为什么 AI 很重要。"}
]
data = {
'model': 'meta/llama3-8b-instruct',
'messages': messages,
'max_tokens': 100,
'temperature': 1,
'n': 1,
'stream': False,
'stop': 'string',
'frequency_penalty': 0.0
}
response = requests.post(endpoint, headers=headers, json=data)
pp(response.json())
人工智能(AI)正在改变世界,并有可能显著影响我们的日常生活。通过处理大量数据,AI 可以自动化重复性任务,改善决策制定,并提供个性化体验。它还可以帮助我们应对气候变化、医疗保健和教育等复杂挑战,通过分析模式和识别解决方案。此外,AI 可以提高各行业(从客户服务到交通运输)的生产力、效率和准确性。
行业标准APINIM的另一个有趣之处在于它与流行的LLM包(如LangChain和LlamaIndex)的集成。此外,任何兼容OpenAI API的包都可以通过更改基础URL轻松与NIM集成。 以下示例使用LangChain和OpenAI来提出与之前相同的问题。请注意,我们提供了一个本地主机URL,因为我们正在查询我们刚刚部署的LLaMA 3 8B模型。在这种情况下,我们创建了一个简单的模板,接收问题并将其传递给LLaMA的LLMChain。 from langchain import PromptTemplate
from langchain.chains import LLMChain
from langchain_openai import ChatOpenAI
template = """
Question: {question}
Answer:
"""
prompt = PromptTemplate(
template=template, input_variables=["context", "question"]
)
llm = ChatOpenAI(base_url="<http://localhost:8000/v1>",
model="meta/llama3-8b-instruct",
api_key="not-used",
temperature=0.1,
max_tokens=100,
top_p=1.0)
query_llm = LLMChain(
llm=llm,
prompt=prompt,
)
answer = query_llm.invoke(
{"question": "Write a short message explaining why AI is important."}
)
人工智能(AI)在当今世界至关重要,因为它有可能彻底改变我们的生活方式、工作方式以及彼此之间的互动方式。AI可以自动化重复和琐碎的任务,释放人力资源,专注于更具创造性和战略性的工作。它还可以改善医疗保健结果、提升客户服务和优化业务运营。此外,AI可以通过提供数据驱动的洞察和解决方案,帮助我们应对气候变化、贫困和不平等等复杂的全球挑战。
领域特定模型与HuggingFace类似,NVIDIA API目录非常广泛,涵盖了针对不同领域问题的模型,如语言、语音、视觉和游戏。 本文重点介绍四种可用的语言模型: Mistral vs Meta:Mistral 7B、Mixtral 8x22B、Llama 3 8B 与 70B 的对比本节在遵循 CC BY-SA 4.0 许可的SQuAD问答数据集上测试了四款模型。该阅读理解数据集包含关于一组维基百科文章的问题。根据上下文,模型应能检索出问题的正确答案。对于我们的应用场景,以下三个字段尤为重要: 为了进行评估,我们采用了上述的 RAQ 方法。在此案例中,我们使用 GPT-3.5 作为独立的 LLM,对感兴趣的一系列 LLM 进行排名。它根据标准答案将它们的回答从最好(rank=1)到最差(rank=4)进行排序。 RAQ 应用了一种名为 Dunn 多重比较检验的统计测试,以评估这一系列 LLM 的排名之间是否存在统计学上的显著差异。 最后,RAQ 还比较了每秒字数和平均答案长度,这为模型性能和冗长程度提供了额外的数据点。 我们首先在env/目录下设置一个包含 OpenAI 和 NCG API 密钥的 env 文件: OPENAI_KEY=<YOUR_OPENAI_KEY>
NGC_API_KEY=YOUR_NGC_API_KEY
接着,我们导入所有库,加载 API 密钥,并从 NVIDIA 目录中定义我们要使用的模型。 import os
import matplotlib.pyplot as plt
import pandas as pd
import scikit_posthocs as sp
import seaborn as sns
import utils
from datasets import load_dataset
from dotenv import load_dotenv
from generator import Generator
load_dotenv('env/var.env')
# models
llama8b = Generator(model='meta/llama3-8b-instruct', ngc_key=os.getenv("NGC_API_KEY"))
mistral7b = Generator(model="mistralai/mistral-7b-instruct-v0.3", ngc_key=os.getenv("NGC_API_KEY"))
llama70b = Generator(model="meta/llama3-70b-instruct", ngc_key=os.getenv("NGC_API_KEY"))
mixtral = Generator(model="mistralai/mixtral-8x22b-instruct-v0.1", ngc_key=os.getenv("NGC_API_KEY"))
Generator 类负责加载模型并利用 LangChain 创建提示模板。它在将查询和上下文传递给 LLM 以获取响应之前对其进行格式化。 from langchain import PromptTemplate
from langchain_openai import ChatOpenAI
from langchain.chains import LLMChain
class Generator:
"""Generator, aka LLM, to provide an answer based on some question and context"""
def __init__(self, model: str, ngc_key: str) -> None:
# template
self.template = """
Use the following pieces of context to give a succinct and clear answer to the question at the end:
{context}
Question: {question}
Answer:
"""
# llm
self.llm = ChatOpenAI(
base_url="<https://integrate.api.nvidia.com/v1>",
api_key=ngc_key,
model=model,
temperature=0.1)
# create prompt template
self.prompt = PromptTemplate(
template=self.template, input_variables=["context", "question"]
)
def generate_answer(self, context: str, question: str) -> str:
"""
Get the answer from llm based on context and user's question
Args:
context (str): most similar document retrieved
question (str): user's question
Returns:
str: llm answer
"""
query_llm = LLMChain(
llm=self.llm,
prompt=self.prompt,
llm_kwargs={"max_tokens": 2000},
)
answer = query_llm.invoke(
{"context": context, "question": question}
)
return answer['text']
加载 LLM 后,我们从 HuggingFace 获取 SQuAD 数据集并对其进行洗牌,以确保问题主题的多样性。 squad = load_dataset("squad", split="train")
squad = squad.shuffle()
现在,我们可以在 100 个问题和上下文上应用 RAQ 循环,并记录上述指标。 for i in range(100):
context = squad[i]['context']
query = squad[i]['question']
answer = squad[i]['answers']['text'][0]
# llama 8b
answer_llama, words_per_second, words = utils.get_llm_response(llama8b, context, query)
llama8b_metrics["words_per_second"].append(words_per_second)
llama8b_metrics["words"].append(words)
# mistral 7b
answer_mistral, words_per_second, words = utils.get_llm_response(mistral7b, context, query)
mistral7b_metrics["words_per_second"].append(words_per_second)
mistral7b_metrics["words"].append(words)
# llama 70b
answer_llama70b, words_per_second, words = utils.get_llm_response(llama70b, context, query)
llama70b_metrics["words_per_second"].append(words_per_second)
llama70b_metrics["words"].append(words)
# mixtral
answer_mixtral, words_per_second, words = utils.get_llm_response(mixtral, context, query)
mixtral_metrics["words_per_second"].append(words_per_second)
mixtral_metrics["words"].append(words)
# GPT-3.5 rank
llm_answers_dict = {'llama8b': answer_llama, 'mistral7b': answer_mistral, 'llama70b': answer_llama70b, 'mixtral': answer_mixtral}
rank = utils.get_gpt_rank(answer, llm_answers_dict, os.getenv("OPENAI_API_KEY"))
llama8b_metrics["rank"].append(rank.index('1')+1)
mistral7b_metrics["rank"].append(rank.index('2')+1)
llama70b_metrics["rank"].append(rank.index('3')+1)
mixtral_metrics["rank"].append(rank.index('4')+1)
函数get_llm_response接收已加载的 LLM、上下文和问题,并返回 LLM 的答案以及定量指标。 def get_llm_response(model: Generator, context: str, query: str) -> Tuple[str, int, int]:
"""
Generates an answer from a given LLM based on context and query
returns the answer and the number of words per second and the total number of words
Args:
model (Generator): LLM
context (str): context data
query (str): question
Returns:
Tuple[str, int, int]: answer, words_per_second, words
"""
init_time = time.time()
answer_llm = model.get_answer(context, query)
total_time = time.time()-init_time
words_per_second = len(re.sub("[^a-zA-Z']+", ' ', answer_llm).split())/total_time
words = len(re.sub("[^a-zA-Z']+", ' ', answer_llm).split())
return answer_llm, words_per_second, words
另一方面,函数get_gpt_rank实现了 RAQ 的核心逻辑。它负责接收标准答案和每个 LLM 的答案,并向 GPT-3.5 发送请求,根据正确性对它们进行排名。 def get_gpt_rank(true_answer: str, llm_answers: dict, openai_key: str) -> list:
"""
Implements RAQ core: based on the true answer, it uses GPT-3.5 to rank the answers of the LLMs
Args:
true_answer (str): correct answer
llm_answers (dict): LLM answers
openai_key (str): open ai key
Returns:
list: rank of LLM IDs
"""
# get a formatted output from OpenAI
functions = define_open_ai_function()
gpt_query = f"""Based on the correct answer: {true_answer}, rank the IDs of the following four answers from the most to the least correct one:
ID: 1 Answer: {re.sub("[^a-zA-Z0-9']+", ' ', llm_answers['llama8b'])}
ID: 2 Answer: {re.sub("[^a-zA-Z0-9']+", ' ', llm_answers['mistral7b'])}
ID: 3 Answer: {re.sub("[^a-zA-Z0-9']+", ' ', llm_answers['llama70b'])}
ID: 4 Answer: {re.sub("[^a-zA-Z0-9']+", ' ', llm_answers['mixtral'])}"""
completion = OpenAI(api_key=openai_key).chat.completions.create(
model="gpt-3.5-turbo",
messages=[{"role": "user", "content": gpt_query}],
functions=functions,
function_call={"name": "return_rank"},
)
response_message = completion.choices[0].message.function_call.arguments
rank = ast.literal_eval(response_message)["rank"].split(",")
if len(rank) == 1:
rank = list(rank[0])
return rank
从图 3 可以看出,LLaMA 3 8B 是最快的 LLM,平均每秒产生约 43 个单词。在答案长度方面,Mistral 7B 生成的答案较长,平均答案长度为 24 个单词,明显多于 LLaMA 70B,后者仅生成 8 个单词。最后,根据独立 LLM 的排名,Mistral 7B 的平均排名最佳,约为 2.25,而 LLaMA 3 8B 的表现最差,平均排名约为 2.8。 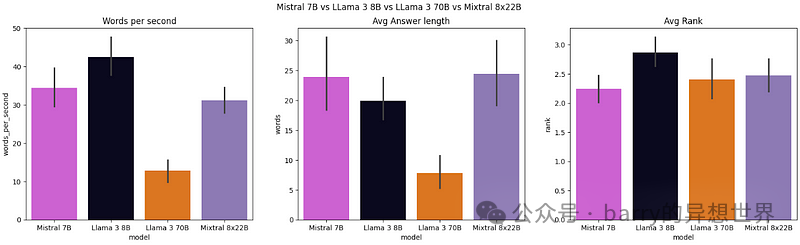
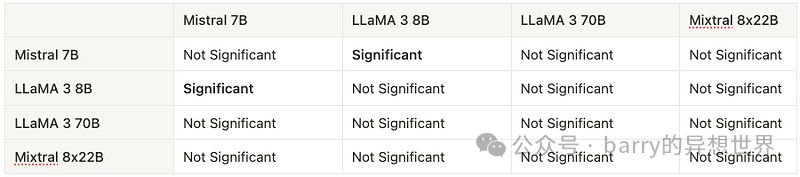
表 2 显示了 Dunn 事后检验的结果,比较了不同语言模型的性能。每个单元格表示相应模型之间的性能差异是否在 5% 显著性水平下具有统计显著性。“显著”表示统计显著性差异(p 值 ≤ 0.05),而“不显著”表示无统计显著性差异(p 值 > 0.05)。 对于选定的显著性水平,Dunn 检验结果显示 Mistral 7B 的性能与 LLaMA 3 8B 有显著差异,但与其他 LLM 无显著差异。增加检验样本量(用于对模型进行排名的示例数量)是提高剩余比较中检测显著差异可能性的策略之一。随着样本量的增加,如果确实存在差异,我们可能会获得更小的 p 值。 p_values = sp.posthoc_dunn([mistral7b_metrics['rank'], llama8b_metrics['rank'], llama70b_metrics['rank'], mixtral_metrics['rank']], p_adjust='holm')
p_values > 0.05
如前所述,RAQ 的优势在于它可以用于评估任何领域/主题/用例上的任何一组 LLM,而不仅仅依赖于传统基准。这意味着,根据所使用的数据集,不同的模型将在此次评估中展现出领导地位。 结论开发更强大的LLM并使其易于访问的快速发展,为采用方面带来了新的挑战。企业正在寻找将它们集成到内外部工具的新方法。然而,当前选择和部署这些模型的方法在控制、隐私、灵活性和安全性之间存在巨大的权衡。 本文介绍了RAQ,一种新颖的框架,用于评估和比较一组LLM的答案质量。它使得为新用例选择LLM变得客观、可扩展和灵活。灵活性源于它可以应用于组织拥有先前私有示例并希望测试一组LLM的情况,即使在没有此类数据集的情况下也能工作。 选定LLM后,我们探讨了NIM作为大规模部署模型的解决方案。它确保了开箱即用的隐私、安全性和可扩展性,无论模型是在物理硬件、私有云还是作为托管服务部署。 我们应用了RAQ并使用NIM来比较Mistral和Meta模型(小版本和大版本)的性能。我们使用了一个阅读理解数据集来说明如何使用RAQ。在我们的设置中,Mistral 7B是最好的模型,生成的答案明显优于LLaMA 3 8B。后者实际上是最快的模型,每秒产生更多的单词。这表明选择模型通常涉及质量和速度之间的权衡。
| 









